1. java.lang패키지
가장 기본이 되는 클래스들(import문 없이도 사용 가능)
1.1 Object 클래스

cf. reflection API : 동적 객체 생성/ 메서드 호출
공변 반환타입(covariant retur type)
오버라이딩할 때 조상 메서드의 반환타입을 자손 클래스의 타입으로 변경을 허용
ex)
public Point clone() { // 반환타입을 Object에서 Point로 변경
Object obj = null;
try {
obj = super.clone();
} catch(CloneNotSupportedException e) {}
return (Point)obj; // Point타입으로 형변환한다.
}: Point copy = (Point)original.clone(); -> Point copy = original.clone()
얕은 복사와 깊은 복사
clone() : 객체의 값을 단순 복제(=얕은 복사) -> 객체가 참조하기 있는 객체까지 복제x
- 얕은 복사 : 단순히 객체에 저장된 값을 그대로 복제하는 것(원본을 변경하면 복사본도 영향을 받는다)
- 깊은 복사 : 원본이 참조하고 있는 객체까지 복제하는 것(원본과 복사본이 서로 다른 객체를 참조 -> 원본의 변경이 복사본에 영향을 미치지 않는다)
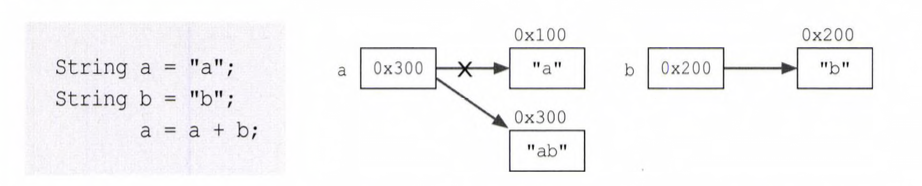
1.2 String 클래스
변경 불가능(immutable)한 클래스
문자열 저장 : char[] value
-> 한번 생성된 String 인스턴스가 갖고 있는 문자열은 읽어 올 수만 있고,변경할 수는 없다.
- '+' 연산자로 문자열을 결합하는 경우
: 인스턴스 내의 문자열이 바뀌는 것이 아니라 새로운 문자열이 담긴 String 인스턴스가 생성되는 것
- 문자열 다루는 작업 :
StringBuffer클래스(문자열 변경 가능)
문자열 리터럴
컴파일시에 클래스 파일에 저장됨(String 인스턴스)
- 한번 생성하면 내용 변경 x -> 하나의 인스턴스를 공유
- 클래스 파일 소스파일에 포함된 모든 리터럴의 목록
String 클래스의 생성자와 메서드
자주 사용되는 메서드목록


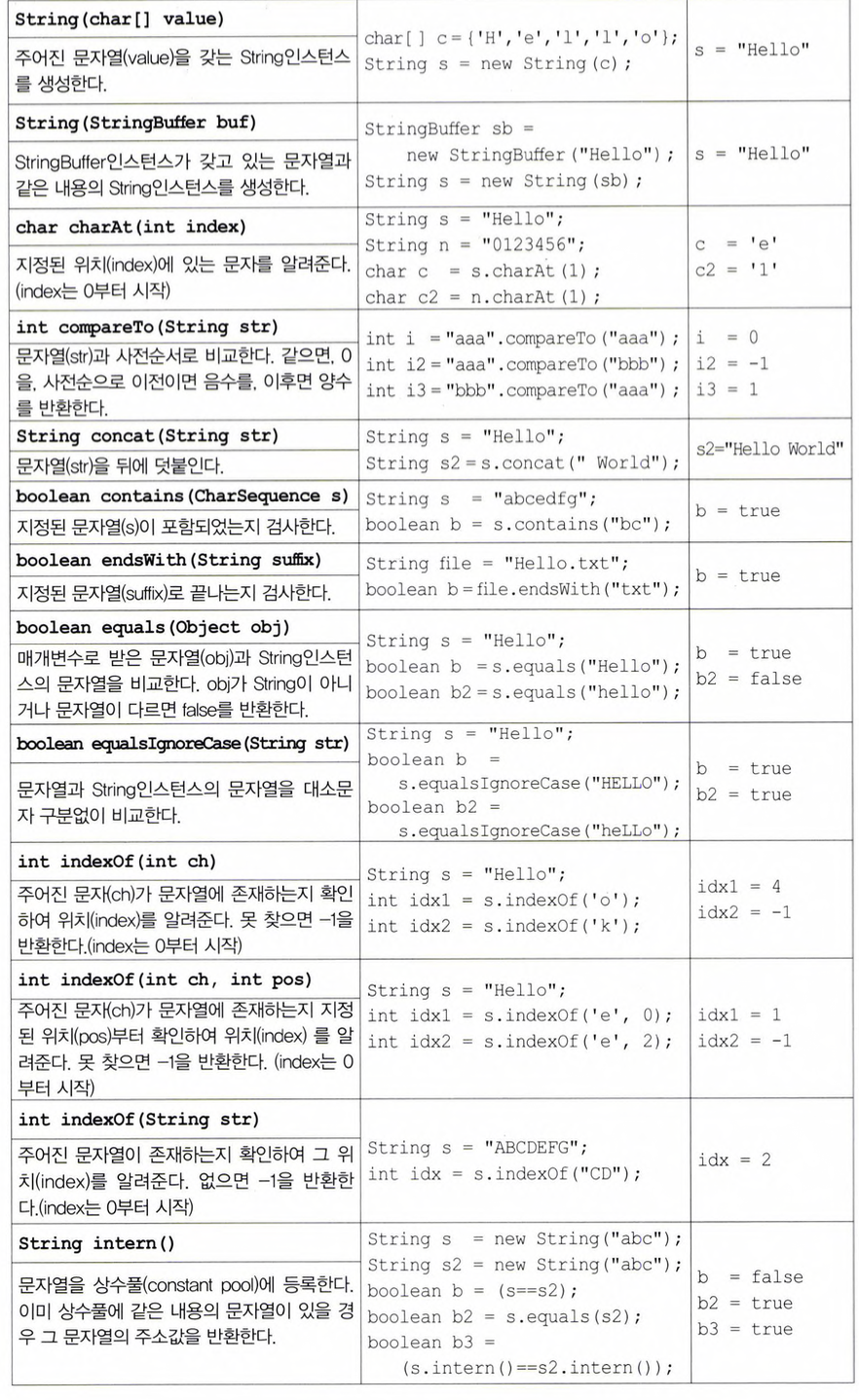
💡parseInt() : 주로 trim()과 함께 쓰임(문자열 양끝의 공백 제거 후 변환)
https://docs.oracle.com/javase/7/docs/api/
문자 관련 메서드들 : 매개변수 타입이 int/char인 이유
- 매개변수의 타입이 char 인 경우 : 보충문자 지원 x
- 매개변수의 타입이 int 인 경우 : 보충문자 지원 o
*보충문자 : 유니코드는 원래 2 byte, 즉 16비트 문자체계인데, 이걸로도 모자라서 20비트로 확장하게 되면서 추가된 문자들 -> 하나의 문자를 char타입으로 다루지 못하고, int타입으로 다룰 수밖에 없다.
1.3 StringBuffer클래스와 StringBuilder클래스
StringBuffer 클래스 메서드들
StringBuilder
StringBuffer : 멀티쓰레드에 안전(thread safe)하도록 동기화 되어 있음
-> 성능이 떨어짐
-> 쓰레드의 동기화만 뺀 것 : StringBuilder(나머지는 동일)
1.4 Math 클래스
- 모두 static 메서드
- 올림, 버림, 반올림, 삼각함수, 지수/로그
- 메서드 이름에
Exact가 포함된 메서드들(addExact,subtractExact...) : 오버플로우 발생시 예외 발생시킴- int addExact(int x, int y)
- int subtractExact(int x, int y)
- int multiplyExact(int x, int y)
- int incrementExact(int a)
- int decrementExact(int a)
- int negateExact(int a)
- int toIntExact(long value)
1.5 래퍼(wrapper) 클래스
기본형 값들을 객체로 다루기 위해 사용

문자열 -> 숫자
new Integer(문자열).intValue(); //floatValue(), longValue(),...Integer.parseInt(문자열);: 주로 이 방법 많이 사용
반환값 : 기본형Integer.valueOf(문자열)
반환값 : 래퍼 클래스 타입
-> 오토박싱 기능 때문에 구별없이 valueOf()사용해도 괜찮음(성능은 조금 느래다
오토박싱(autoboxing) & 언박싱(unboxing)
- 오토박싱: 기본형 값을 래퍼 클래스의 객체로 자동 변환해주는 것
- 기본형과 참조형 간의 형변환도 가능
- 언박싱 : 오토박싱의 반대로 변환하는 것
<-> 기본형과 참조형간의 연산이 불가능 : 래퍼클래스로 기본형을 객체로 만들어 연산 수행
2. 유용한 클래스
2.1 java.utl.Objects클래스
모든 메서드가 static
Object 클래스의 메서드와 이름이 같은 것들은 클래스의 이름을 붙여줘야 함
- 널 체크(null check) :
isNull(),nonNull(),requireNonNull()
void setName(String name) {
this.name = Objects.requireNonNull(name, "name must not be null.");
}- 객체의 비교 :
equals(),deepEquals()equals(): Object 클래스의equals()와 달리 따로 널 검사 필요x, 객체 둘다 null이면 true 리턴deepEquals(): 다차원 배열의 배교 가능(2차원 문자열, ..)
2.2 java.util.Random클래스

💡 자주 사용되는 코드 : 메서드로 만들어 둘 것
- 배열 arr을 from과 to범위의 값들로 채워서 반환한다.
public static int[] fillRand(int[] arr, int from, int to) {
for (int i = 0; i < arr.length; i++)
arr[i] = getRand(from, to);
return arr;
}- 배열 arr을 배열 data에 있는 값들로 채워서 반환한다
public static int[] fillRand(int[] arr, int[] data) {
for (int i = 0; i < arr.length; i++)
arr[i] = data(getRand(0, data.length - 1));
return arr;
}- from과 to범위의 정수(int)값을 반환한다. from과 to 모두 범위에 포함된다.
public static int getRand(int from, int to) {
return (int)(Math.random() * (Math.abs(to - from) + 1)) +
Math.min(from, to);
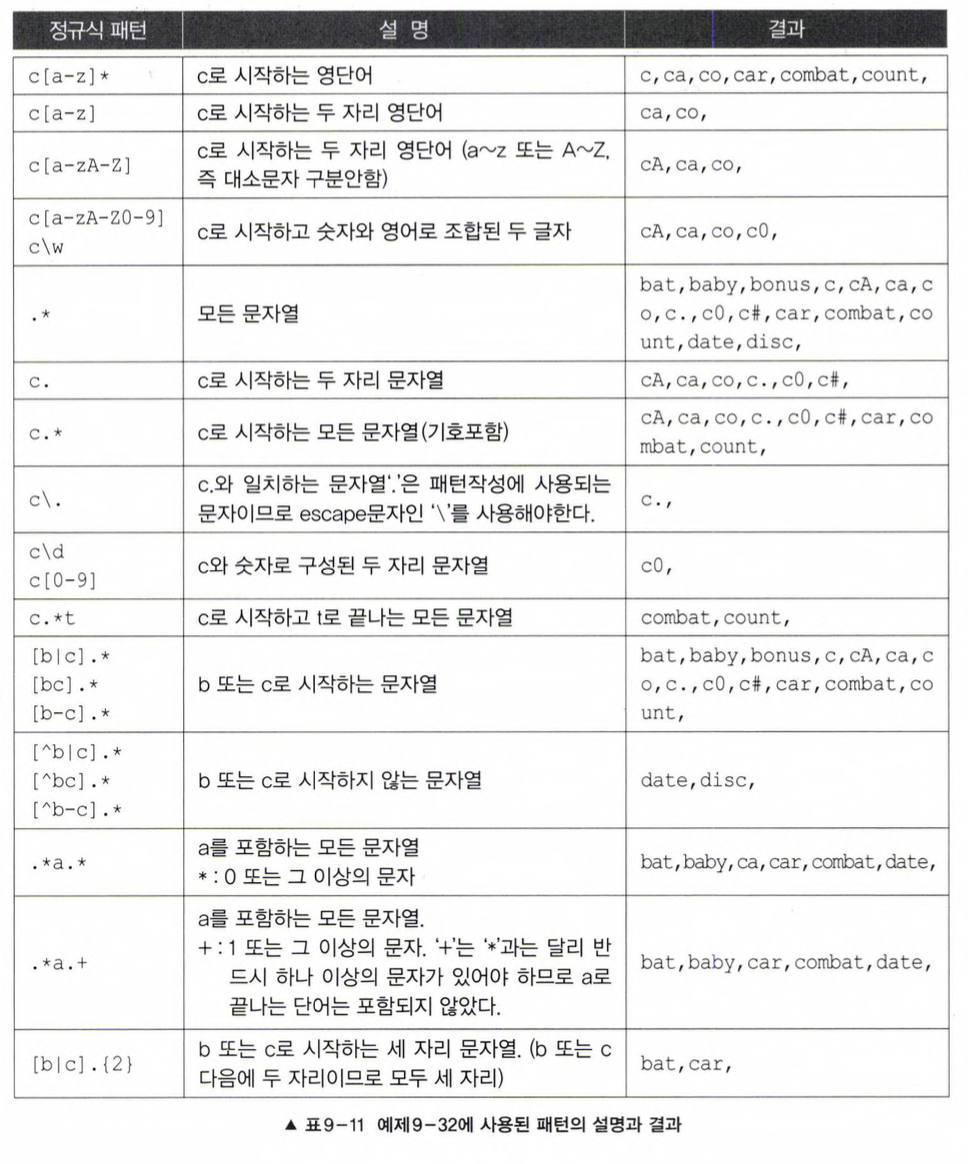
}2.3 정규식(Regular Expression)-java.util.regex패키지
정규식 : 원하는 조건(패턴, pattern)과 일치하는 문자열을 찾아내기 위해 사용하는 것
- 정규식을 매개변수로 Pattern클래스의 static메서드인
Pattern compile(String regex)을 호출하여 Pattern인스턴스를 얻는다.
Pattern p = Pattern.compile("c[a-z]★"); - 정규식으로 비교할 대상을 매개변수로 Pattern클래스의
Matcher matcher (CharSequence input)를 호출해서 Matcher인스턴스를 얻는다.
Matcher m = p.matcher(data[i]); - Matcher인스턴스에 boolean
matches()
를 호출해서 정규식에 부합하는지 확인한다.if(m.matches())

find() : 주어진 소스 내에서 패턴과 일치하는 부분을 찾아내면 true를 반환
- 패턴과 일치하는 부분을 찾아낸 다음 다시 find()를 호출하면 이전에 발견한 패턴과 일치하는 부분의 다음부터 다시 패턴매칭을 시작
-
Matcher의find()로 정규식과 일치하는 부분을 찾으면, 그 위치를start()와end()로 알 아 낼 수 있고appendReplacement(StringBuffer sb, String replacement)를 이용해서 원하는 문자열(replacement)로 치환할 수 있다import java.util.regex.*; // Pattern과 Matcher가 속한 패키지 class RegularEx4 { public static void main(String[] args) { String source = "A broken hand works, but not a broken heart."; String pattern = "broken"; StringBuffer sb = new StringBuffer(); Pattern p = Pattern.compile(pattern); Matcher m = p.matcher(source); System.out.printIn("source: " + source); int i = 0; while (m.find()) { System.out.printIn(++i + "HM OS:" + m.start() + "~" + m.end()); // broken을 drunken으로 치환하여 Sb에 저장한다. m.appendReplacement(sb, "drunken"); } m.appendTail(sb); System.out.printIn("Replacement count : " + i); System.out.printIn("result:" + sb.toString()); } }
2.4 java.util.Scanner클래스
입력을 받기위한 메서드들 : nextInt(), nextLine()...
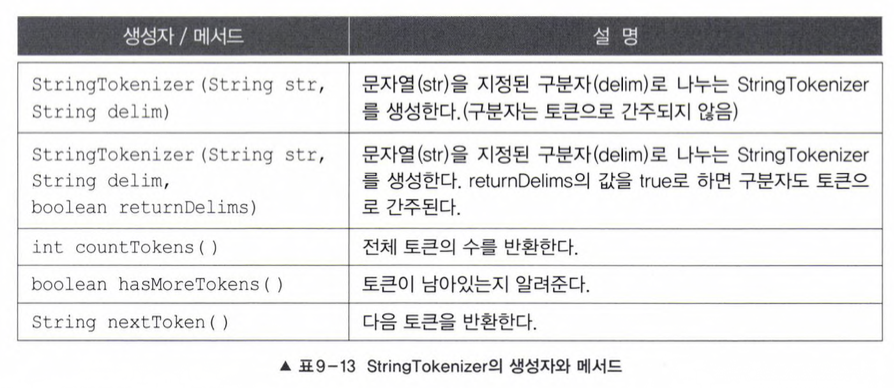
2.5 java.util.StringTokenizer클래스
긴 문자열을 지정된 구분자(delimiter)를 기준으로 여러 개의 문자열(토큰 token)로 잘라내는 데 사용(구분자가 한글자인 경우에만 사용 가능)
String - split(String regex), Scanner - useDelimiter(String patter)
: 같은 용도, 정규식을 사용해야 함
- split() : 빈 문자열도 토큰으로 인식
1001||200|30 - StringTokenizer : 빈 문자열을 토큰으로 인식 x
1001|200|30
import java.util.*;
class StringTokenizerEx2{
public static void main (String[] args) {
String expression = "×=100* (200+300) /2";
StringTokenizer st = new StringTokenizer(expression, "+-*/=()", true); // 구분자 : '+', '-', '*', '/', '=','(', '),
while (st.hasMoreTokens ()) {
System.out.println(st.nextToken());
}
} // main의 끝
2.6 java.math.BigInteger클래스
long 타입 : 약 까지 표현 가능,
그 이상 : BigInteger
- String 처럼 불변(immutable)
- 내부적으로는 값을 배열에 저장, 부호는 따로 저장
👽 생성
Biglnteger val;
val = new Biglnteger ("12345678901234567890"); // 문자열로 생성
val = new Biglnteger(’FFFF", 16); // n진수(radix)의 문자열로 생성
val = Biglnteger.valueOf(1234567890L); // 숫자로 생성👽 다른 타입으로의 변환
String toString() // 문자열로 변환
String toString(int radix) // 지정된 진법 (radix)의 문자열로 변환
byte[] toByteArray() // byte배열로 변환- Number로부터 상속받은 기본형으로 변환하는 메서드들
int intValue()
long longValue()
float floatValue()
double doubleValue()- 오버플로우 발생시 ArithmeticException 발생
byte byteValueExact()int intValueExact()long longValueExact()
- 오버플로우 발생시 ArithmeticException 발생
👽 연산
(1) 사칙 연산
Biglnteger add(Biglnteger val) // this + val
Biglnteger subtract(Biglnteger val) // this - val
Biglnteger multiply(Biglnteger val) // this * val
Biglnteger divide(Biglnteger val) // this / val
Biglnteger remainder(Biglnteger val) // this % val
(2) 비트 연산 : 워낙 큰 숫자를 다루기 위한 클래스이므로, 성능을 향상시키기 위해
- 비트연산자 : and, or, xor, not
- 그 외
int bitCount ()//2진수로 표현했을 때, 1의 개수 (음수는 0의 개수) 를 반환
int bitLength ()//2진수로 표현했을 때, 값을 표현하는데 필요한 bit수
boolean testBit (int n)// 우측에서 n+1번째(n은 0부터 시작) 비트가 10면 true, 00면 false
BigInteger setBit (int n)//우측에서 n+1번째 비트를 1로 변경
BigInteger clearBit (int n)// 우측에서 n+1번째 비트를 0으로 변경
BigInteger flipBit (int n)//우측에서 n+1번째 비트를 전환 (10, 0-1)
2.7 java.math.BigDecimal클래스
BigInteger처럼 불변(immutable)
정수를 이용해서 실수를 표현 :
- 10진 실수 -> 2진 실수 변환에서 발생하는 실수의 오차가 발생 x
👽 생성
BigDecimal val;
val = new BigDecimal ("123. 4567890"); // 문자열로 생성
val = new BigDecimal (123.456); //double타입의 리터럴로 생성
val = new BigDecimal (123456); //int, 1ong타입의 리터럴로 생성가능
val = BigDecimal.value0f (123.456) ; //생성자 대신 valueof (double) 사용
val = BigDecimal.value0f (123456); //생성자 대신 valueof (int) 사용*double 타입의 값을 매개변수로 갖는 생성자는 오차가 발생할 수 있음
System.out.println(new BigDecimal(0.1));// 0.10000000000000000555111...
System.out.println(new BigDecimal("0.1")); // 0.1👽 다른 타입으로의 변환
String toPlainString() //어떤 경우에도 다른 기호없이 숫자로만 표현
String toString () //필요하면 지수형태로 표현할 수도 있음int intValue()
long longValue ()
float floatValue ()
double doubleValue ()byte byteValueExact ()
short shortValueExact()
int intValueExact ()
long longValueExact()
BigInteger toBigIntegerExact()👽 나눗셈
- 어떻게 반올림 처리할 것인가(roundingMode)
- 몇 번째 자리에서 반올림할 것인가(scale)
메서드
BigDecimal divide(BigDecimal divisor)
BigDecimal divide(BigDecimal divisor, int roundingMode)
BigDecimal divide(BigDecimal divisor, RoundingMode roundingMode)
BigDecimal divide(BigDecimal divisor, int scale, int roundingMode)
BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMode)
BigDecimal divide(BigDecimal divisor, MathContext me)*나눗셈한 결과가 무한소수인 경우, 반올림 모드를 지정해주지 않으면 ArithmeticException 발생
👽 java.math.MathContext
반올림모드와 정밀도를 하나로 묶어 놓은 것
- scale을 1줄이기 == 10의 n제곱으로 나누기

I think it is good bike race