1. 프로세스와 쓰레드
프로세스(process) : 실행 중인 프로그램(program)
프로그램 -> 실행 -> OS가 실행에 필요한 메모리 할당 -> 프로세스
프로세스 자원(프로그램 수행에 필요한 데이터, 메모리) + 쓰레드
쓰레드 : 프로세스의 자원을 이용해서 실제로 작업을 수행하는 주체
(모든 프로세스에 1개 이상의 쓰레드 존재)
multi-thread process : 둘 이상의 쓰레드를 가진 프로세스 (자원+쓰레드+쓰레드...)
👽 멀티태스킹, 멀티쓰레드
멀티태스킹 : 여러 프로세스 실행
멀티쓰레드 : 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업 수행
☑️ 프로세스의 성능은 쓰레드의 개수에 비례하지는 않는다
- CPU의 코어(core)는 한번에 하나의 작업만 수행 (-> 동시에 처리되는 작업의 개수 = 코어의 개수)
- 처리해야 하는 코어의 개수 << 쓰레드의 개수
-> 각 코어가 아주 짧은 시간 동안 여러 작업을 번갈아 가며 수행 -> 여러 작업들이 동시에 수행되는 것처럼 보임
👽 멀티쓰레드의 장점
- 하나의 작업을 하는 중에 다른일도 할 수 있다
ex) 파일을 다운로드 받는 중에 카톡 보내기 - 사용자에 대한 응답성이 향상된다
ex) 서버 프로그램은 여러개의 쓰레드 각각이 사용자의 요청을 일대일로 처리
<-> 싱글쓰레드 서버 프로그램 : 요청마다 새로운 프로세스를 생성, 훨씬 더 많은 시간과 메모리 공간 필요
- CPU의 사용률을 향상시킨다.
- 자원을 보다 효율적으로 사용할 수 있다.
- 작업이 분리되어 코드가 간결해진다.
👽 멀티쓰레드의 단점
- 동기화(synchronization) 문제
∵ 여러 쓰레드 같은 프로세스 내에서 자원을 공유하면서 작업 - 교착상태(deadlock) : 두 쓰레드가 자원을 점유한 상태에서 서로 상대편이 점유한 자원을 사용하려고 기다리느라 진행이 멈춰 있는 상태
2. 쓰레드의 구현과 실행
쓰레드를 구현한다 = 쓰레드로 작업할 내용을 run(){ ... }의 몸통에 채운다
- Thread클래스를 상속 : 다른 클래스를 상속받을 수 없음
class MyThread extends Thread {
public void run() { /* 작업내용 */ } // Thread클래스의 run()을 오버라이딩
}-
인스턴스 생성
ThreadEx1_1 t1 = new ThreadEx1_1(); // Thread의 자손 클래스의 인스턴스를 생성 -
메서드 호출 : 조상인 Thread 클래스의 메서드를 직접 호출
String getName(): 쓰레드의 이름 반환
2. Runnable인터페이스를 구현 : 주로 사용
class MyThread implements Runnable (
public void run() { /* 작업내용 */ } // Runnable인터페이스의 run()을 구현
} -
인스턴스 생성
Runnable r = new ThreadEx1_2(); // Runnable을 구현한 클래스의 인스턴스를 생성 Thread t2 = new Thread(r); // 생성자 Thread(Runnable target) Thread t2 = new Thread (new ThreadExl_2 ()); // 위의 두 줄을 한 줄로 간단히 -
메서드 호출 : Thread 클래스의 static 메서드
currentThread()호출 -> 쓰레드에 대한 참조로 메서드 호출)
static Thread currentThread(): 현재 실행중인 쓰레드의 참조를 반환
3. start(), run()
start() : 쓰레드 실행
- OS의 스케줄러가 작성한 스케줄에 의해 쓰레드의 실행순서 결정
- 한 번 실행이 종료된 쓰레드는 재실행 불가
run() : 단순히 클래스에 선언된 메서드 호출(생성된 쓰레드를 실행x)
☑️ start() vs run()
-
start(): 새로운 쓰레드가 작업을 실행하는데 필요한 호출 스택 생성 ->run()이 첫번째로 올라가게 함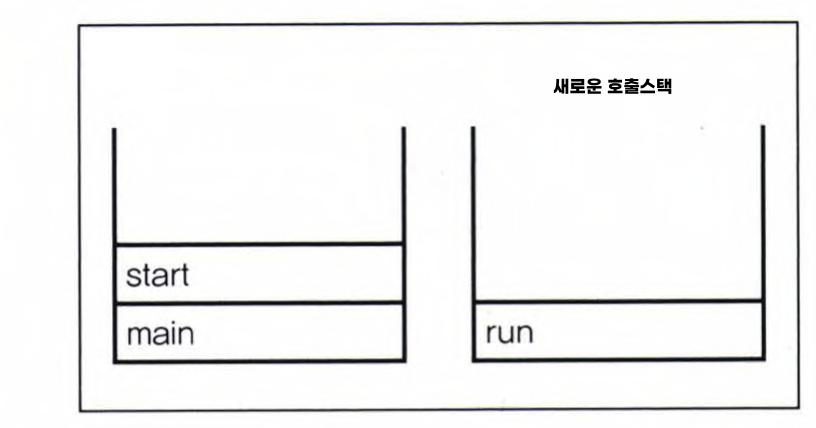
-
run()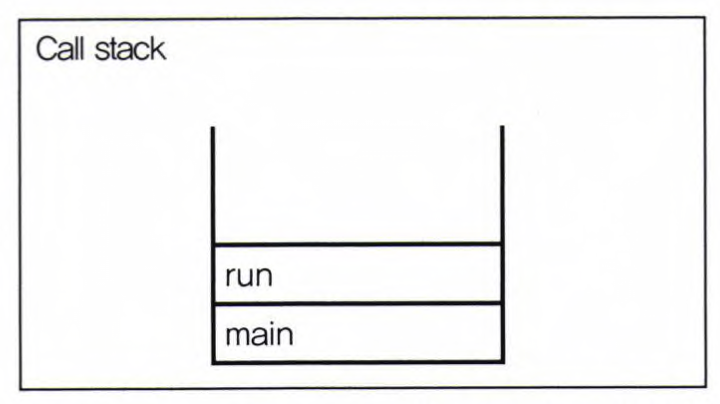
☑️ main 쓰레드 : main 메서드의 작업을 수행
실행 중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다
메인 메서드가 수행을 마쳤더라도 다른 쓰레드가 작업을 마치지 않은 상태라면 프로그램이 종료되지 않는다
4. 싱글쓰레드와 멀티쓰레드
-
싱글코어일 때 싱글쓰레드 & 멀티쓰레드
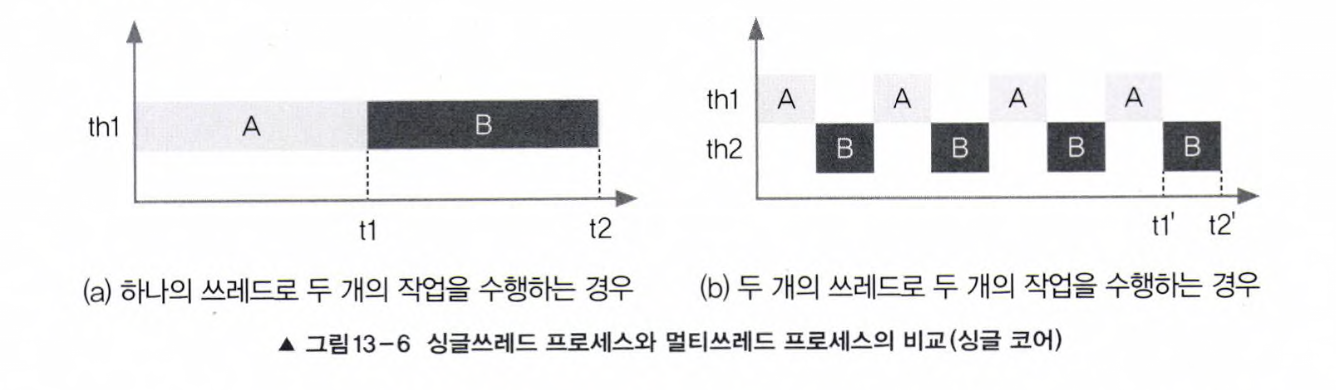
- 멀티쓰레드 : 쓰레드간의 작업 전환(context switching)에 시간이 걸림
- 멀티쓰레드 프로세스 : 각 쓰레드가 서로 다른 자원을 사용하는 작업에 유리
ex) 사용자로부터 데이터 입력받기 + 네트워크로 파일 주고받기 + 프린터로 파일 출력(외부기기와의 입출력)
-
싱글코어 & 멀티코어
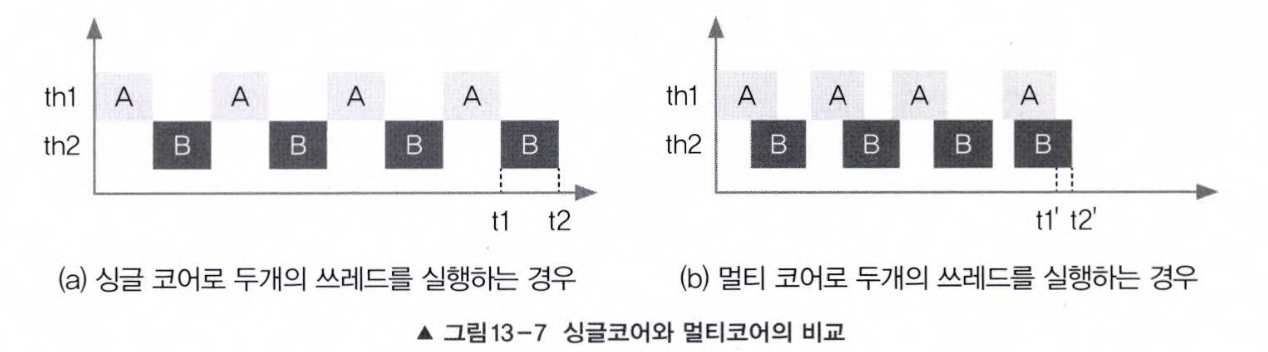 멀티코어 & 멀티쓰레드 : 동시에 두 쓰레드 수행 가능
멀티코어 & 멀티쓰레드 : 동시에 두 쓰레드 수행 가능 -
OS 종속적 : 프로세스/쓰레드 스케줄러가 프로세스/쓰레드 실행 순서/실행 시간을 결정
-> 프로세스/쓰레드에게 할당되는 실행시간이 일정하지 않음
- 병행(concurrent), 병렬(parallel)
- 병행 : 여러 쓰레드가 여러 작업 동시에 진행
- 병렬 : 여러 쓰레드가 하나의 작업을 나눠서 진행
5. 쓰레드의 우선순위
쓰레드의 속성(멤버변수) 중 우선순위의 값에 따라 쓰레드가 얻는 실행시간이 달라짐
- 시각적인 부분 / 사용자에게 빠르게 반응해야하는 작업 : 우선순위가 높아야 함
우선순위 지정과 관련된 메서드/상수
void setPriority(int newPriority) : 쓰레드의 우선순위를 지정한 값으로 변경.
int getPriority() : 쓰레드의 우선순위를 반환
public static finalintMAX_PRIORITY = 10 : 최대우선순위
public static finalintMIN_PRIORITY = 1 : 최소우선순위
public static finalintN0RM_PRI0RITY = 5 : 보통우선순위
- 숫자가 높을수록 우선순위가 높음
- 우선순위는 쓰레드를 생성한 쓰레드로부터 상속받는다 (= 메인 메서드의 우선순위가 5이므로 메인 메서드에서 생성하는 쓰레드의 우선순위는 자동적으로 5)
- 쓰레드 실행 전에만 우선순위를 변경할 수 있음
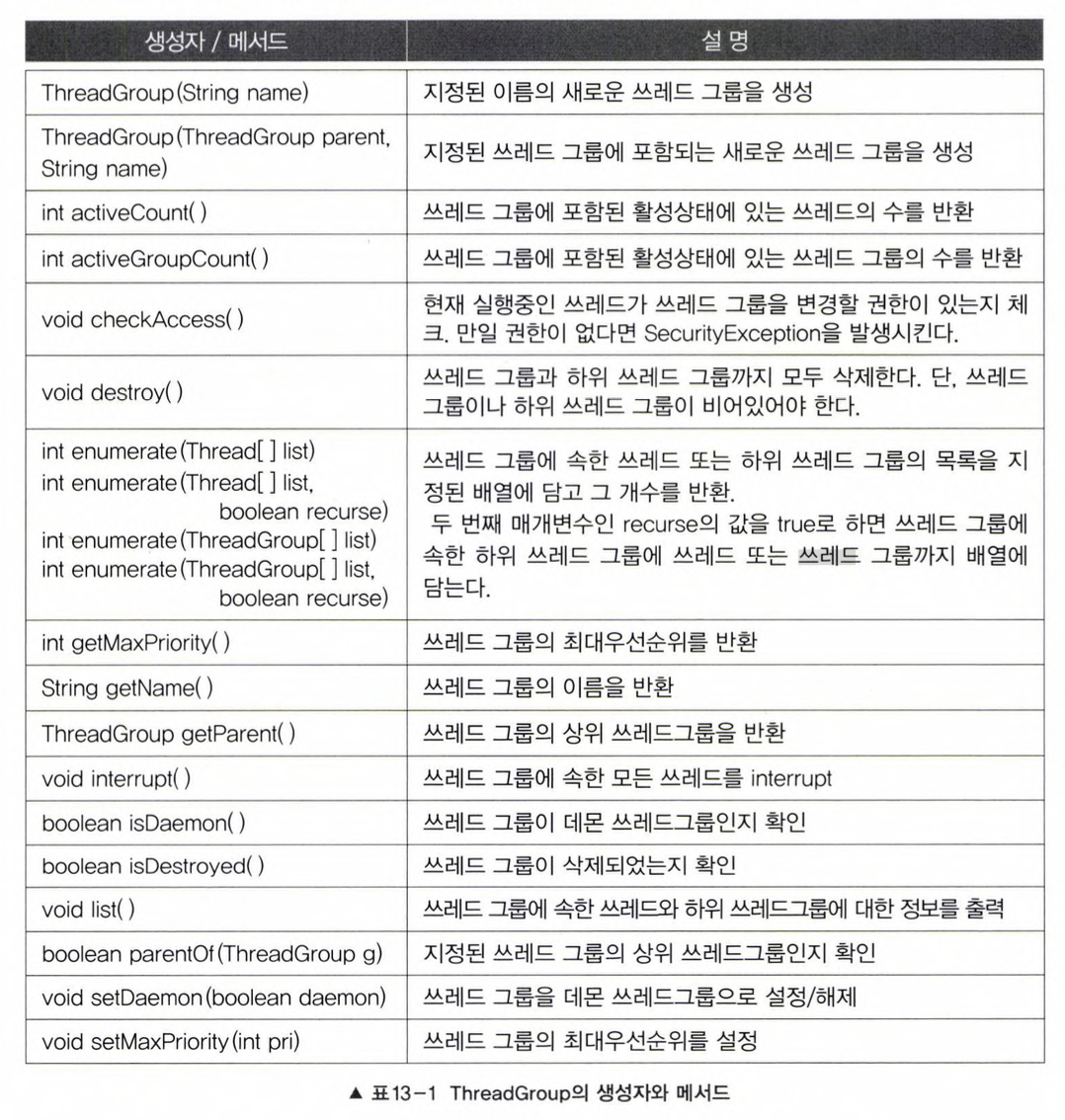
6. 쓰레드 그룹(thread group)
- 쓰레드를 그룹으로 묶어서 관리
- 보안상의 이유로 도입된 개념 -> 자신이 속한/하위 그룹은 변경할 수 있지만 다른 쓰레드 그룹의 쓰레드는 변경x
7. 데몬 쓰레드(daemon thread)
일반 쓰레드(데몬 쓰레드가 아닌 쓰레드)의 작업을 돕는 보조적인 역할을 수행하는 쓰레드
ex) 가비지 컬렉터, 워드프로세서의 자동저장, 화면 자동 갱신 등
- 일반쓰레드의 보조 역할 -> 일반 쓰레드가 종료되면 강제 종료됨
- 데몬쓰레드는 무한루프 / 조건문으로 실행 후 대기 -> 특정 조건이 만족되면 작업을 수행 -> 대기
- 데몬쓰레드가 생성한 쓰레드는 자동적으로 데몬 쓰레드가 됨
8. 쓰레드의 실행제어
👽 쓰레드의 생성~소멸 과정
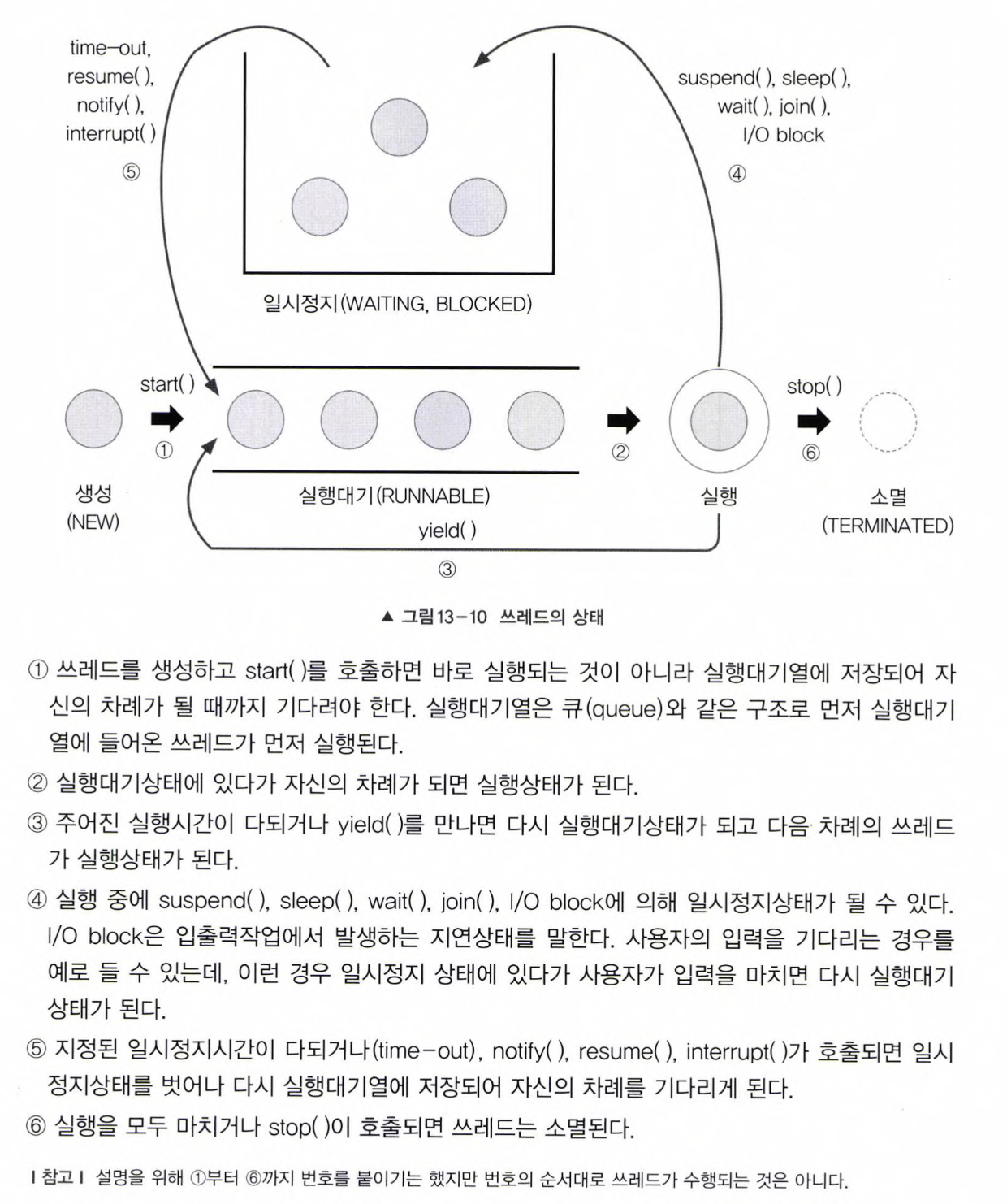
👽 쓰레드 스케줄링과 관련된 메서드
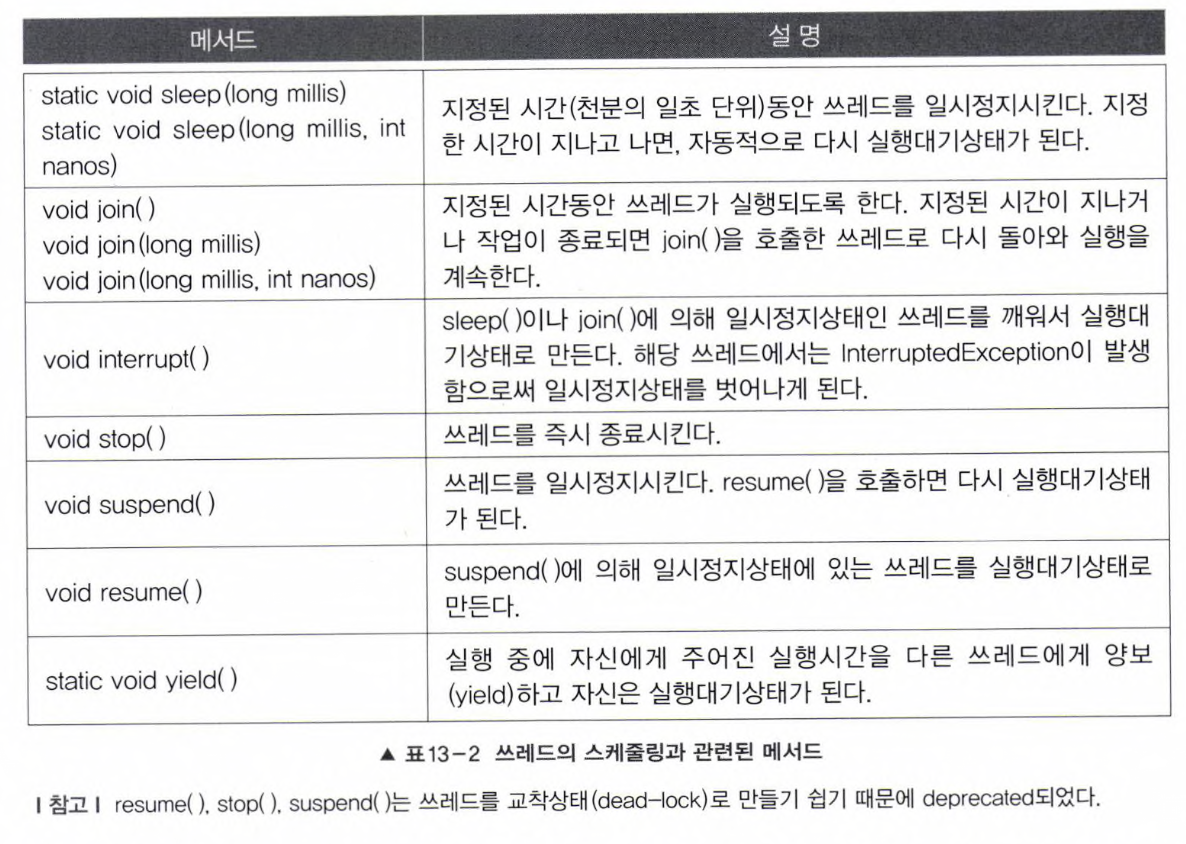
👽 쓰레드의 상태

9. 쓰레드의 동기화
필요성 : 멀티쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유
- 쓰레드 A가 작업하는 도중에 제어권이 B로 넘어가서 A가 작업하던 공유데이터를 B가
임의로 변경하면 의도치 않은 결과가 일어남
=>한 쓰레드가 특정 작업을 끝마치기 전까지 다른 쓰레드에 의해 방해받지 않도록 하는 것 = 쓰레드의 동기화, 이때 필요한 개념 : 임계영역(critical section), 잠금(lock)
9.1 synchronized를 이용한 동기화
- 임계 영역만 설정하면 lock의 획득과 반납이 자동적으로 이루어짐
- 임계 영역은 멀티쓰레드 프로그램의 성능을 좌우 -> 최소화 하는 것이 좋음(synchronized 블럭)
- 모든 객체는 lock을 하나씩 가지고 있으며,해당 객체의 lock을 가지고 있는 쓰레드만 임계 영역의 코드를 수행할 수 있다, 다른 쓰레드들은 lock을 얻을 때까지 기다림

메서드 호출시 해당 메서드가 포함된 객체의 lock 을 얻음 -> 메서드 종료시 lock 반환

- 참조변수 : lock을 걸고자하는 객체를 참조하는 것
- 특정 영역 = synchronized 블럭
9.2 wait(), notify()
synchronized 를 이용한 동기화의 문제점 : 특정 쓰레드가 객체의 랙을 가진채로 기다릴 수 있음
(ex. 은행 - 계좌에 출금할 돈이 부족해서 한 쓰레드가 락을 보유한채로 돈이 입금될 때까지 기다리고 이로 인해 다른 쓰레드들도 원활히 진행되지 않는 상황)
-> wait(), notify()
1.wait() : 동기화된 임계영역의 코드를 수행하다가 작업을 더 이상 진행할 수 없을 때 호출하여 쓰레드가 락을 반납하고 기다림(다른 쓰레드가 락을 얻어 해당 객체에 대한 작업 수행)
2. notify() : 작업을 중단했던 쓰레드가 다시 락을 얻어 작업하도록 함
notifyAll(): 호출된 객체의 waiting pool 에 대기중인 모든 쓰레드를 깨움
👽 특징
- Object에 정의되어 있다.
- 동기화 블록(synchronized 블록)내에서만 사용할 수 있다.
- 보다 효율적인 동기화를 가능하게 한다.
👽 문제점
- 선별적인 통지가 불가능하다 -> 기아(starvation)현상 발생 가능
특정 쓰레드들이 계속 기다리는 현상 ->notifyAll()로 해결하고자 하면 경쟁 상태(race condition) 발생
ex) 식당 - 테이블의 음식이 줄어서 요리사 쓰레드에게 통지하기 위해 notify()를 호출하더라도 손님 쓰레드가 통지를 받을 수 있다. 그 경우 lock을 얻어도 여전히 음식이 없어서 대기한다(waiting pool로 들어감)
-> notifyAll() 호출하면 손님 쓰레드가 대기하더라도 요리사 쓰레드도 결국 lock을 얻기에 기아현상을 방음. 그러나 불필요하게 손님 쓰레드까지 통지를 받아 요리사 쓰레드와 손님 쓰레드가 lock을 얻기 위해 경쟁하게 된다(=경쟁 상태, race condition)
9.3 Lock과 Condition을 이용한 동기화
synchronized 블럭의 '같은 메서드 내에서만 lock을 걸 수 있다'는 제약을 보완한 것
=lock 클래스
👽 lock 클래스의 종류
| 클래스명 | 설명 |
|---|---|
| ReentrantLock | 재진입이 가능한 lock. 가장 일반적인 배타 lock (==wait() & notify()) |
| ReentrantReadWriteLock | 읽기에는 공유적, 쓰기에는 배타적 |
| StampedLock | ReentrantReadWriteLock + 낙관적인 lock |
-
ReentrantLock
특정 조건에서 lock을 풀고 나중에 lock 얻어 임계영역으로 들어와서 작업을 수행하는 방식 -
ReentrantReadWriteLock
- 읽기,쓰기 각각을 위한 lock 제공
- 읽기는 내용을 변경하는 것이 아니라 여러 쓰레드가 읽어도 문제 되지 않음 -> 읽기 lock을 중복해서 걸 수 있음
-
StampedLock
-
lock을 걸거나 해지할 때 스탬프(long타입 정수값) 사용
-
낙관적 읽기 lock : 내용을 읽을 때 항상 lock을 거는 것이 아니라 읽기/쓰기가 충돌할 때만 쓰기가 끝난 후에 읽기 lock을 거는 것
ex)int getBalance () { long stamp = lock.tryOptimisticRead (); // 낙관적 읽기 1ock을 건다. int curBalance = this.balance; // 공유 데이터인 balance를 읽어온다. if (!lock. validate (stamp)) { // 쓰기 lock에 의해 낙관적 읽기 1ock이 풀렸는지 확인 stamp = lock.readLock(); // lock이 풀렸으면, 읽기 lock을 얻기 위해 기다린다. try { curBalance = this. balance; // 공유 데이터를 다시 읽어온다. } finally { lock.unlockRead (stamp); // 읽기 lock을 푼다. } } return curBalance; // 낙관적 읽기 lock이 풀리지 않았으면 곧바로 읽어온 값을 반환 }
-
👽 선별적 통지 : ReentrantLock & Condition
그룹 A, B에 선별적으로 통지하기 위해 각 그룹의 쓰레드를 위한 Condition을 만들어서 각각의 waiting pool에서 따로 기다리도록 한다 -> wait() & notify()대신 await() & signal() 사용
ex) 요리사 & 손님
private ReentrantLock lock = new ReentrantLock(); // lock을 생성
// lock으로 condition을 생성
private Condition forCook = lock.newCondition();
private Condition forCust = lock.newCondition();public void add (String dish){
lock.lock ();
try {
while (dishes.size () >= MAX FOOD) {
String name = Thread.currentThread().getName();
System.out.println(name+" is waiting.");
try {
forCook.await(); // wait(); COOK쓰레드를 기다리게 한다.
} catch (InterruptedException e){}
}
dishes.add(dish);
forCust.signal(); // notify(); 기다리고 있는 CUST를 깨우기 위함.
System.out.println("Dishes:" + dishes.toString ());
} finally {
lock.unlock ();
}
9.4 volatile
👽 (1) 코어의 동작 방식
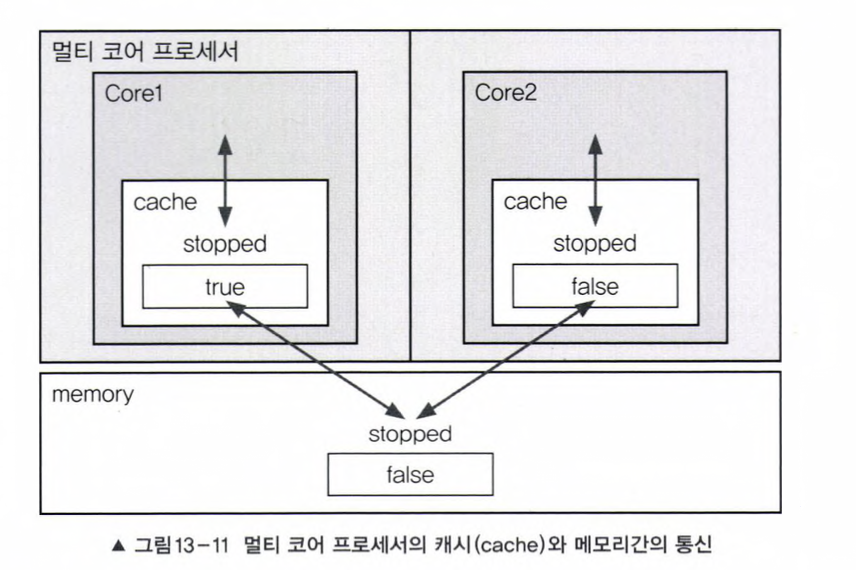
- 메모리에서 읽어온 값을 캐시에 저장하고 캐시에서 값을 읽어서 작업
- 같은 값을 읽어올 때는 캐시에서 먼저 확인 -> 없을 때만 메모리에서 읽어옴
-> 메모리에 저장된 변수의 값이 변경되었는데 캐시에서 갱신되지 않아서 메모리에 저장된 값과 다를 수 있음
-> 해결 방법 : 변수에 volatile을 붙인다 / synchronized 블럭 사용
synchronized 블럭 : 블럭을 들어가고 나올 때 캐시/메모리간에 동기화
👽 (2) long/double을 원자화
JVM의 데이터 처리 단위 = 4byyte (int)
= 데이터를 읽고 쓸 때 하나의 명령어로 가능(다른 쓰레드가 끼어들 틈이 없음)
= long/double은 8 byte로 하나의 명령어로 불가능(다른 쓰레드가 끼어들 여지있음)
-> 변수 선언시에 volatile을 붙임(변수의 원자화)
*volatile : 변수의 읽기/쓰기를 원자화 한 것(동기화)
-> 동기화 필요시 synchronized 블럭 사용(synchronized 블럭 : 여러 문장을 원자화 한 것)
9.5 fork & join 프레임웍
하나의 작업을 여러 단위로 쪼갬 -> 여러 쓰레드가 하나의 작업을 동시에 처리
-
`두 클래스 중에 하나를 상속받아 구현
RecursiveAction: 반환값이 없는 작업을 구현할 때 사용RecursiveTask: 반환값이 있는 작업을 구현할 때 사용
-
추상 메서드
compute()구현 = 처리해야 할 작업 -
쓰레드풀(
ForkJoinPool) 생성 (프레임웍에서 제공)
기본적으로 코어의 개수와 동일한 개수의 쓰레드를 생성해 놓고 반복해서 재사용할 수 있게 함 -
수행할 작업 생성 ->
invoke()로 작업 시작
*작업 훔쳐오기(work stealing)
: 자신의 작업 큐가 비어있는 쓰레드가 다른 쓰레드의 작업 큐에서 작업을 가져와서 수행하는 것 -> 여러 쓰레드가 골고루 작업을 나누어 처리
👽 compute(), fork(), join()
fork() : 작업을 쓰레드의 작업 큐에 넣기
✚
compute() : 작업 큐에 들어간 작업을 더 이상 나눌 수 없을 때까지 나누기
⬇️
각 쓰레드가 골고루 나눠서 처리
join() : 작업의 결과를 얻음
☑️ fork()와 join()의 차이
fork() | join() | |
|---|---|---|
| 역할 | 작업을 쓰레드 풀의 작업 큐에 넣는다 | 작업의 수행이 끝나기를 기다리고 끝나면 그 결과 반환 |
| 종류 | 비동기 메서드 | 동기메서드 |
- 비동기 메서드 : 메서드를 호출하기만 하고 그 결과를 기다리지 않음
