LWP와 Linux Thread
PCB는 담긴 meta data들이 많기 때문에 메모리에서 큰 용량을 차지할 수 있다.
따라서 Parent 에서 Child를 fork() 하는 과정에서 PCB가 복사되고 이때 많은 오버헤드가 발생하는데 이를 줄이기 위해서 PCB 구조체 전체를 복사하는 것이 아닌 포인터를 복사하여 사용하는 방법이 있다.
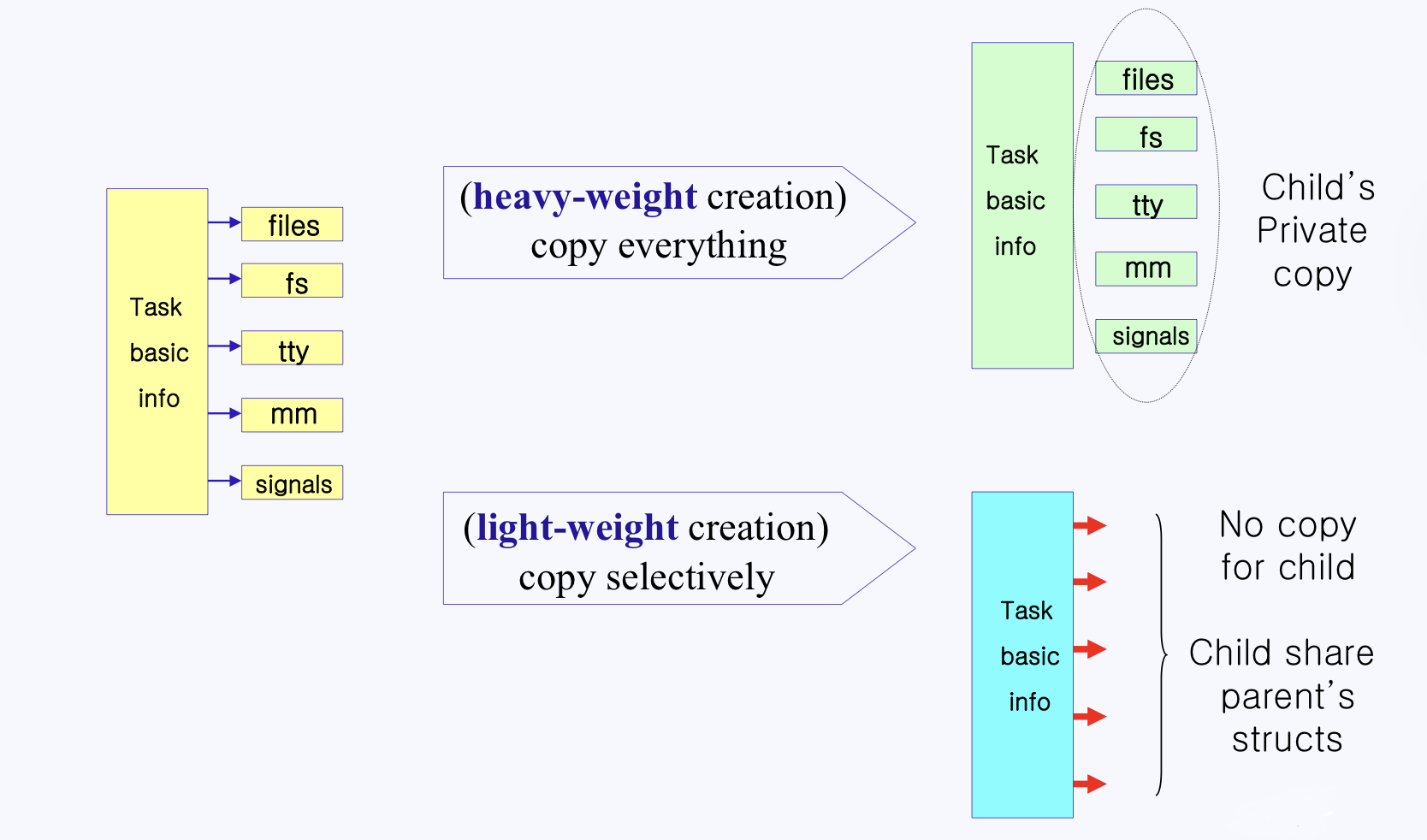
이렇게 되면 Child는 기본적으로 프로세스의 독립적인 공간을 갖는 것이 아닌 Parent의 메모리 공간을 공유하게된다.
fork() 가 아닌 clone()이 그러한 방법이며 clone() 으로 생긴 Child를 Linux 에서는 thread 라고 한다.
정리하면 Linux의 thread는 LWP ( Light-weight-Process ) 프로세스를 경량화 시켜 복사하여 나온 Child 라고 할 수 있다.
여기서 Linux가 아닌 다른 운영체제의 thread 개념과 헷갈릴 수 있는데 그 해답은
light weight process 과 thread 차이질문입니다. - 프로그래밍 - iamroot.org
Copy-on-Write
이전(Unix) Child 생성은 fork()가 일어나게 되면 Parent를 완전히 복사한 상태에서 exec()로 디스크에서 Child의 image를 불러와 덮어 씌우는 과정이었다.
fork()의 복사 시에 Parent의 모든 요소를 복사한 후에 바로 exec() 로 Child를 만들어주는 경우 Parent의 모든 요소를 복사 하는 것은 오버헤드가 클 뿐더러 불필요한 작업일 수 있다.
또한 공유가 가능한 데이터까지 모두 복사하는 것 또한 비효율적이다.
이러한 불필요한 작업을 줄이기 위해서 Linux에서는 fork() 함수에서 CoW라는 기법을 활용한다.
CoW ( Copy-on-Write )는 페이지를 복사하는 것이 아닌 페이지 테이블을 복사하여 Child가 Parent와 같은 영역을 공유하도록 한 상태에서 Write가 발생하면 이때 페이지를 복사하여 쓰는 것이다.
Write가 발생하기 전까지는 Read only로 복사 작업을 지연하고 있다가 Write가 발생하면 기존 페이지를 복사하여 Write 작업을 수행한다.
따라서 모든 페이지를 그대로 복사하는 과정보다 효율적이다.
심화
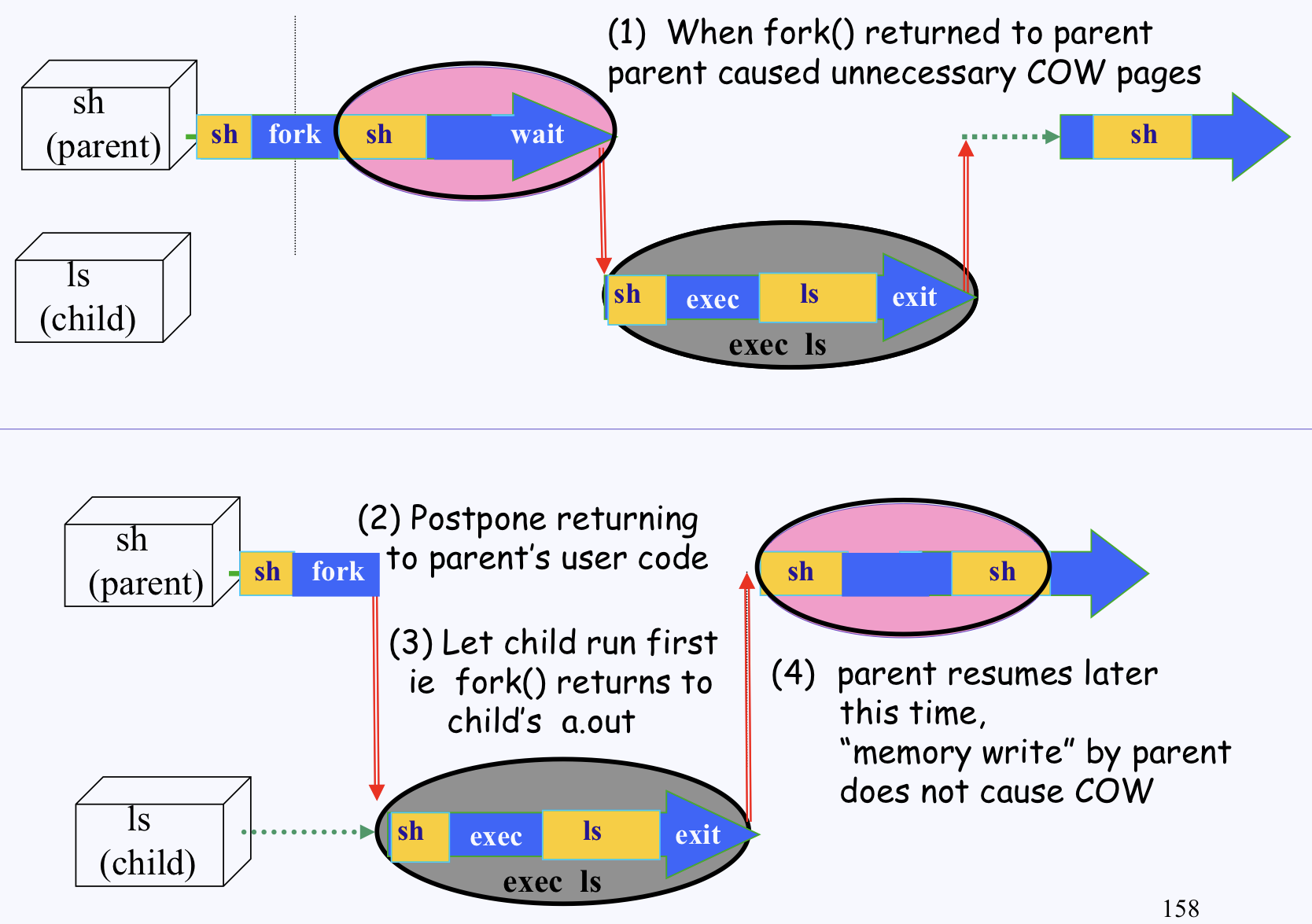
fork()로 Child를 만들고 return한 후에 바로 wait() 으로 Child에게 CPU가 돌아가면 상관없지만
wait() 작업 전에 write 작업을 하게 되면 CoW의 기법상 다른 복사된 페이지를 만들게 된다.
이 과정이 지나고 wait()이 호출되어 Child에게 CPU가 주어지고 exec()를 하게되면 여태 CoW가 이루어졌던 부분들은 Child에게 애초에 필요가 없었기 때문에 불필요한 작업을 수행한 꼴이 되버린다.
따라서 Linux에서는 fork()를 return할 때 ( 사용자 모드로 돌아올 때 ) Child의 우선순위를 높여서 Child가 먼저 CPU를 소유하여 우선적으로 작업을 수행하도록 한다.
이렇게되면 Child가 exec() 작업을 수행한 후에 Parent가 write작업을 수행하므로 불필요한 CoW 작업을 피할 수 있다
Kernel Thread
Kernel 프로세스가 clone() 시스템콜을 호출하여 만들어진 thread
Kernel 영역에서만 존재하며 그 안의 주소 공간을 접근할 수 있다.
몇몇 daemon들이 Kernel Thread 이다.
참고 및 이미지 자료
고건 교수님 강의
https://olc.kr/course/course_online_view.jsp?id=35&cid=51
