
편의상 Clustered index를 CI,Nonclustered index NCI 로 부르겠다.
1. Clustered vs Nonclustered indexes
CI를 만들때 대용량의 데이터가 있는 경우에는 데이터를 모두 정렬해야하기 때문에 많은 시간이 소요된다.CI는 리프페이지가 데이터가 된다. 인덱스 자체에 데이터가 포함- 데이터의 변경이 일어나지 않는다면 검색속도가
CI가 빠르다. CI는 테이블당 하나만 생성가능 (NCI는 여러개 생성가능)NCI는 데이터는 그대로 둔 상태로 별도의 인덱스페이지를 구성한다.
. NCI의 리프페이지는 데이터가 아니라 데이터의 위치값이다.
(데이터의 입력/ 수정/ 삭제의 경우 성능이 우수하다.)
CI(클러스터형 인덱스)
CI는 해당 키 값을 기반으로 테이블이나 뷰의 데이터 행을 정렬하고 저장합니다. 인덱스 정의에 여러 열이 포함됩니다. 데이터 행 자체는 한 가지 순서로만 저장될 수 있으므로 테이블당CI는 하나만 있을 수 있습니다.- 테이블의 데이터 행이 정렬된 순서로 저장될 때만 테이블에
CI가 포함됩니다.CI가 포함된 테이블을CI이라고 합니다. 테이블에CI가 없으면 해당 데이터 행은 힙이라는 정렬되지 않은 _구조로 저장됩니다.
NCI(비클러스터형 인덱스)
NCI의 구조는 데이터 행으로부터 독립적입니다.NCI에는NCI키 값이 있으며 각 키 값 항목에는 해당 키 값이 포함된 데이터 행에 대한 포인터가 있습니다.NCI의 인덱스 행에서 데이터 행으로의 포인터를 행 로케이터라고 합니다. 행 로케이터의 구조는 데이터 페이지가 힙에 저장되는지 아니면 클러스터형 테이블에 저장되는지에 따라 다릅니다. 힙의 경우 행 로케이터는 행에 대한 포인터입니다. 클러스터형 테이블의 경우 행 로케이터는CI키입니다.CI의 리프 수준에 키가 아닌 열을 추가하여 기존 키 제한을 무시하고 완전히 포괄되는 인덱싱된 쿼리를 실행할 수 있습니다. 자세한 내용은 포괄 열을 사용하여 인덱스 만들기를 참조하세요. 인덱스 키 제한에 대한 자세한 내용은 SQL Server의 최대 용량 사양을 참조하세요.
2. CLUSTER 관련 용어
- TABLE SCAN : 데이터 페이지를 처음부터 끝까지 검색하는 방식, 인덱스가 없을 경우에 주로 사용하는 방식
- INDEX SEEK :
NCI에서 데이터를 찾는 방식 - RID LOOKUP :
NCI에서 키를 검색한 후, 실제 데이터 페이지를 찾는다라는 의미 - CLUSTERED INDEX SEEK :
CI에서 데이터를 찾는 방식 - KEY LOOKUP :
NCI에서 키를 검색한 후, 클러스터드 인덱스에서 데이터를 찾는 방식 - CLUSTERED INDEX SCAN :
TABLE SCAN방식과 비슷한 개념으로 전체를 찾아본다는 의미
3. INDEX를 직접 생성하는 방법
CREA [unique] [clustered | nonclustered ] index 인덱스명 on 테이블명 (column [asc | desc])
- PAD_INDEX: 기본값은 OFF, ON으로 설정되면 FILLFACTOR에 페이지 여유분을 설정할 수 있다. OFF으로 설정시에는 페이지에 두개의 로우만 들어갈 수 있도록 남겨두고 모두 채운다.
- FILLFACTOR: 페이지의 여유분을 설정한다.(페이지 분할현상을 방지할 수 있다.)
WITH FILLFACTOR 80 --> 페이지에 20%의 여유분을 두겠다는 의미SQL Server Fill Factor (채우기 비율)에 관한 오해와 진실
- SORT_IN_TEMPDB: 기본값은 OFF, ON설정하면 디스크의 분리효과를 발생시키는 옵션
- ONLINE: 기본값은 OFF, ON 설정시 인덱스 생성중에서 기본 테이블에 쿼리가 가능하도록 하는 옵션
4. INDEX를 변경하는 방법
- REBUILD: 인덱스를 삭제하고 다시 생성하는 옵션
- REORGANIZE: 인덱스를 다시 구성하는 옵션(삭제하지 않고, 즉 조각모음)
ALTER INDEX [인덱스 명 | all ] ON 테이블 명
```sql
ALTER INDEX ALL ON ccc
REBUILD
WITH (ONLINE = ON) 5. INDEX 삭제
PRIMARY KEY,UNIQUE제약조건으로 자동생성된 인덱스는DROP INDEX로 제거할 수 없다. 이경우에는ALTER TABLE구문으로 제약조건을 삭제하면 INDEX가 삭제된다.- 시스템 테이블의 INDEX는 drop index 구문으로 삭제할 수 없다.
- 혼합형 테이블에서 INDEX를 제거할 경우에는
NCI를 제거하는 것이 좋다.
DROP INDEX 테이블명.인덱스명
ALTER TABLE ccc
DROP UK_mix_name;
DROP으로UK_mix_name제약조건을 지운다.
CREATE INDEX idx_name
ON ccc(name)
INSERT ccc VALUES('ao', '홍길동', '서울 용산구');
SELECT *
FROM ccc;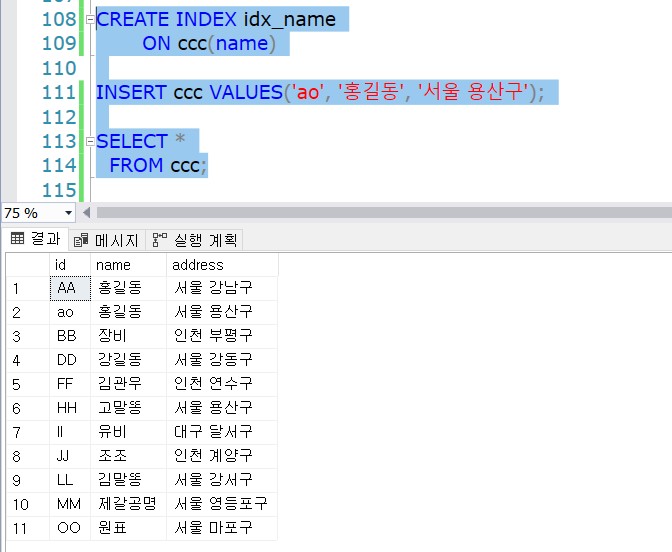
INDEX 생성
DROP INDEX ccc.idx_name;
EXEC SP_HELPINDEX ccc;
INDEX 제거
CREATE UNIQUE INDEX idx_name
ON ccc (name);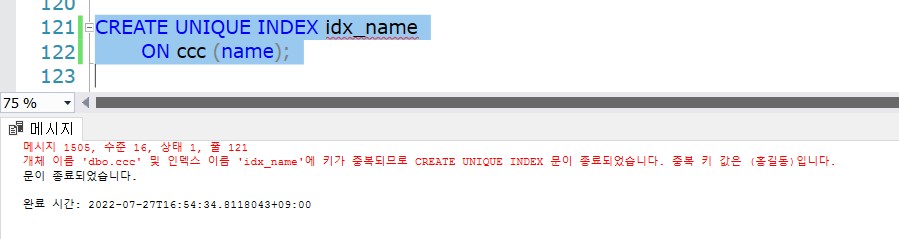
INDEX 생성시
INSERT로홍길동이 중복돼어 오류가 발생한다.
강의: ms sql 2014 제대로 배우기 2
