
안녕하세요! 이번 포스팅이 아마도 자바 프로그래밍 입문 마지막 포스팅이지 않을까 싶습니다.
열흘동안 달려오면서 어려운 개념이 한두개가 아니었는데 그래도 벨로그를 통해 조금씩 정리해가면서 이해가 되어가고 있는 것 같습니다.
이번 포스팅에서 다룰 내용은 Generic, ArrayList, HashMap에 관한 것입니다.
본격적인 내용을 살펴보기 이전에 이전 포스팅에서 정리했던 내용을 잠깐 살펴보겠습니다.
이전 포스팅 복습
추상 클래스 Abstract Class
추상 클래스는 일반적인 클래스와 다르게 내부에 추상 메서드를 가졌습니다.
추상 메서드라 하는 것은 처리를 다루는 내용이 없고 매개변수가 return 값, 즉 prototype만 선언된 메서드가 들어오는 것입니다.
추상 메서드의 형식은 일반적인 메서드의 형식에 abstract를 붙여주는 형태였으며 중괄호 블록은 포함되지 않았습니다.
추상 클래스도 추상 메서드와 마찬가지로 일반적인 클래스의 형식에 abstract를 선언하여 추상 클래스임을 나타내 주었습니다.
public abstract class AbstractClass {
private String name;
public abstract void abstractMethod();
}부모클래스로서 상속관계를 가질 수 있고 내부에 선언된 메서드는 오버라이딩해서 재정의할 수 있습니다.
그리고 추상 클래스는 상속을 통해서만 사용해야하기 때문에 객체로서 생성할 수 없습니다.
인터페이스 Interface
인터페이스는 추상클래스와 비슷한 개념이지만 다소 다릅니다.
인터페이스는 추상 메서드만을 포함하고, 추상 클래스처럼 멤버변수나 일반 메서드를 가질 수 없습니다.
인터페이스를 추상클래스와 비교했을 때 각각은 빈깡통과 기본적인 것만 들어있는 깡통으로 비교를 할 수가 있겠죠?
인터페이스를 부모객체로 두면 자식객체는 상속받은 인터페이스 내부의 추상 메서드를 오버라이딩해서 사용할 수 있습니다.
중요한 사항으로 클래스간의 상속은 extends 키워드로 상속관계가 만들어지지만 인터페이스를 상속 받기 위해서는 implements라는 키워드를 사용했죠
package cls;
import inter.YouInterface;
public class YouClass implements YouInterface {
@Override
public void func() {
System.out.println("YouClass func()");
}
}또 다른 특징으로 인터페이스는 다중상속이 가능하다는 점이 있었습니다!! 꼭 기억해두세요!
정적변수 static과 상수 final
우선 변수의 종류에는 멤버변수, 매개변수, 지역변수, 전역변수, 정적변수가 있었습니다.
각각의 특징중에 가장 중요한 사실은 멤버변수와 정적변수는 선언해주는 것만으로도 초기화가 된다는 것이었고, 지역변수는 직접 초기화를 해줘야 했습니다.
정적 변수(그리고 정적 메서드, 정적 함수)는 static이라는 키워드를 동반하는데 이는 정적 메서드, 정적 함수를 호출해줄 때 인스턴스가 없는 채로 호출이 가능했었죠.
final은 상수의 개념이었습니다. 상수라는 것은 바뀌지 않을 숫자를 말하는 것으로, 일반 변수와는 다릅니다.
변수는 한번 선언해주고 값을 마음대로 바꿔서 사용할 수 있지만 상수는 고정된 값이었죠.
한 가지 더 말씀 드리면 final로 선언해준 상수의 이름은 대문자로 써주면 더 좋습니다.
자 여기까지 복습 마치고 본격적인 내용 살펴보도록 하겠습니다.
Generic
기본 개념
Generic은 제네릭이라고 합니다. 제네릭은 같은 클래스에서 다양한 자료형을 사용하고 싶은 경우에 설정하는 요소 입니다.
왜 제네릭을 사용해야 할까요?
제네렉 타입을 이용함으로써 잘못된 타입이 사용될 수 있는 문제를 컴파일 과정에서 제거할 수 있게 되었다. (중략) 제네릭은 클래스와 인터페이스 그리고 메서드를 정의할 때 타입을 파라미터로 사용할 수 있도록 한다. 타입 파라미터는 코드 작성 시 구체적인 타입으로 대체되어 다양한 코드를 생성하도록 해준다.
이것이 자바다(신용권), 654
그리고 제네릭을 사용하여 코드를 작성할 때 얻을 수 있는 또 다른 이점은 컴파일 할 때 타입 체크가 가능하다는 점, 타입변환(캐스팅)을 제거한다는 점입니다.
자바 컴파일러는 코드에서 잘못 사용된 타입에 의해 발생할 수 있는 문제점을 제거하고자 제네릭 코드에 대해 엄격한 타입체크를 합니다. 실행할 때 에러가 발생하는 것보다 컴파일 할 때 미리 에러를 보여주고 개발자에게 수정하도록 하는 것이 좋겠죠?
제네릭 코드를 사용하지 않고 프로그램을 작성했을 때 불필요한 타입변환이 이루어지기 때문에 프로그램 성능이 저하될 수 있습니다.
제네릭 타입이란?
제네릭 타입은 타입을 파라미터로 가지는 클래스와 인터페이스를 말합니다. 클래스나 인터페이스 뒤에 <>가 붙고, 이 안에 들어가는 타입 파라미터는 일반적으로는 알파벳 대문자 한 글자로 표기합니다.
변수명과 동일한 규칙에 따라서도 작성할 수 있습니다.
public class Main {
public static void main(String[] args) {
Box box = new Box();
box.set("홍길동"); // String ==> Object
String name = (String)box.get(); // Object ==> String
}
}
public class Box {
private Object obj;
public void set(Object obj) { this.obj = obj; }
public Object get () { return obj; }
}
public class Apple{ }위와 같이 타입을 자주 바꾸게되면 프로그램 성능에 좋지 못한 영향을 끼칩니다. 그래서 모든 종류의 객체를 저장하고 타입의 변환이 발생하지 않도록 하는 방법을 생각해야겠죠?
그래서 나온 것이 제네릭입니다.
그러면 우리가 앞에서 예를 들었던 Box클래스는 조금 바꿔보겠습니다.
public class Box<T> {
private T t;
public T get() { return t; }
public void set (T t) { this.t = t; }
}자세히 보시면 타입 파라미터 T를 활용해서 객체타입(Object 타입)을 모두 T로 대체 해줬습니다.
그래서 T라고 하는 것은 Box 클래스로 객체를 생성할 때 구체적 타입으로 변경을 시켜주죠.
메인 함수에서 Box 객체를 다시 만들어보겠습니다.
Box<String> box = new Box<String>();이런 모양이 되겠죠?
정수타입을 담는 Box 객체를 만들어보겠습니다.
Box<Integer> box = new Box<Integer>();이번에는 별도의 클래스가 필요합니다. 작성해보겠습니다.
class Box<T> {
T temp;
public Box(T temp) {
this.temp = temp;
}
public T getTemp() {
return temp;
}
public void setTemp(T temp) {
this.temp = temp;
}
}자 그다음으로 객체 내부에 들어갈 값을 변경해보겠습니다.
Box<Integer> box = new Box<Integer>(111); // 111이 객체에 생성됨
box.setTemp(234); // setter함수로 값을 조정해버렸음그 다음으로 Integer가 아니라 String을 받아와보겠습니다.
Box<String> sbox = new Box<String>("Hello");
sbox.setTemp("World");
System.out.println(sbox.getTemp());마찬가지로 객체를 생성할 때 초기에 넣어준 값 "Hello"가 setter 함수에 의해서 변환되었습니다.
중요한 사실은 제네릭 타입에 일반 자료형은 사용할 수가 없습니다.
또 다른 클래스를 하나 만들어줍시다. 이번에는 BoxMap이라는 클래스입니다.
타입 파라미터는 꼭 한개가 아니라 두개 이상의 멀티 타입 파라미터로도 쓸 수 있습니다. 이 경우에는 각각의 타입 파라미터를 쉼표로 구분하고 객체 안에 각각의 생성자와 getter(), setter()가 필요합니다.
이 클래스의 타입 파라미터는 KEY, VALUE로 하고, 내부에서 KEY는 key,VALUE는 value로 멤버변수를 만들어주고 생성자 만들어주고 각 매변수의 getter와 setter를 작성해 보세요.
class BoxMap<KEY, VALUE> {
private KEY key;
private VALUE value;
public BoxMap(KEY key, VALUE value) {
this.key = key;
this.value = value;
}
public KEY getKey() {
return key;
}
public void setKey(KEY key) {
this.key = key;
}
public VALUE getValue() {
return value;
}
public void setValue(VALUE value) {
this.value = value;
}
}각 타입 파라미터
E - Element
K - Key
N - Number
T - Type
V - Value
R - ReturnType컬렉션
기본 개념
컬렉션은 객체를 추가, 검색, 삭제하는데 효율성을 도모하기 위한 것입니다.
이제까지 우리가 어떤 많은 양의 정보들을 담아두었다가 꺼내 쓰고 싶을 때, 우리는 배열에 그 정보들을 저장해왔습니다. 생성하기도 쉽고 꺼내오기도 쉽죠. 그런데 한 가지 문제점은 자바의 배열은 생성하면서 크기가 결정되기 때문에 나중에 다른 것을 추가로 넣고 싶어도 그렇게 할 수가 없습니다..
그러면 배열의 크기를 엄청크게 만들어두면 되지 않나라고 반문할 수 있는데 그렇게 하게 되면 배열에 들어있는 일부 객체를 삭제했을 때 배열에 빈자리가 많아져서 효율적이라고 할 수는 없습니다.
이러한 문제점을 해결하기 위해 자바는 객체들을 효율적으로 추가, 삭제, 검색(CRUD)할 수 있도록 컬렉션이라는 기능을 만들었고 다음과 같은 구조를 가집니다.
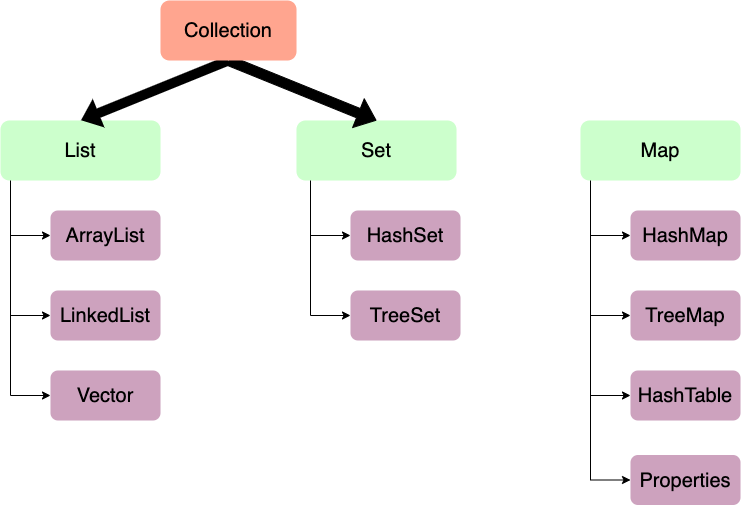
한 가지 중요한 사실은 그림에서 표기한 화살표는 상속관계를 나타냅니다.
List는 인터페이스이고, ArrayList와 LinkedList 는 인터페이스의 상속을 받은 클래스입니다.
이 포스팅에서 다룰것은 List의 ArrayList와 LinkedList 그리고 Map의 HashMap과 TreeMap입니다.
리스트 List
리스트는 목록을 나타내는 뜻이죠. 자바에서 리스트라고 하는 것은 배열과 비슷하지만 배열보다 편리한 기능을 많이 가지고 있는 자료형입니다.
리스트와 배열의 가장 큰 차이점은 바로 길이차이입니다. 배열은 길이가 정해져있고 동적할당을 할 수 있습니다. 그에 반해 리스트는 길이가 따로 존재하지 않고 동적으로 변합니다.

이렇게 List 컬렉션은 객체를 일렬로 늘어놓은 모양인데 객체관리를 인덱스로 하기 때문에 리스트 내부에 객체를 넣어주면 자동으로 인덱스 넘버를 갖게 되고 인덱스 넘버를 활용해서 객체를 검색, 삭제할 수 있도록 해줍니다.
여기에 들어가는 객체들은 리스트안에 객체 자체가 저장되는 것이 아니라 인덱스 넘버만 참조하기 때문에 한 자리에 또 다른 객체를 넣어줄 수 있습니다.
리스트는 순서를 유지하고 저장하는 기능을 갖습니다. List의 구현 클래스는 ArrayList, LinkedList, Vector가 있는데, 이 포스팅에서는 ArrayList와 LinkedList만 다룰 것입니다.
ArrayList
ArrayList는 배열처럼 사용할 수 있는 목록을 말합니다. 선형 구조를 가집니다.
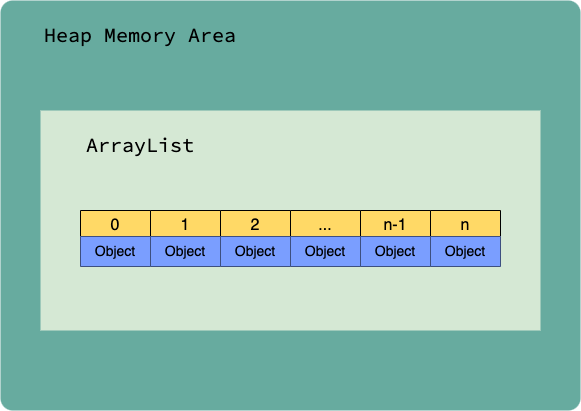
ArrayList는 배열처럼 인덱스로 객체를 관리하지만 배열과의 가장 큰 차이점은 배열은 생성시 크기가 고정되어 사용을 하면서 크기를 변경할 수는 없습니다.
그러나 ArrayList는 저장할 수 있는 용량을 초과하는 객체가 들어오게 되면 그에 맞게 자동적으로 용량을 늘여서 확보합니다.
생성 방법
생성하는 방법은 다음과 같습니다.
ArrayList<Integer> arrList = new ArrayList<Integer>(); // class로 객체 생성
List<Integer> arrList = new ArrayList<Integer>(); // 인터페이스를 인스턴스로 객체 생성CRUD - 추가
이를 바탕으로 우리가 CRUD(Create, Read, Update, Delete)를 직접 구현해보겠습니다.
우선은 리스트에 값을 하나 넣어보겠습니다.
List<Integer> arrList = new ArrayList<Integer>();
arrList.add(111);이렇게 add() 메서드를 사용하는데, 괄호안에 넣어준 값이 리스트에 들어갑니다.
저렇게 메서드에 직접 입력해서 값을 넣어주는 방법이 있고, 객체를 생성해서 넣어주는 방법이 있습니다.
List<Integer> arrList = new ArrayList<Integer>();
Integer in = new Integer(111);
// 또는
Integer in = 111 // 위의 객체 생성 식을 간단히 입력한 형태
// 또는
arrList.add(new Integer(111));리스트의 길이를 확인하는 메서드
그럼 리스트의 길이는 어떻게 확인할 수 있을까요?
우리가 배열에서는 length라는 것을 사용해서 배열의 길이를 알 수 있었습니다.
리스트에서는 size메서드로 리스트의 길이를 알 수 있습니다.
리스트 안에 객체를 몇개 넣어주고 길이를 알아보겠습니다.
List<Integer> arrList = new ArrayList<Integer>();
arrList.add(new Integer(111));
Integer in = 222;
arrList.add(in);
Interger it = 333;
arrList.add(it);
/* 이 때 arrList의 길이는? */이럴 때 우리가 size 메서드를 사용할 수 있습니다.
List<Integer> arrList = new ArrayList<Integer>();
arrList.add(new Integer(111));
Integer in = 222;
arrList.add(in);
Interger it = 333;
arrList.add(it);
/* 이 때 arrList의 길이는? */
int len = arrList.size(); // 길이를 재서 변수 len에 담음
System.out.println(len); // 3 [0, 1, 2]리스트의 길이는 3이지만 우리는 리스트의 인덱스가 배열과 동일하게 0부터 시작한다는 점을 잊어서는 안됩니다.
CRUD - 가져오기
그다음으로 리스트의 특정 인덱스(n번째)에 있는 값을 가져올 수 있습니다.
가령 리스트 내부의 값들이 아래와 같다고 가정해봅시다.
arrList[0] = 111;
arrList[1] = 222;
arrList[2] = 333;
arrList[3] = 444;2번 인덱스의 값을 가져와 달라고 요청을 받는다면 우리는 어떻게 가져올 수 있을까요?
배열의 경우에는 직접 배열 변수명과 인덱스 넘버를 직접 선언해서 값을 가져올 수 있었는데, 리스트는 그렇게 할 수가 없습니다.
예를 들어서
System.out.println(arrList[2]); 이와 같이 작성하면 에러가 발생하기 때문에 메서드를 활용해야합니다.
그래서 특정 인덱스의 값을 가져올 수 있는 메서드는 get()입니다.
다시 말해서 아래와 같이 작성했을 때 우리가 리스트의 특정 인덱스에 위치한 객체의 값을 가져올 수 있다는 것이죠.
System.out.println(arrList.get(2)); 그러면 반대로 리스트 안에 있는 객체들을 전부 꺼내오려면 어떻게 해야할까요?
배열과 마찬가지로 for문을 써서 가져올 수 있습니다.
for (int i = 0; i < arrList.size(); i++) {
System.out.println(arrList.get(i));
}배열에서 다루는 for문과 약간 다르죠? 리스트의 길이는 size메서드로 나타내주었고 각 요소들은 get메서드를 사용해서 i번째 있는 것들을 가져오라고 작성해 주었습니다.
CRUD - 삭제
이제 우리는 리스트 안에 있는 객체들 중에 i번째 있는 것을 삭제하려고 한다고 가정할 때, 어떻게 삭제를 해 줄 수 있을까요?
배열은 이미 범위가 고정되어 있기 때문에 값을 삭제하는 것은 적절치 않았습니다.
그렇지만 리스트는 범위가 한정되어있지 않기 때문에 내부에 있는 객체의 삭제가 필요하다면 삭제를 해줄 수도 있죠.
이 때 사용하는 메서드는 remove()입니다. remove()는 삭제와 동시에 지워주는 데이터를 리턴해줍니다.
자세하게 살펴보기 위해서 앞에서 예를 들었던 arrList를 계속 참조하겠습니다.
Integer num = arrList.remove(2);이렇게 해주면 arrList에서 삭제된 값이 num이라는 이름의 정수 객체에 반환되어 저장됩니다.
만약에 자료형을 int라고 쓰면 안되겠죠? 객체를 받아오는 거니까...
remove() 괄호 안에 들어가는 숫자는 인덱스 넘버입니다.
정상적으로 삭제되었는지 확인하기 위해서 리스트의 각 객체들을 보여주는 코드를 작성해 보겠습니다. 저는 for each문으로 작성해주겠습니다.
for (Integer number : arrList) {
System.out.println(number);
}ArrayList에서 어떤 인덱스에 있는 객체를 삭제하게 되면 그 객체가 삭제됨과 동시에 원래 그 뒤에 있던 객체들의 인덱스는 -1씩 앞으로 당겨져오게 됩니다.
원하는 위치에 객체 추가하기(현재 있는 데이터 사이에 끼워넣기)
리스트는 배열과 다르게 어떤 객체가 원래 있던 객체 사이를 헤집고 들어갈 수 있습니다.
우리가 배열에 어떤 원소를 넣어준다고 했을 때는 반복문 사용해서 인덱스값을 증가시키며 원소들을 집어넣어줬는데, 리스트에서는 add 메서드를 확장해서 파라미터를 두개 받으면 앞에 들어오는 파라미터는 인덱스, 두번째 들어오는 파라미터는 첫번째에 입력한 인덱스에 넣을 값으로 해서 현재 있는 객체 사이에 밀어 넣을 수 있습니다.
arrList.add(1, 200);이렇게 사용을 해주면 원래 1번째에 있던 객체는 뒤로 밀려납니다.
원래 1번째에 222라는 숫자가 있었다면 add메서드의 영향으로 200이 1번째 자리로 들어가고 기존의 222부터는 자신이 원래 참조하던 인덱스 + 1만큼 밀려나게 되죠.
CRUD - 검색
검색도 CRUD의 한 종류입니다. 그래서 우리가 리스트안에 있는 어떤 객체가 몇번째 인덱스에 있는지 알고자할 때, 우리는 메서드를 사용해서 알 수 있습니다.
indexOf()를 사용하면 괄호 안에 들어가는 객체가 리스트의 몇번째에 있는지 반환해줍니다.
// 편의를 위해 리스트 내부의 객체 인덱스를 다음과 같이 표기합니다.
// arrList[0] = 111;
// arrList[1] = 222;
// arrList[2] = 333;
int index = arrList.indexOf(333);
System.out.println(index); // 2위의 코드보다 더 많이 사용하는 방법은 다음과 같습니다.
int index = -1; // 리스트 또는 배열 내부에서 찾을 수 없는 경우
for(int i=0; i < arrList.size(); i++) {
Integer value = arrList.get(i);
if (value == 222) {
index = i; // 찾았을 때 index 갱신
}
break; // 찾았으면 멈춰줌
}CRUD - 업데이트
업데이트는 이미 들어있던 객체를 고쳐주는 것이죠
Integer newV = 100;
arrList.set(0, newV);우선 새로운 정수 객체를 만들어주고, set메서드를 사용해서 0번째 객체를 100으로 바꿔줍니다.
우리가 클래스에 선언된 변수중에 접근 제어자가 private로 지정된 것은 외부에서 참조할 때 getter() 수정할 때 setter()를 사용해줬습니다.
그것과 유사한 개념입니다. 값을 가져오는 get()과 수정하는 set() 반드시 기억해 두시기 바랍니다.
이렇게해서 ArrayList를 다뤄보았습니다.
LinkedList
기본 개념
앞에서 살펴본 ArrayList는 보통 검색이나 대입 등에 자주 활용됩니다.
지금부터 살펴볼 LinkedList는 어떤 정보를 실시간으로 추가, 삭제하는데 있어 처리속도가 빠릅니다.
LinkedList는 ArrayList와 같은 부모를 공유하는 다시 말해서 같은 인터페이스를 공유하는 구현 클래스이기 때문에 사용방법은 비슷합니다.
그렇지만 그 내부 모습은 차이가 있습니다.
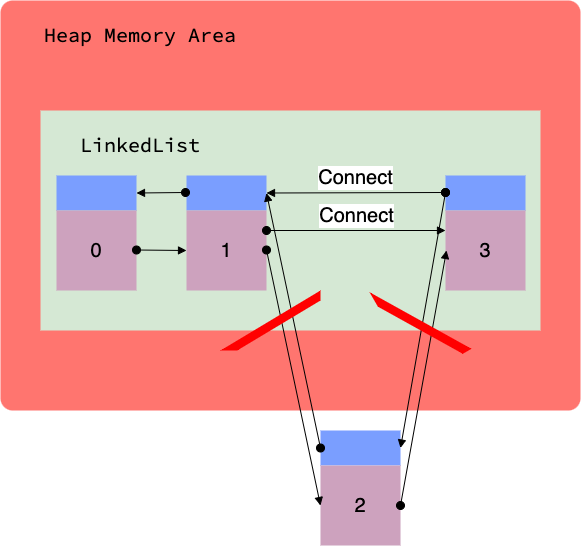
모든 객체가 유기적으로 연결은 되어 있으나 어떤 객체를 제거하게 되면 그 객체와의 유기적인 연결관계는 끊기게 되고 그 옆에 있던 객체와 다시 연결이 됩니다.
앞에서 ArrayList는 중간에 있는 객체를 삭제하면 원래 뒤에 있던 각각의 객체 인덱스가 -1씩 감소한다고 했습니다. 그렇기 때문에 객체의 삽입과 삭제를 자주 해야한다면 ArrayList보다는 LinkedList가 성능면에서 좋다고 말할 수가 있는 것이죠.
선언 방법
LinkedList는 다음과 같이 선언할 수 있습니다.
LinkedList<String> list = new LinkedList<String>();
// 아니면 인터페이스를 인스턴스로 할 수도 있다
List<String> list = new LinkedList<String>();CRUD 구현하기
LinkedList에 객체를 만들어서 넣어주기
LinkedList가 생성 되었다면 우리는 안에 객체를 넣어주어야 합니다.
List<String> list = new LinkedList<String>();add 메서드를 써서 넣어줄 수 있습니다.
list.add("Hyundai"); // 직접 넣어주는 방법
list.add(new String("KIA"); // 객체를 생성해서 넣어주는 방법그 다음으로 잘 들어갔는 지 확인 해봅시다
for (String comp : list) {
System.out.println(comp);
}그 다음으로 ArrayList에는 없지만 LinkedList에만 있는 메서드가 있습니다.
addFirst()와 addLast()입니다.
addFirst()는 리스트의 맨 앞 인덱스 그러니까 0번째 인덱스에 값을 추가해 주는 것이고, addLast()라고 하는 것은 기존에 있던 객체가 리스트의 n번째였다면 n+1번째에 객체를 넣어주는 메서드입니다.
List<String> list = new LinkedList<String>();
list.add("Hyundai");
list.add(new String("KIA");
// addFirst()와 addLast() 사용하기
list.addFirst("Samsung");
list.addLast("Daewoo");다시 말해서 addFirst()라고 하는 것은 add(0, value)을 뜻하는 형태가 되고,addLast()라고 하는 것은 add(n+1, value)의 의미가 되는것이죠.
그리고 LinkedList는 ArrayList에 통째로 넘겨서 사용할 수도 있습니다.
무슨 말이냐하면
List<String> list = new LinkedList<String>();
list.add("Hyundai");
list.add(new String("KIA");
list.addFirst("Samsung");
list.addLast("Daewoo");
// list에 0 ~ 3번째 인덱스에 값이 들어있음
List<String> aList = new ArrayList<String>(list); // LinkedList 자체를 넘겨줌
aList.add("BMW");
for (comp : aList) {
System.out.println(comp);
}
/* 결과출력
Samsung
Hyundai
KIA
Daewoo
BMW
*/LinkedList 수정하기
ArrayList에서 사용했던 객체의 수정을 위한 메서드는 set()이었습니다.
LinkedList도 똑같습니다. 한 번 확인해보겠습니다.
List<String> list = new LinkedList<String>();
list.add("Hyundai");
list.add(new String("KIA");
list.addFirst("Samsung");
list.addLast("Daewoo");
list.set(0, "Benz");
for (comp : list) {
System.out.println(comp);
}
/* 결과출력
Benz
Hyundai
KIA
Daewoo
BMW
*/MapInterface
기본 개념
MapInterface에는 4개의 구현 클래스가 있습니다.
그 중에서도 우리는 HashMap과 TreeMap에 대해서 정리를 해 볼 것입니다.
HashMap은 key와 value형태로 값을 관리해주는 자바스크립트의 객체같은 역할을 합니다.
그리고 TreeMap은 HashMap에 정렬기능을 추가해준 것입니다.
자바스크립트의 객체를 살펴보면
const myObject = {
name: "Paul",
age: 24,
job: "Student",
phone: "iPhone"
}여기에서 name, age, job, phone에 해당하는 것들이 바로 key이고, 그 옆에 Paul, 24, Student, iPhone에 해당하는 것들이 value입니다.
잘 보시면 key와 value가 한 쌍이 되어 묶여 있는 것을 보실 수 있습니다. 자바에서도 마찬가지이며 HashMap이 이 역할을 해줄 것입니다.
선언 방법
선언은 ArrayList, LinkedList처럼 두가지방법으로 해 줄 수 있습니다.
아무쪽이나 쓰셔도 상관은 없습니다.
HashMap<Integer, String> hMap = new HashMap<Integer, String>();
Map<Integer, String> map = new Map<Integer, String>();왜 타입 파라미터를 두개 받을까요? key와 value형태가 한 쌍으로 묶여 있는 구조이기 때문입니다.
CRUD 구현 하기
객체 추가하기
앞에서 살펴봤던 ArrayList와 LinkedList는 객체를 리스트에 넣어줄 때 add()가 공통적으로 사용되었고, LinkedList만의 메서드로 addFirst(), addLast()가 있었습니다.
HashMap에서는 put()을 사용합니다. put메서드 안의 파라미터는 key와 value가 각각 들어갑니다.
Map<Integer, String> map = new Map<Integer, String>();
map.put(1, "하나");
map.put(2, "둘");
map.put(3, "셋");
map.put(4, "넷");여기에서 데이터를 꺼내와보겠습니다. 데이터를 꺼내오기 위해서는 단순히 ArrayList와 LinkedList에서 했던 반복문을 돌리는 방식은 적용되지 않습니다.
왜냐하면 HashMap은 앞에서 살펴본 ArrayList와 LinkedList와는 구조적인 차이가 있기 때문입니다.
ArrayList와 LinkedList는 선형구조 즉 객체 데이터가 직선형으로 쭉 나열되어 있었지만 Map 컬렉션 그러니까 지금 여기서 말하고 있는 HashMap은 선형구조가 아니라 키와 값이 한 쌍을 이뤄 구성된 Entry 객체를 저장하는 구조를 갖고 있기 때문입니다.
이들은 서로 연결되어 있지 않고 따로 공존하는 형태입니다.
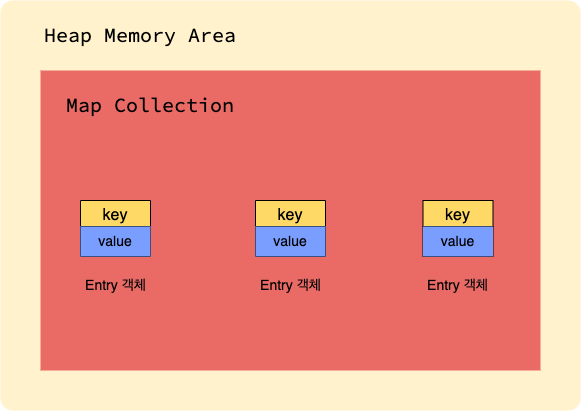
각자가 같은 컬렉션을 공유하지만 개별 객체는 어떠한 연결도 되어있지 않습니다.
그러면 key값으로 객체를 꺼내와 보겠습니다. 이 때 가져올 값은 get 메서드를 사용하는데 파라미터는 반드시 key를 넣어줍니다.
String value = map.get(1);
System.out.println(value); // 하나그렇다면 전체데이터를 꺼내오려면 어떻게 해야 할까요?
우선 선형구조가 아니기 때문에 반복문을 통해서 전부 가져오는 것은 불가능합니다. 그래서 우리는 iterator()로 가져오는데 이를 반복자라고 하고 주소, 포인터의 개념으로 이해하면 될 것 같습니다.
Iterator<Integer> it = map.keySet().iterator();이 때, keySet()은 키값을 뽑아오는 메서드이고 이를 iterator()를 통해서 각각의 값들을 읽어옵니다.
그리고 반복문을 돌려주는데,
Iterator<Integer> it = map.keySet().iterator();
while(it.hasNext()) {
Integer k = it.next();
System.out.println(k); // key
String v = map.get(k);
System.out.println(v); // value
}여기에서 hasNext()는 다음 값이 있는지를 boolean으로 반환해줍니다. next()는 다음 값을 읽어주는 메서드입니다.
객체 삭제하기
삭제는 remove 메서드를 사용해서 파라미터로 key를 넘겨주면 해당 key를 가진 값을 삭제해줍니다.
Map<Integer, String> map = new Map<Integer, String>();
map.put(1, "하나");
map.put(2, "둘");
map.put(3, "셋");
map.put(4, "넷");이렇게 Map이 선언되어 있을 때,
String val = map.remove(1);이렇게 remove 메서드를 사용하면 1이라는 키값을 가진 객체를 삭제해줍니다.
검색
검색은 key값으로 검색해줍니다. 이 때 사용하는 메서드는 containsKey()이며 boolean을 반환해줍니다.
예를 들어서
boolean b = map.containsKey(1); // true1이라는 키를 map이 가지고 있기 때문에 true를 반환해주고
if (b == true) {
System.out.println("하나");
}이렇게 b가 true일 때 "하나"라는 문자열을 출력해 줄 수 있습니다.
수정
수정은 replace 메서드를 사용합니다. 이 메서드는 두개의 파리미터를 받는데 첫번째 오는 파라미터는 key값과 해당 key에 있는 value를 어떻게 바꿀지에 대한 것입니다.
예를 들어서
Map<Integer, String> map = new Map<Integer, String>();
map.put(1, "하나");
map.put(2, "둘");
map.put(3, "셋");
map.put(4, "넷");
map.replace(1, "일");map.replace(1, "일");이라고 해주면 1이라는 키값을 가진 value를 "일"로 바꿔주겠다는 의미입니다.
TreeMap
기본 개념
TreeMap은 앞에서 다룬것처럼 HashMap의 기능에 정렬기능이 탑재되어 있는 것입니다.
그래서 우리는 객체의 key값으로 정렬을 해줄 수 있습니다.
TreeMap<String, String> tMap = new TreeMap<String, String>();
tMap.put("pear", "배");
tMap.put("apple", "사과");
tMap.put("grape", "포도");
tMap.put("banana", "바나나");
tMap.put("orange", "오렌지");가령 위와 같은 TreeMap이 있다고 가정했을 때,
Iterator<String> iter2 = tMap.keySet().iterator(); // 오름차순 정렬
while(iter2.hasNext()) {
String k = iter2.next();
String va = tMap.get(k);
System.out.println("key: " + k + ", value: " + va);
}Iterator<String> iter2 = tMap.descendingKeySet().iterator(); // 내림차순 정렬
while(iter2.hasNext()) {
String k = iter2.next();
String va = tMap.get(k);
System.out.println("key: " + k + ", value: " + va);
}이렇게 메서드를 바꿔줌에 따라 오름차순 정렬과 내림차순 정렬을 받을 수 있습니다.
오늘 준비한 내용은 여기까지입니다.
복습하시는데 도움이 되셨으면 좋겠습니다!!
