
안녕하세요. 이번 포스팅에서는 Oracle에서 JOIN에 대해 소개합니다.
이제까지 우리는 하나의 테이블, EMPLOYEES로만 실습을 진행했습니다. 그렇지만 언젠가 두개의 테이블을 비교해야 할 때도 있을 것이고 세개, 네개의 다중 테이블을 비교할 일이 있을 것입니다.
그래서 오늘은 두 개 이상의 테이블을 연결해서 데이터를 검색하는 방법에 대해 다뤄보도록 하겠습니다.
JOIN이란?
기본 개념
우선 JOIN 연산자는 두 개 이상의 테이블을 연결해서 데이터를 검색해주는 연산자입니다. 보통 두 개 이상의 ROWs의 기본키, 외래키를 사용해서 JOIN 해 줍니다.
기본키라고 하는 것은 Primary Key로 테이블에서 중복되지 않는 키를 의미합니다.
우리가 사용하는 EMPLOYEES 테이블이 이렇게 구성되어 있지요?
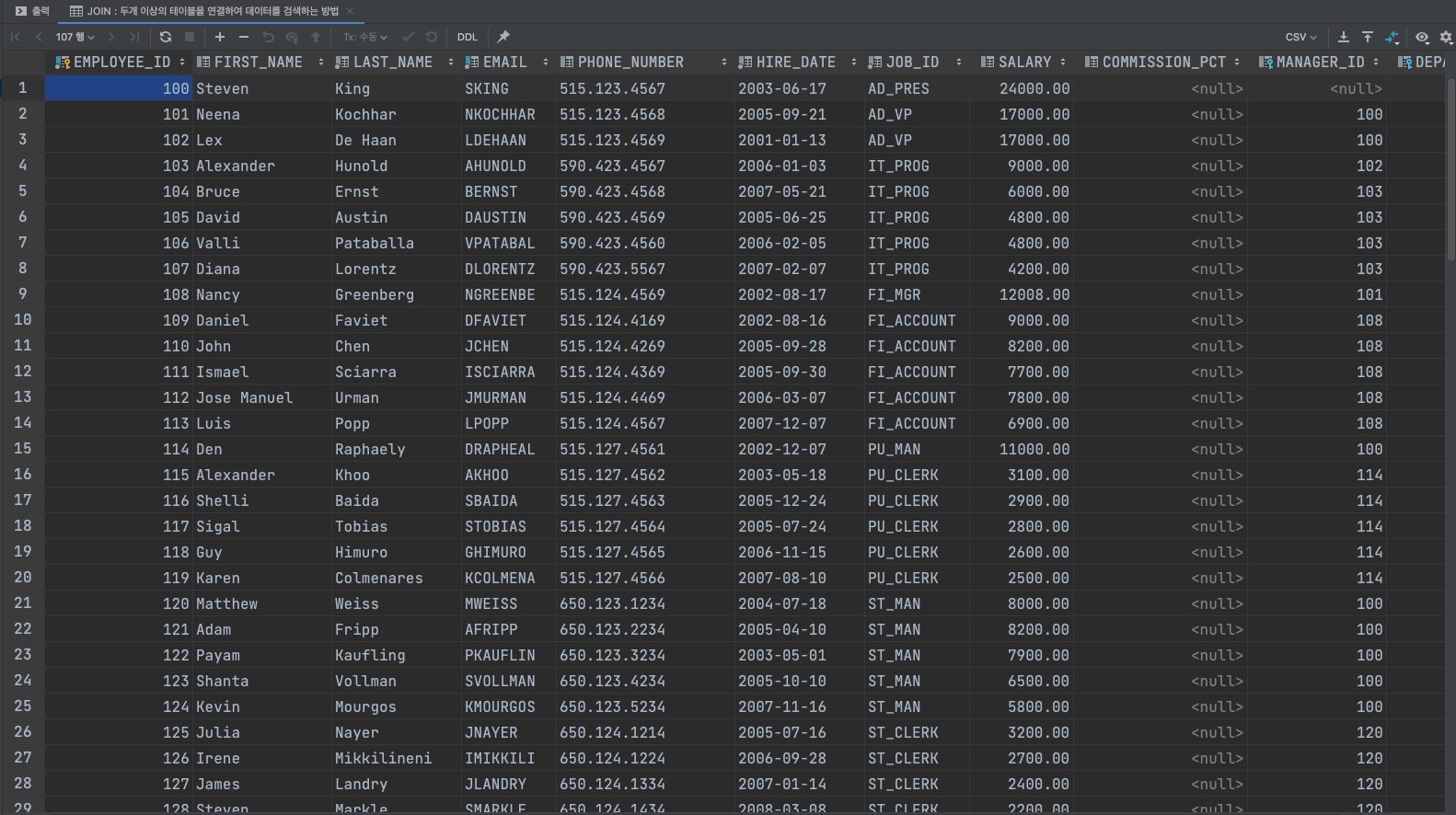
여기에서 기본키로 삼을만 한 것은 무엇이 있을까요? 중복되지 않아야 하기 때문에 EMPLOYEE_ID가 기본키가 될 수 있겠네요!
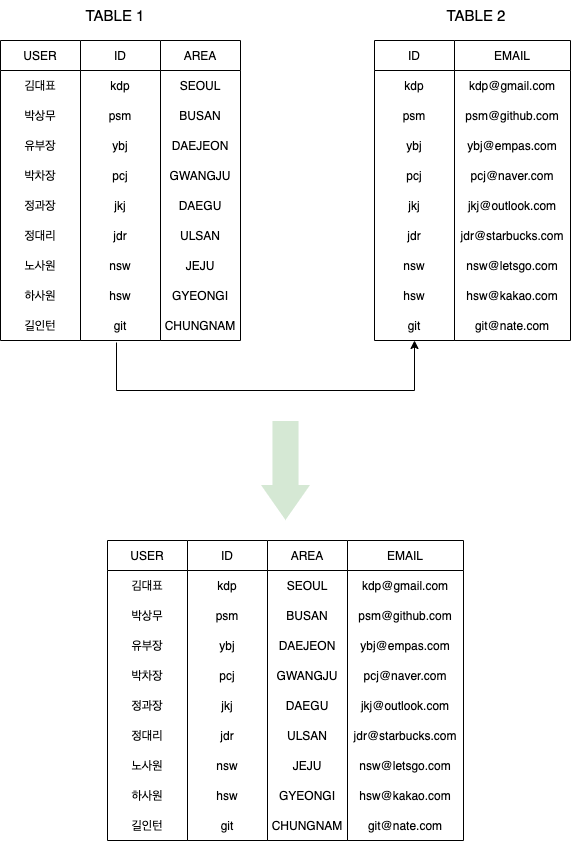
그러면 EMPLOYEES 테이블과 DEPARTMENTS 테이블을 비교했을 때 서로 공통되는 값은 무엇일까요?
바로 DEPARTMENT_ID입니다.
이 때, EMPLOYEES 테이블의 DEPARTMENT_ID는 DEPARTMENTS 테이블의 DEPARTMENT_ID에 연결되어 EMPLOYEES 테이블이 DEPARTMENTS 테이블을 참조할 수 있게 됩니다.
이 때, DEPARTMENTS 테이블의 DEPARTMENT_ID를 Foreign Key(외래키)라고 합니다.
외래키는 다른 테이블에서 Primary Key이거나 Unique Key인 것을 의미합니다.

이렇게 키로 다른 테이블의 데이터를 참조해서 EMPOLYEES의 각 행마다 DEPARTMENT_ID, MANAGER_ID, LOCATION ID를 보여줄 수 있게 됩니다.
JOIN의 종류
JOIN 연산자는 다음과 같이 구성되어 있습니다.
INNER JOIN,
CROSS JOIN,
OUTER JOIN:LEFT OUTER JOIN,RIGHT OUTER JOIN,FULL OUTER JOIN
SELF JOIN
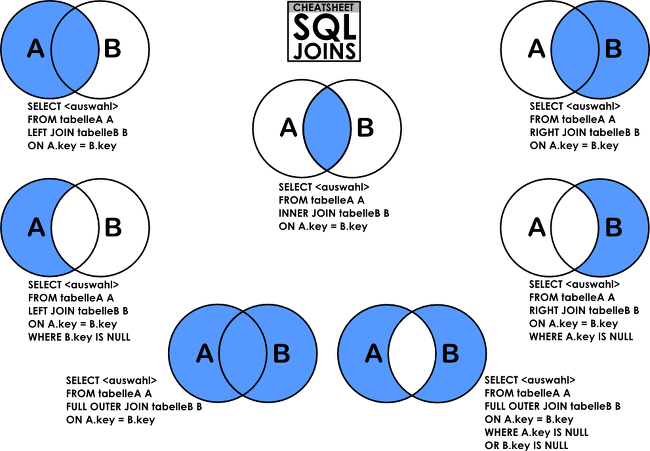
그림으로 간단하게 살펴보면 INNER JOIN은 교집합 개념으로 비교 대상 모두에 속하는 개념입니다.
그리고 CROSS JOIN은 한 쪽 테이블의 모든 행들과 다른 테이블의 모든 행을 묶는 기능을 합니다.
그래서, CROSS JOIN의 결과 개수는 두 테이블의 행의 개수를 곱한 개수가 됩니다.
OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN, FULL OUTER JOIN이 있는데, LEFT OUTER JOIN은 그림에서와 같이 JOIN문의 왼쪽에 있는 테이블의 모든 결과를 가져와서 오른쪽 테이블의 데이터를 매칭시키고 매칭되는 데이터가 없으면 NULL로 표기합니다.
RIGHT OUTER JOIN은 그 반대의 경우입니다.
FULL OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 합친 형태이며 양쪽의 조건과 매치되지 않는 것까지 모두 가져와서 보여줍니다.
조인문의 왼쪽에 있는 테이블의 모든 결과를 가져 온 후 오른쪽 테이블의 데이터를 매칭하고, 매칭되는 데이터가 없는 경우 NULL로 표시한다.
각각의 연산자를 어떻게 사용하는지 보겠습니다.
INNER JOIN
사용에 앞서 ANSI SQL 방식과 Oracle 방식 모두 살펴 볼 것입니다. ANSI SQL은 모든 SQL의 공통사항이기 때문에 별도로 알고 있으면 좋을 것으로 생각합니다.
INNER JOIN은 기준이 되는 테이블과 조인을 할 테이블 모두에 데이터가 있어야 조인 됩니다.
EMPLOYEES 부서 번호를 JOIN하여 이름, 부서번호, 부서명을 보여주려고 한다면 다음과 같이 작성해 줄 수 있습니다.
-- ANSI SQL
SELECT EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;우선 테이블의 ALIAS로 E가 붙어있습니다. 이는 컬럼의 ALIAS와 붙이는 방식은 똑같습니다. AS를 포함해도 되고 안해도 됩니다.
이 때, 조인이 쓰인 쿼리문을 보면
INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;DEPARTMENT를 조인하겠다는 의미로 기본 키를 E.DEPARTMENT_ID로 해서 외래키를 D.DEPARTMENT_ID로 하여 연결시켜주겠다는 의미입니다.
그러면 오라클 문법으로는 어떻게 표현해 줄 수 있을까요?
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID;EMPLOYEES 테이블과 DEPARTMENTS 테이블을 기준으로 조건절을 써서 나타내 주었습니다.
결과는 이렇게 나옵니다.
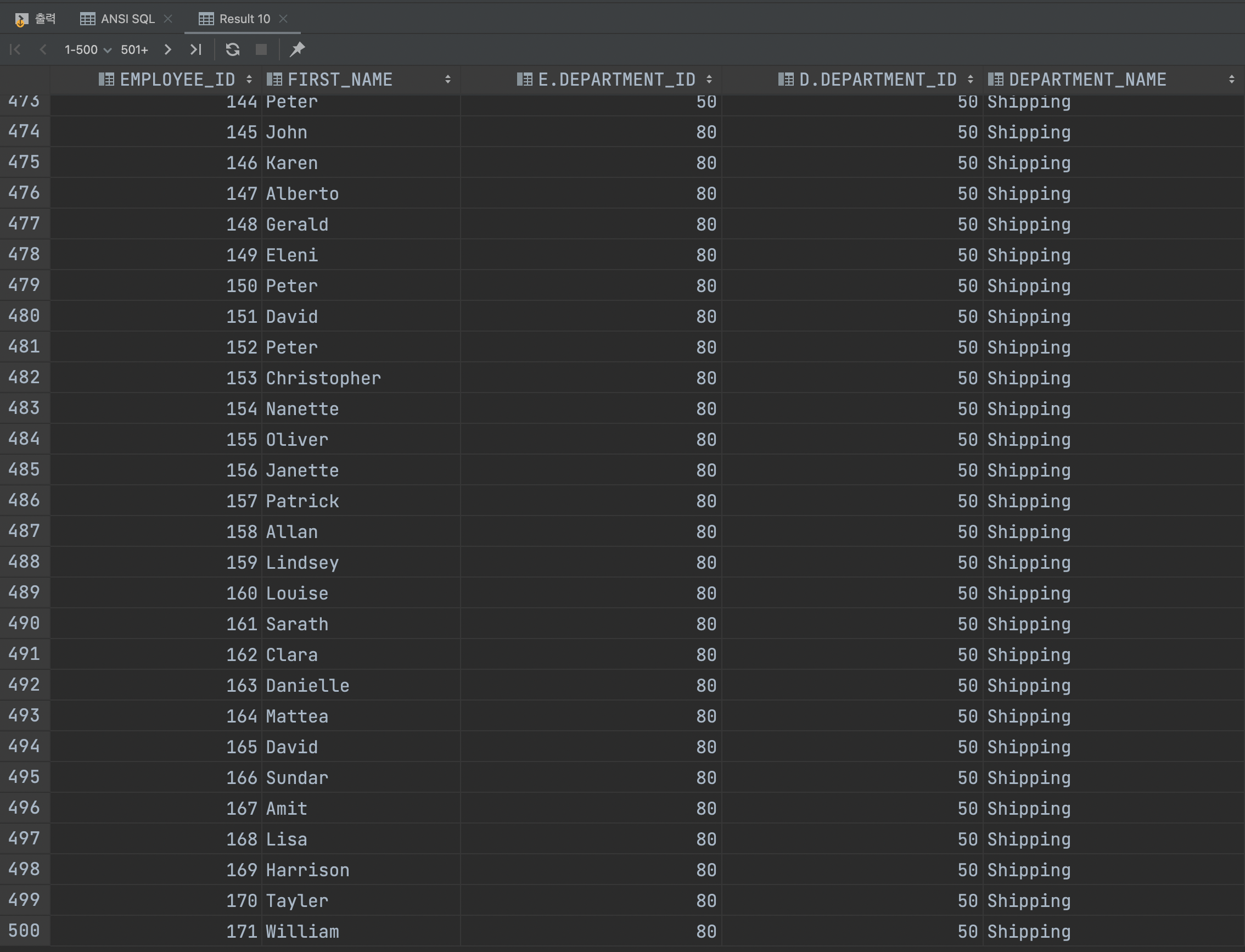
CROSS JOIN
크로스 조인은 한 쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시켜줍니다.
이렇게 기준이 되는 테이블 1이 참조하는 테이블 2의 항목마다 순회하며 전부 조인합니다.
그래서 조인 이후에는 81개 행이 만들어지게 됩니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
CROSS JOIN DEPARTMENTS D;이 쿼리문은 보여줄 항목을 지정하고 기준 테이블을 EMPLOYEES E로 잡아 DEPARTMENTS D과 조인시켜주었습니다.
오라클 문법으로는 각각 기준 테이블로 잡고 공통되는 것만 같이 작성해주면 됩니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D;결과는 다음과 같습니다.
OUTER JOIN
OUTER JOIN은 위에서 살펴본 INNER JOIN과 CROSS JOIN과는 다르게 공통되는 항목 이외의 것도 전부다 보기 위해 쓰는 조인입니다.
LEFT OUTER JOIN
JOIN문의 왼쪽에 있는 테이블의 모든 결과를 가져와서 오른쪽 테이블의 데이터를 매칭시키고 매칭되는 데이터가 없으면 NULL로 표기합니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
LEFT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;예를 들어서 위와 같은 쿼리문을 작성한다면 기준 테이블인 EMPLOYEES에 있는 항목을 전부 다 보여주는데, 비교 테이블 DEPARTMENTS에 없는 항목이라면 EMPLOYEES에는 NULL을 반환해 줍니다.
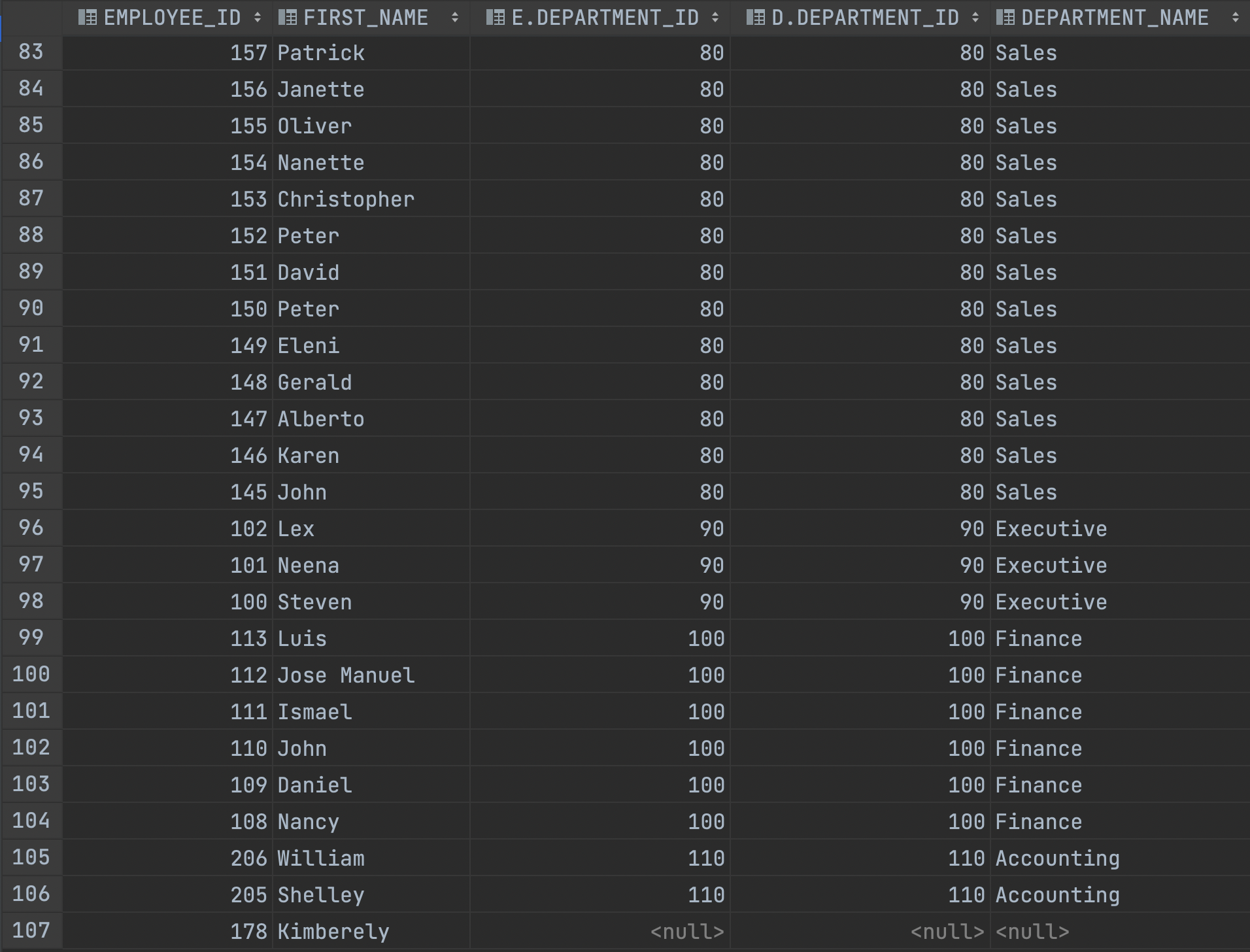
맨 마지막의 Kimberely는 원래 DEPARTMENT_ID와 DEPARTMENT_NAME을 가지고 있지 않았으므로 NULL을 반환해주고 있습니다.
오라클 문법에서는 아래와 같이 표현합니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID(+);이렇게 비교대상이 되는 테이블에 (+)을 붙여줍니다.
RIGHT OUTER JOIN
LEFT OUTER JOIN의 반대개념입니다. 조건에 맞지 않더라도 비교 테이블의 모든 정보를 불러와줍니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
RIGHT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;이 때 EMPLOYEES은 106번에서 끝나지만 DEPARTMENTS는 122번에서 끝납니다.
그렇지만 DEPARTMENTS는 106번에서 끝나지 않고 EMPLOYEES의 106번까지 보여준 후 나머지는 NULL로 반환되었습니다.
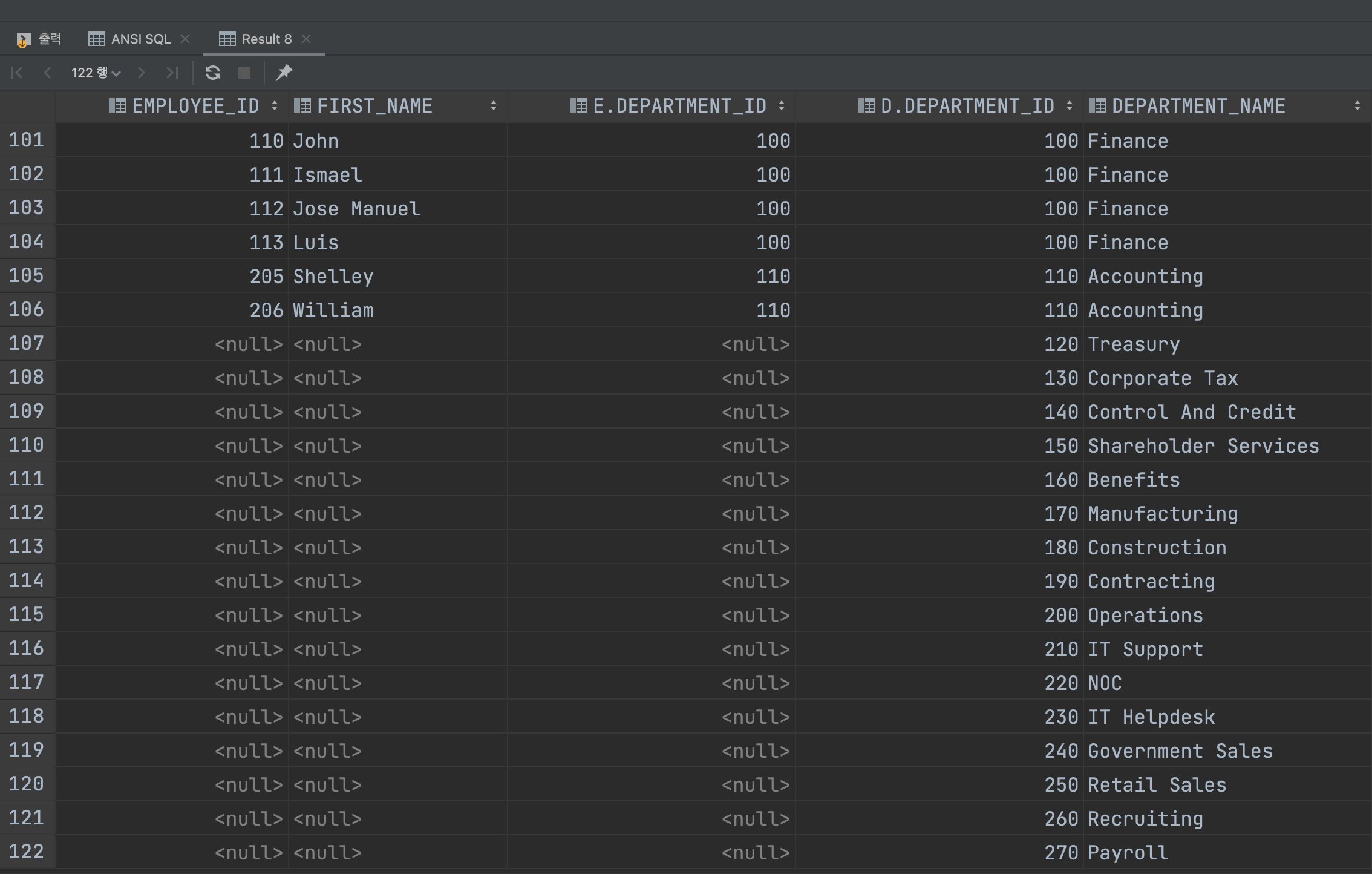
오라클 문법에서 표현할 때는 LEFT OUTER JOIN에서 표기한 +의 위치를 전항으로 옮겨주면 됩니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID(+) = D.DEPARTMENT_ID;FULL OUTER JOIN
FULL OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 합친 형태입니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E
FULL OUTER JOIN DEPARTMENTS D
on E.DEPARTMENT_ID = D.DEPARTMENT_ID;EMPLOYEES 테이블을 기준으로 DEPARTMENTS 테이블을 FULL OUTER JOIN해주면 EMPLOYEES과 DEPARTMENTS의 LEFT OUTER JOIN을 먼저 해주고 그 다음으로 나머지 부분을 RIGHT OUTER JOIN 해줍니다.
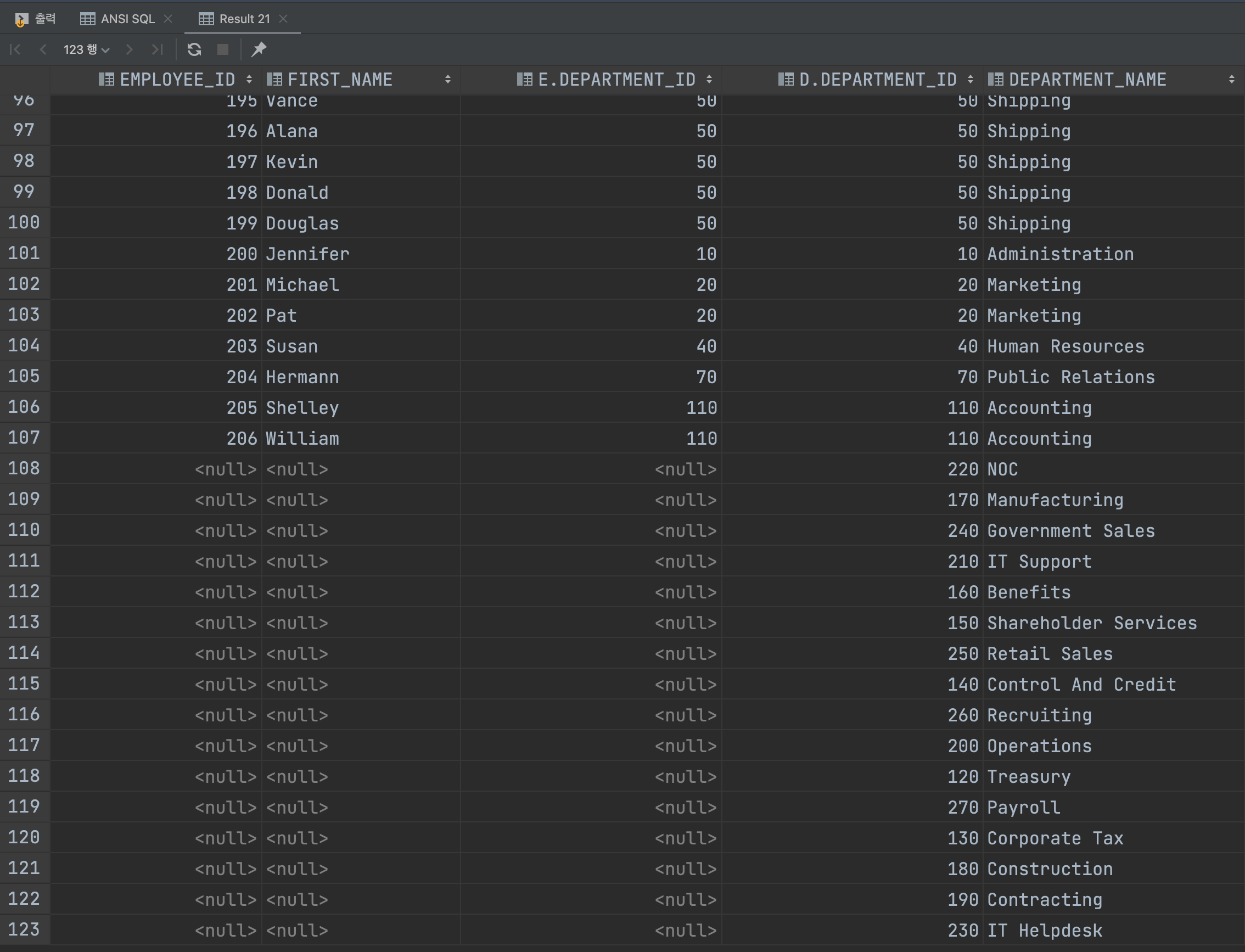
LEFT OUTER JOIN에서 Kimberely가 있었지만 RIGHT OUTER JOIN에는 Kimberely가 없습니다. 왜냐하면 LEFT에 속하기 때문이지요.
그래서 전부다 가져왔을 때 RIGHT OUTER JOIN에서 Kimberely가 추가되어 한개가 늘어난 것입니다.
위에서 FULL OUTER JOIN은 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 합친 형태라고 했습니다. ANSI SQL에는 두개를 합쳐줄 때 FULL OUTER JOIN을 사용할 수 있지만 오라클 문법에서는 제공하고 있지 않습니다.
그래서 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 더해주는 형태를 취해야 합니다. 이 때 UNION이라는 연산자를 사용합니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID(+)
UNION ----------------------------- 두개를 합쳐줌
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID(+) = D.DEPARTMENT_ID;오라클 문법으로 차집합 구하기
위에서 살펴본 예시를 다시 생각해볼 때, LEFT OUTER JOIN에 속하지만 RIGHT OUTER JOIN는 속하지 않는 것을 어떻게 구할 수 있을까요?
바로 WHERE 구문을 통해 IS NULL을 찾아 반환해주면 됩니다.
SELECT E.EMPLOYEE_ID,
E.FIRST_NAME,
E.DEPARTMENT_ID,
D.DEPARTMENT_ID,
D.DEPARTMENT_NAME
FROM EMPLOYEES E, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID(+)
AND E.DEPARTMENT_ID IS NULL;LEFT OUTER JOIN을 해주고 그 다음 메인 테이블에서 NULL인 값만 반환하라고 하면 되겠죠?
SELF JOIN : 동일한 테이블 JOIN하기
조인을 할 때 서로 다른 테이블만 하라는 법은 없습니다.
EMPLOYEERS 테이블에서 어떤 사원의 상사를 찾으라고 한다면 어떻게 할 수 있을까요?
EMPLOYEERS 테이블 내에서 두번 비교를 해줘야하는데, 이럴 때는 ALIAS를 다르게 주고 비교할 수 있습니다.
SELECT A.EMPLOYEE_ID, A.FIRST_NAME,
A.MANAGER_ID, B.EMPLOYEE_ID,
B.FIRST_NAME
FROM EMPLOYEES A, EMPLOYEES B --- A : 사원 / B : 상사
WHERE A.MANAGER_ID = B.EMPLOYEE_ID
AND A.EMPLOYEE_ID = 168;같은 테이블을 두개의 ALIAS로 만들어주고 사원을 기준으로 잡을 테이블의 매니저 아이디 즉 상사 번호와 상사를 기준으로 잡을 테이블의 사원번호를 비교해주면 결과를 볼 수 있습니다.

QUERY안의 QUERY : SUB-QUERY
기본 개념
자바나 자바스크립트에서 고차함수를 쓸 수 있습니다. 바로 메서드 또는 함수 안에 또 다른 메서드나 함수가 있는 것이지요.
SQL에서도 마찬가지로 쿼리문 안에 또 다른 쿼리가 있을 수 있습니다.
SQL에서 이를 서브 쿼리라고 하고 일반 쿼리문보다 우선 실행됩니다.
SELECT, FROM, WHERE에 쓸 수 있으며 각각 다음 규칙에 따릅니다.
| 사용되는 절 | 서브쿼리의 결과 | 명칭 |
|---|---|---|
SELECT | 단일행이거나 SUM, COUNT 등의 집계 함수를 거친 단일 값 | 스칼라 서브쿼리 |
FROM | 하나의 테이블로 리턴 | 인라인뷰 서브쿼리 |
WHERE | 단일행과 복수행 둘 다 리턴 | 중첩 서브쿼리 |
SELECT 구문에 쓰는 스칼라 서브쿼리
스칼라 서브쿼리는 반드시 결과값으로 단일행 또는 집계 함수를 거친 단일 값이어야 합니다.
왜냐하면 서브쿼리의 리턴값 하나를 메인 쿼리에서 SELECT 하기 때문입니다.
예를 들어서 SELECT에 어떤 컬럼을 입력하는데 EMPLOYEES에서 EMPLOYEE_ID와 FIRST_NAME을 보여주고 싶습니다. 그럴 때 기본적으로 아래와 같이 입력하죠.
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES;그런데 이 중에서 EMPLOY_ID가 100인 사람을 포함해서 출력해야 한다면 아래와 같이 SELECT할 항목을 쿼리로 작성할 수 있습니다.
SELECT EMPLOYEE_ID, FIRST_NAME,
(SELECT FIRST_NAME
FROM EMPLOYEES
WHERE EMPLOYEE_ID = 100)
FROM EMPLOYEES;아래 쿼리문과 차이점은 무엇일까요?
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE EMPLOYEE_ID = 100;바로 스칼라 서브쿼리를 썼을 때는 서브쿼리로 쓴 쿼리문을 포함해서 출력해주지만 서브쿼리 없이 조건문을 밑에 쓴 쿼리문은 해당 조건에 대한 결과만 보여줍니다.
스칼라 서브쿼리로 작성후 실행한 결과
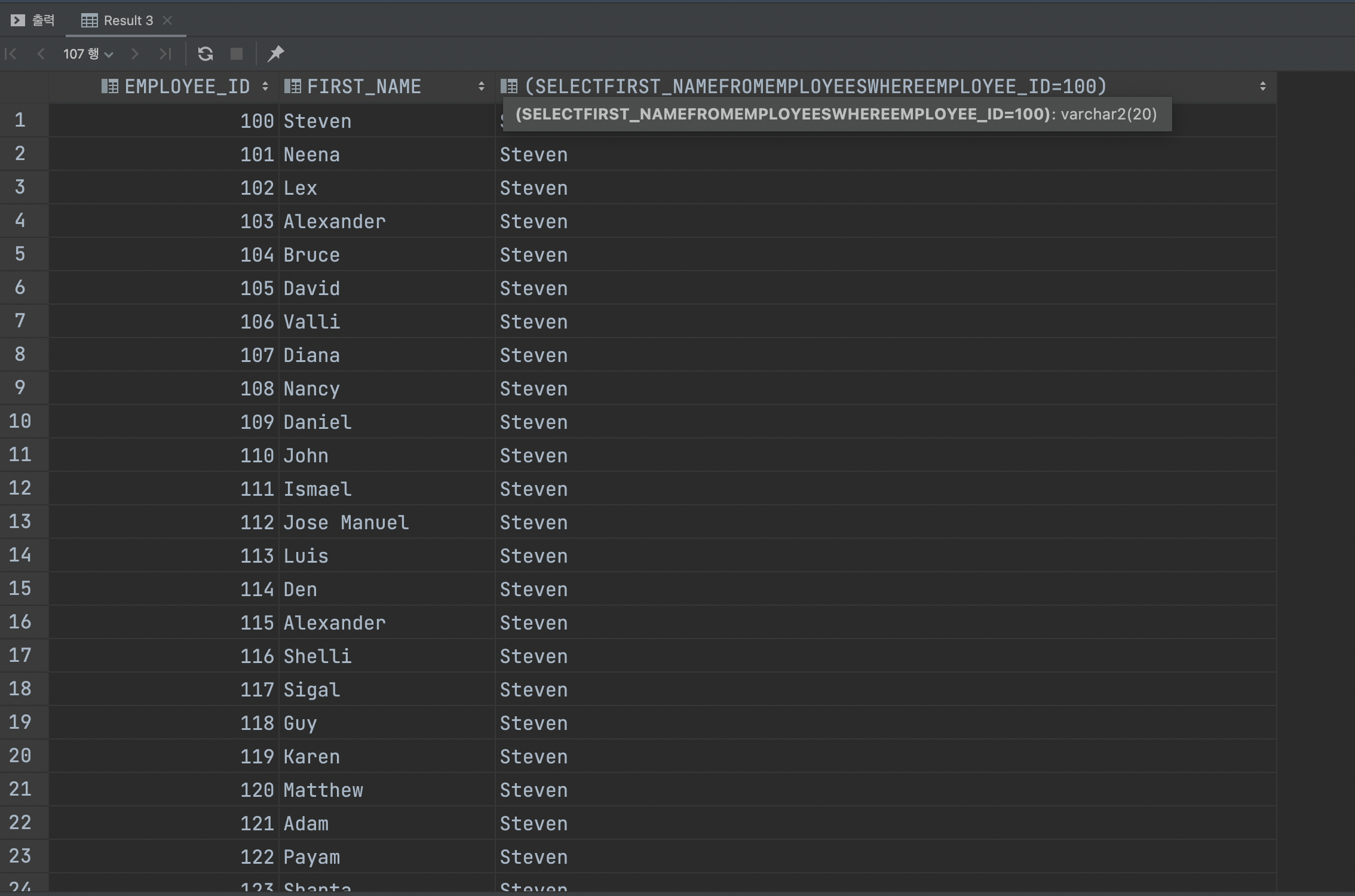
스칼라 서브쿼리를 작성하지 않고 조건문을 하단에 작성하여 실행한 결과
아래와 같은 경우는 다중 ROW나 다중 COLUMN을 반환하므로 원하지 않는 결과가 나오거나 에러가 발생합니다.
-- 다중 로우이므로 안됨
SELECT EMPLOYEE_ID, FIRST_NAME,
(SELECT FIRST_NAME
FROM EMPLOYEES
WHERE EMPLOYEE_ID = 10000)
FROM EMPLOYEES;
-- 다중 컬럼이므로 안됨
SELECT EMPLOYEE_ID, FIRST_NAME,
(SELECT FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE EMPLOYEE_ID = 10000)
FROM EMPLOYEES;서브쿼리 안에서 함수를 같이 사용할 수 있습니다.
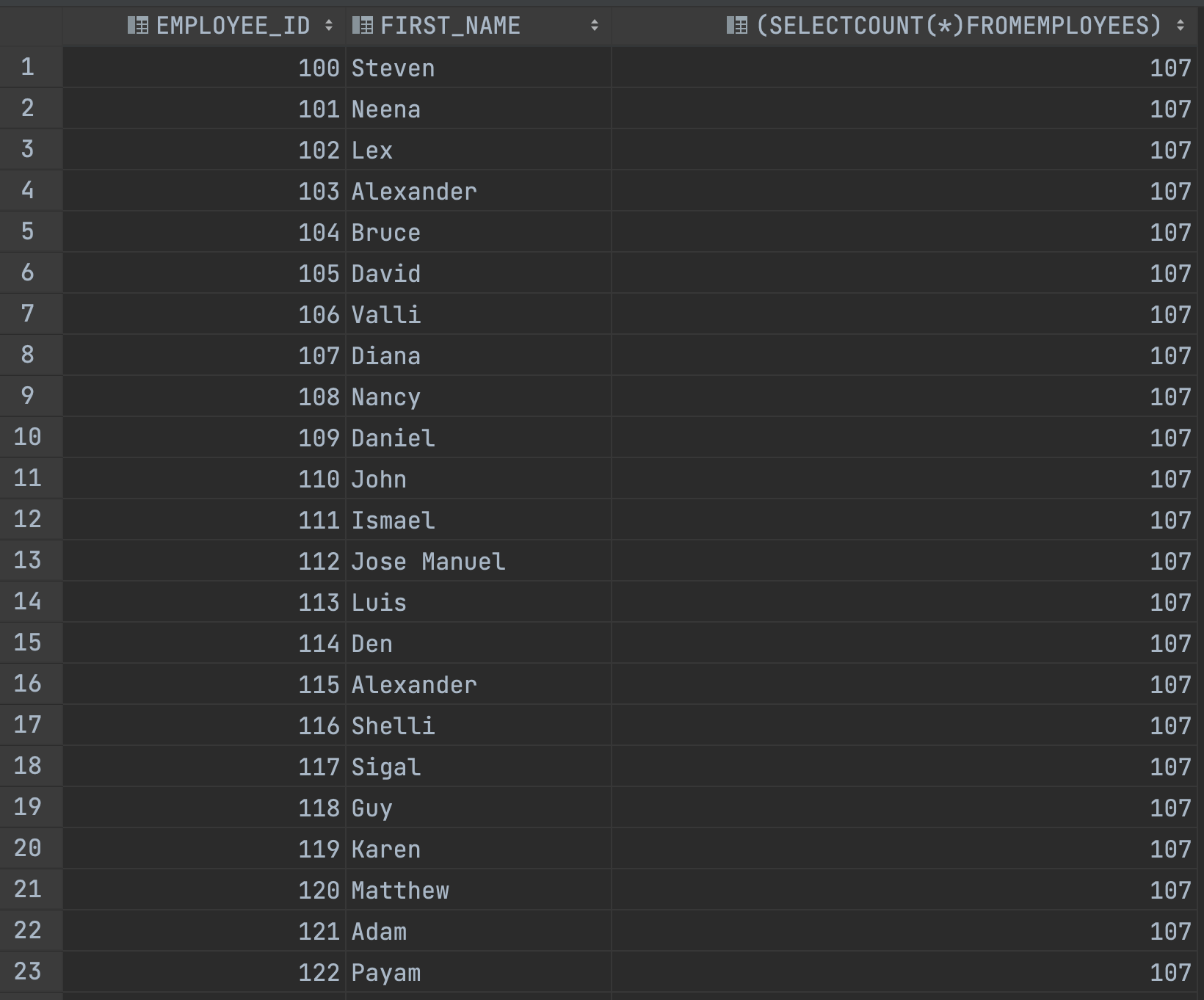
SELECT EMPLOYEE_ID, FIRST_NAME,
(SELECT COUNT(*)
FROM EMPLOYEES)
FROM EMPLOYEES;EMPLOYEES의 컬럼 수를 카운트한 결과를 함께 반환해줍니다.
FROM 구문에 쓰이는 인라인뷰 서브쿼리
FROM절에 사용하는 인라인뷰 서브쿼리는 반드시 하나의 테이블로 결과값이 리턴되어야 합니다.
서브쿼리를 끝마친 테이블 하나를 메인쿼리의 FROM절에서 테이블로 취하기 때문입니다.
쉽게 말해서 한번 필터링 해준 다음 이를 기반으로 SELECT해준다는 개념으로 보면 됩니다.
예를 들어서 DEPARTMENT_ID가 80인 사람들만을 놓은 상태로 한번 필터링하고 EMPLOYEE_ID, SALARY를 보여주는 표를 만든다고 하면 다음과 같이 할 수 있습니다.
SELECT EMPLOYEE_ID, SALARY
FROM(SELECT EMPLOYEE_ID, SALARY
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 80)그러면 FROM은 해당 조건에 맞는 테이블 하나로 바뀌게 되고 이를 바탕으로 EMPLOYEE_ID, SALARY를 SELECT해서 보여줍니다.
위 쿼리문으로 뽑힌 표에서 급여가 1000이상인 사람만 뽑는다고 하면 하단에 또 조건문을 추가해줄 수 있습니다.
SELECT EMPLOYEE_ID, SALARY --- 여기에 들어갈 내용은
FROM(SELECT EMPLOYEE_ID, SALARY --- 여기서 내보내 준 내용만 들어가야함
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 80)
WHERE SALARY > 10000또한 주석으로 남겨놓은 것처럼 메인 쿼리의 SELECT가 받는 컬럼명은 인라인뷰 서브쿼리에서 내보낸 내용만 들어가야 합니다.
그러면 DEPARTMENT_ID가 50이고 SALARY가 6000 이상인 사람들의 아이디, 급여, 부서번호를 출력하려면 어떻게 해야 할까요?
SELECT EMPLOYEE_ID, SALARY, DEPARTMENT_ID
FROM(SELECT *
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 50
AND SALARY >= 6000);이렇게 작성할 수 있습니다.
WHERE 구문에 쓰이는 중첩 서브쿼리
중첩 서브쿼리는 단일행, 다중행 모두 반환할 수 있습니다.
실습파일에서 평균 급여보다 많이 받는 사원을 구하려고 합니다. 어떻게 하면 좋을까요?
평균급여를 내주고 이보다 급여 값이 크다면 테이블에서 SELECT로 보여주면 될 것입니다.
SELECT FIRST_NAME, SALARY
FROM EMPLOYEES
WHERE SALARY > (SELECT ROUND(AVG(SALARY)) FROM EMPLOYEES);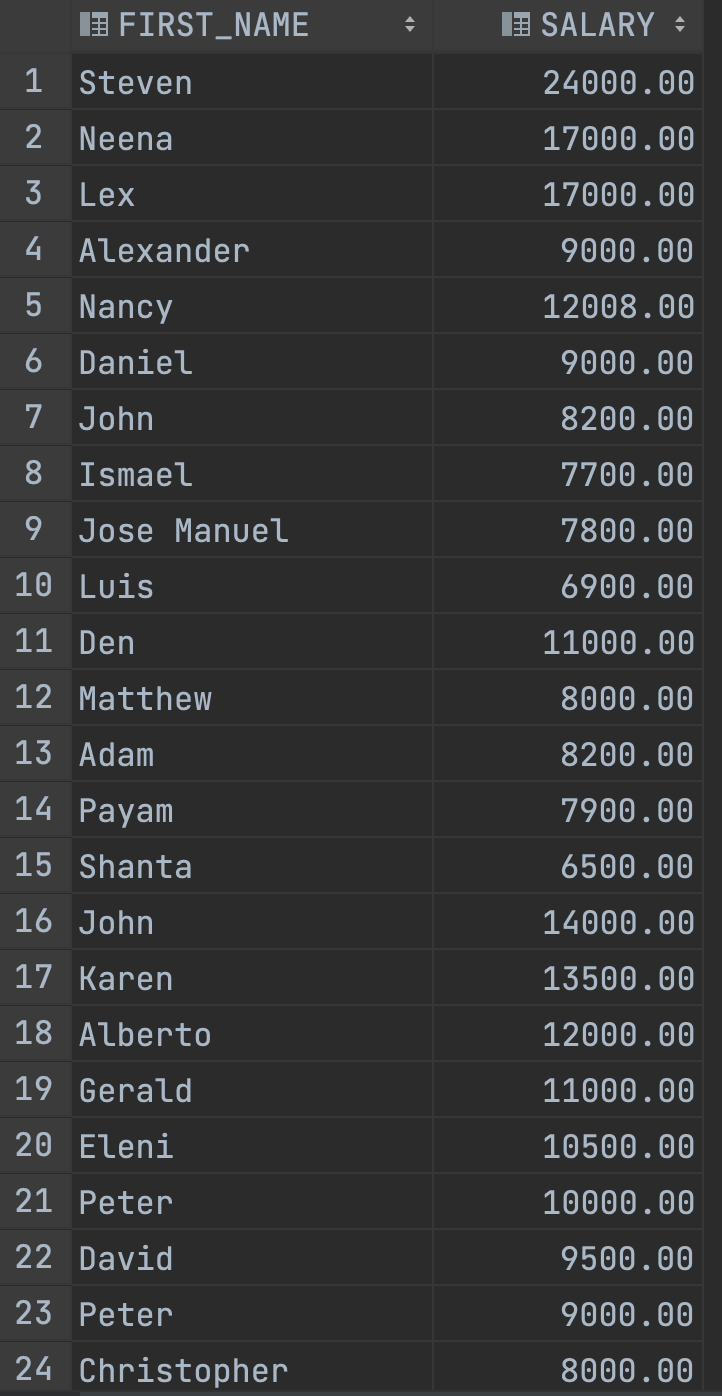
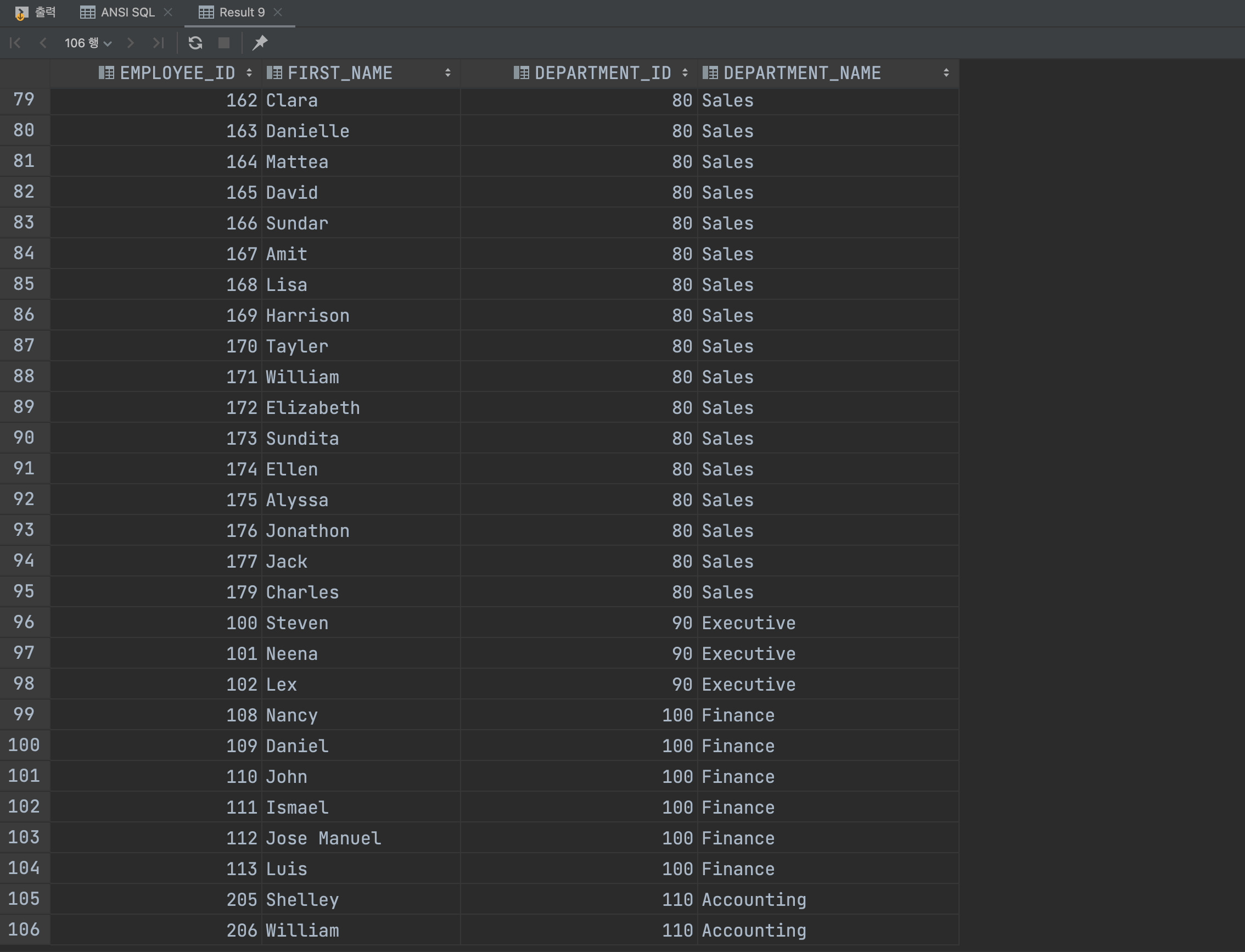
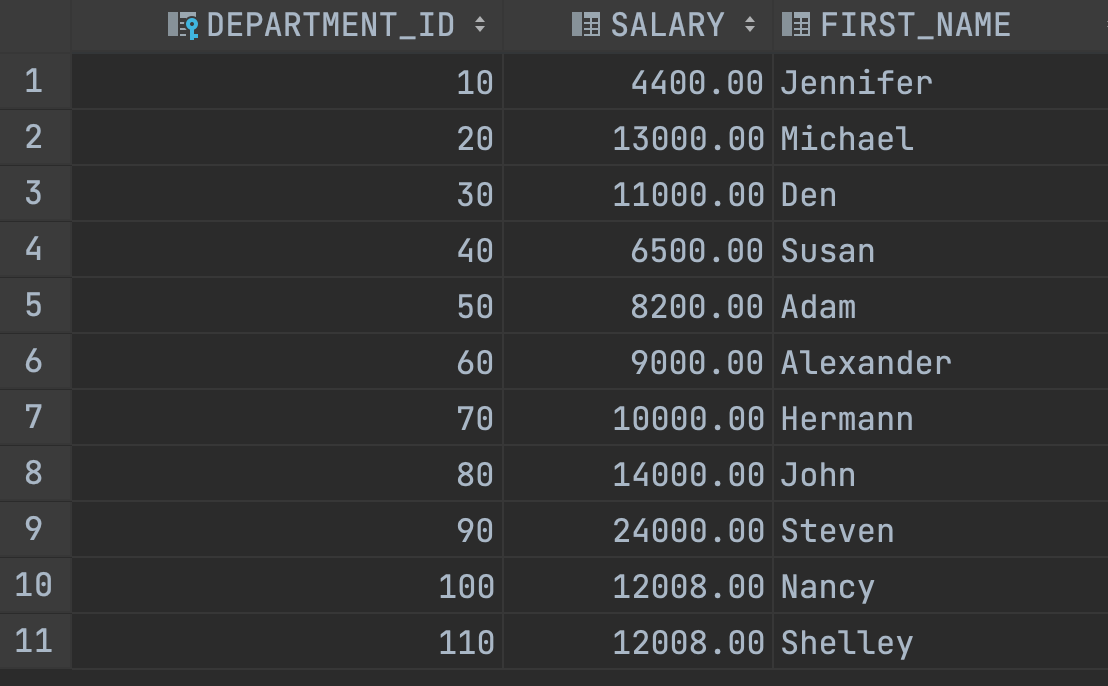
부서별로 가장 많은 급여를 받는 사원을 보여주려면 어떻게 하면 좋을까요?
EMPLOYEES 테이블에서 급여의 최대값과 확인용으로 부서 번호를 뽑아주는데 이를 부서 번호를 기준으로 정렬해주면 보기 좋겠죠? 그리고 이 값들이 부서번호와 급여 목록에 있다면 이를 이름과 함께 보여주면 됩니다.
SELECT DEPARTMENT_ID, SALARY, FIRST_NAME
FROM EMPLOYEES
WHERE (DEPARTMENT_ID, SALARY) IN (SELECT DEPARTMENT_ID, MAX(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID)
ORDER BY DEPARTMENT_ID;결과는 이렇게 나옵니다.
특수 쿼리
특수쿼리는 서브쿼리의 개념과 다소 다르게 별도의 기능을 수행하는 쿼리입니다.
자바에서 조건문을 쓸 때 if문 이외에 switch case문이 있었죠? SQL에서도 비슷한 기능을 하는 구문이 있습니다.
또한 자바에서 substring이라는 해당 번지수의 글자를 반환해주는 메서드가 있었습니다. SQL에서도 이와 같은 기능을 하는 쿼리가 있습니다.
SWITCH ... WHEN ~ THEN
자바에서 우리가 입력받은 값에 따라 작업을 처리해줄 때 switch case문을 썼습니다.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("1이나 2를 입력하세요 >> ");
int num = sc.nextInt();
switch(num) {
case 1:
System.out.println("1입니다");
break;
case 2:
System.out.println("2입니다");
break;
default:
System.out.println("잘못된 값");
}
}
}이렇게 입력받은 값에 따라서 처리를 다르게 해주는게 자바에서 switch case문 이었습니다.
SQL에서도 이와 같은 기능을 하는 구문이 있는데 다음과 같은 형식을 갖습니다.
CASE 조건
WHEN 조건에_대한_값 THEN 처리
WHEN 조건에_대한_값 THEN 처리
WHEN 조건에_대한_값 THEN 처리
ELSE 위에_해당하지_않을_때_처리
END만약 EMPLOYEES의 전화번호 앞 세자리 숫자에 따라 지역명을 표시해주고 싶을 때는 어떻게 하면 좋을까요?
우선 SELECT로 보여줄 항목을 고르고 FROM으로 기준 테이블을 잡아줍니다. 여기까지는 기본적으로 데이터를 테이블로 보여주는 방법이죠.
그리고 SELECT와 FROM사이에 CASE문을 써주면 됩니다.
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER,
CASE SUBSTR(PHONE_NUMBER, 1, 3)
WHEN '515' THEN '서울'
WHEN '590' THEN '부산'
WHEN '650' THEN '대전'
ELSE '기타'
END
FROM EMPLOYEESCASE문의 내용을 다른 컬럼명으로 보여주려면 END 뒤에 AS 별칭 처리를 해주면 됩니다.
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER,
CASE SUBSTR(PHONE_NUMBER, 1, 3)
WHEN '515' THEN '서울'
WHEN '590' THEN '부산'
WHEN '650' THEN '대전'
ELSE '기타'
END AS 지역
FROM EMPLOYEES아래와 같이 결과가 출력됩니다.
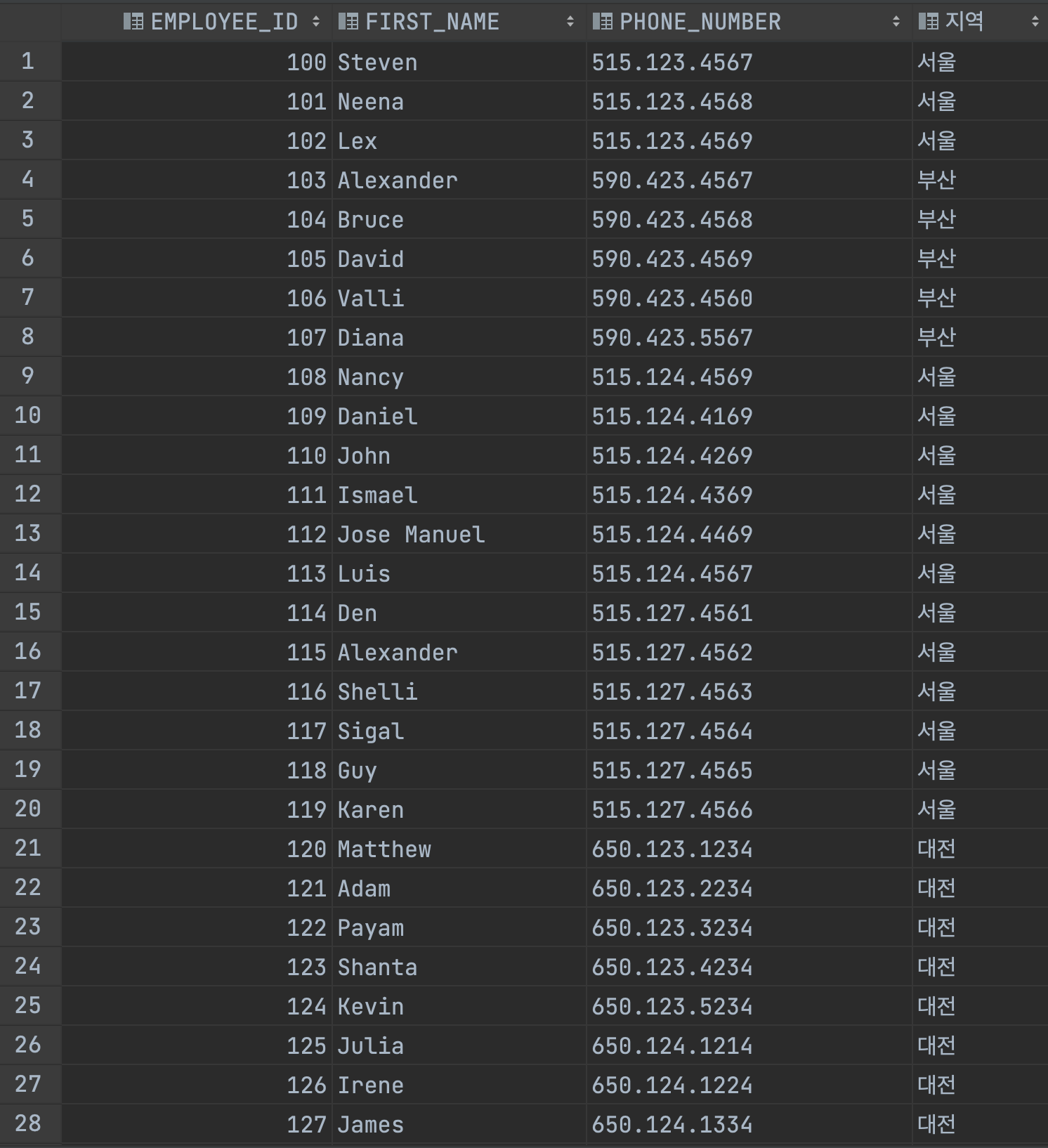
여기에서 SUBSTR이라는 함수가 사용되었습니다. 이 함수의 구조는
SUBSTR(인자, 시작, 보여줄_글자_수)구조이며, 시작을 기준으로 보여줄 글자 수를 써준다는 점에서 자바와 차이가 있습니다.
자바에서는 어떤 문자열을 0부터 시작해서 마지막으로 받은 수의 바로 앞까지 보여주지만 SQL에서는 모든 데이터는 1부터 셉니다.
그래서 SUBSTR('hello', 1, 3)이라고 쓴다면 h부터 세글자를 보여줄 것이라는 의미가 됩니다.
DECODE 구문
DECODE는 SWITCH문을 간결하게 쓴 형태로 보면 됩니다.
위에서 사용한 예시를 가져와보겠습니다.
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER,
CASE SUBSTR(PHONE_NUMBER, 1, 3)
WHEN '515' THEN '서울'
WHEN '590' THEN '부산'
WHEN '650' THEN '대전'
ELSE '기타'
END AS 지역
FROM EMPLOYEESCASE부터 END를 한 덩어리로 묶어서 쓸 수 있습니다.
SELECT EMPLOYEE_ID, FIRST_NAME, PHONE_NUMBER,
DECODE(SUBSTR(PHONE_NUMBER, 1, 3),
'515', 'SEOUL',
'590', 'BUSAN',
'650', 'DAEJEON'
) AS AREA
FROM EMPLOYEES이렇게 한층 간결해집니다.
DECODE 내부에 조건과 각각 처리할 값-결과를 순서쌍으로 넣어줍니다.
분석 함수
분석 함수란 테이블의 행에 대해 특정 그룹별로 집계한 값을 산출해줄 때 사용합니다.
보통 그룹핑을 할 때 GROUP BY를 사용하지만 이는 기준 테이블의 로우 넘버를 줄여주지만 분석함수를 사용하면 로우 넘버가 바뀌지 않고 집계값을 얻을 수 있습니다.
분석 함수의 종류
| 구분 | 종류 |
|---|---|
| 순위 함수 | RANK, DENSE_RANK, ROWNUM, NTILE |
| 집계 함수 | SUM, MIN, MAX, AVG, COUNT |
| 기타 함수 | LEAD, LAG, FIRST_VALUE, LAST_VALUE, RATIO_TO_REPORT, KEEP, LISTAGG |
이렇게 많은 종류의 분석함수가 있습니다. 이번 포스팅에서는 ROWNUM에 대해서만 다루겠습니다.
집계 함수는 이전 포스팅에서 통계함수라는 키워드로 다뤘습니다.
나머지는 그렇게 많이 사용되지 않으니 필요로 할 때 검색을 통해 찾아보시면 될 것 같습니다.
ROWNUM 함수
이 함수는 로우넘버 컬럼을 만들어줍니다.
그리고 이 함수는 다른 함수들과 다르게 함수명 뒤에 괄호를 동반하지 않습니다.
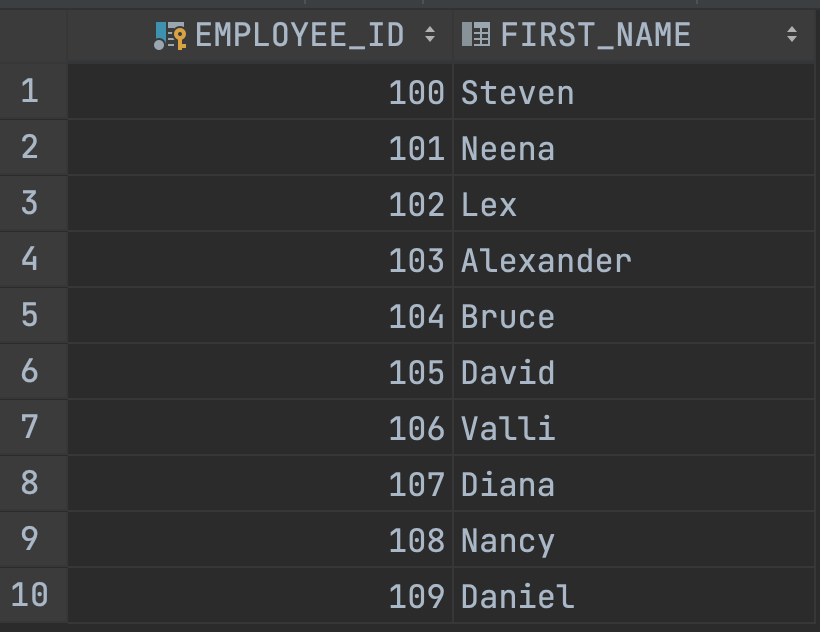
EMPLOY_ID가 100이상 109이하인 경우 EMPLOY_ID와 이름을 보여주려면 어떻게 하면 될까요?
SELECT EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE EMPLOYEE_ID >= 100 AND EMPLOYEE_ID <= 109보통 우리는 조건절에 논리연산자 AND를 넣어 조건을 만들어줍니다.
그렇지만 ROWNUM 함수를 써서 ROWNUM이 EMPLOY_ID에 대해 100부터 1이라고 가정했을 때, ROWNUM이 10이하인 경우로 좀 더 간결하게 쿼리문을 작성해줄 수 있습니다.
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE ROWNUM <= 10;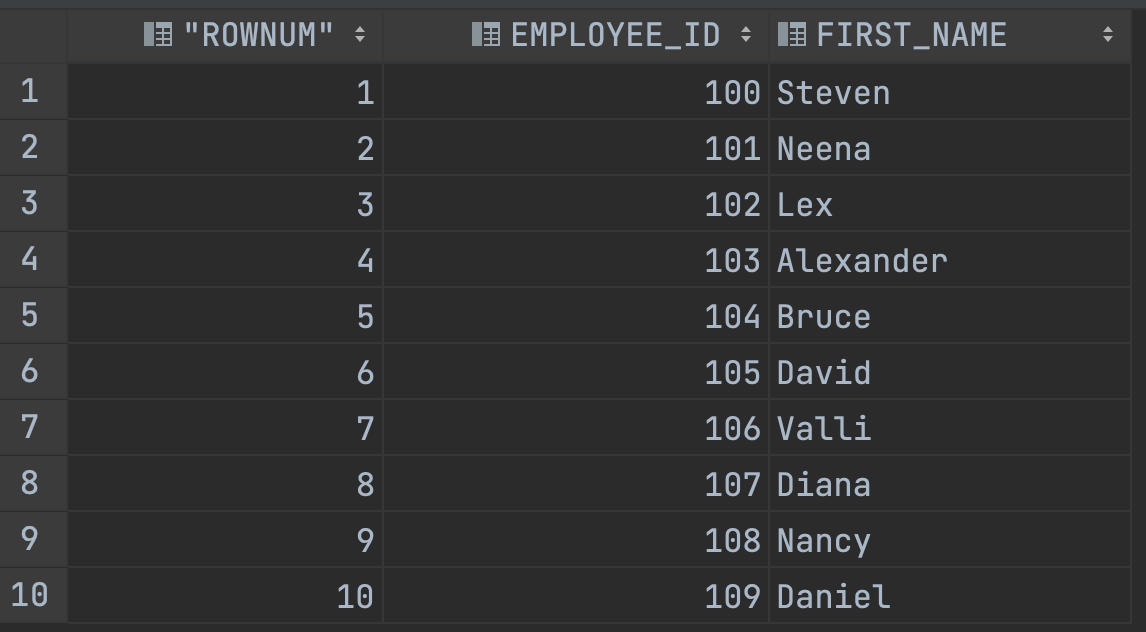
보시면 ROWNUM 컬럼이 추가되어 있습니다.
자 그렇다면 ROWNUM이 11이상 20이하인 경우를 출력해주려면 어떻게 해야 할까요?
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME
FROM EMPLOYEES
WHERE ROWNUM >= 11 AND ROWNUM <= 20;이렇게 쓰면 될까요?
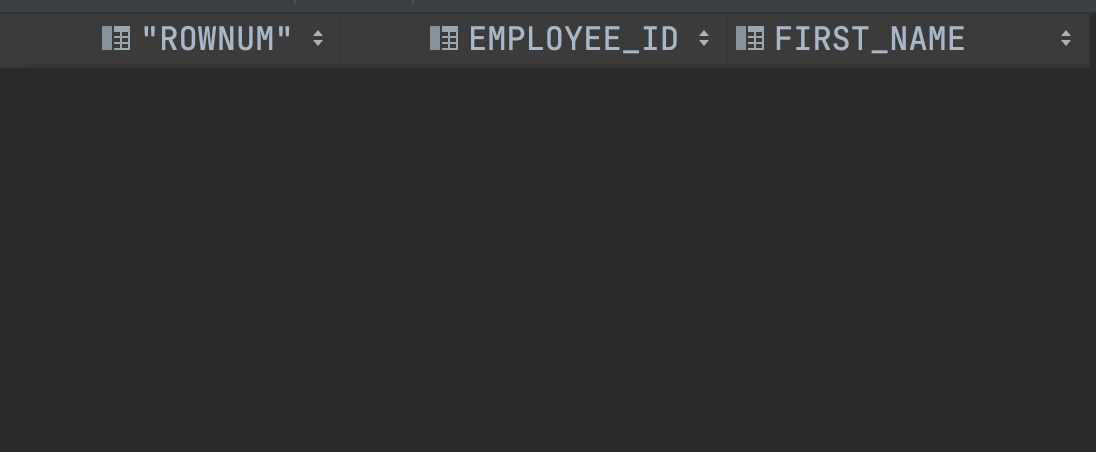
이게 뭐지?????
이렇게 작성하면 안됩니다. ROWNUM에 대한 조건은 하나만 받을 수 있기 때문인데요.
두개의 조건을 써주기 위해서는 조금 복잡한 절차를 거쳐야 합니다.
이런 경우에는 우선 정렬을 해주고 ROWNUM을 적용해준 다음 범위를 지정해주어야 합니다.
- 내림차순으로 정렬
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES ORDER BY SALARY DESC;
ROWNUM지정SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, SALARY -- 2 FROM (SELECT EMPLOYEE_ID, FIRST_NAME, SALARY -- 1 FROM EMPLOYEES ORDER BY SALARY DESC)
ROWNUM의 범위지정SELECT RNUM, EMPLOYEE_ID, FIRST_NAME, SALARY -- 3 FROM (SELECT ROWNUM AS RNUM, EMPLOYEE_ID, FIRST_NAME, SALARY -- 2 FROM (SELECT EMPLOYEE_ID, FIRST_NAME, SALARY -- 1 FROM EMPLOYEES ORDER BY SALARY DESC) ) WHERE RNUM >= 11 AND RNUM <= 20;
이렇게 단계별로 작성한 내용이 FROM의 서브쿼리로 들어가면서 필터링된 테이블이 되었을 때 ROWNUM(메인 쿼리의 RNUM)에 두개의 조 건을 걸 수 있게 됩니다.
결과는 이렇습니다.
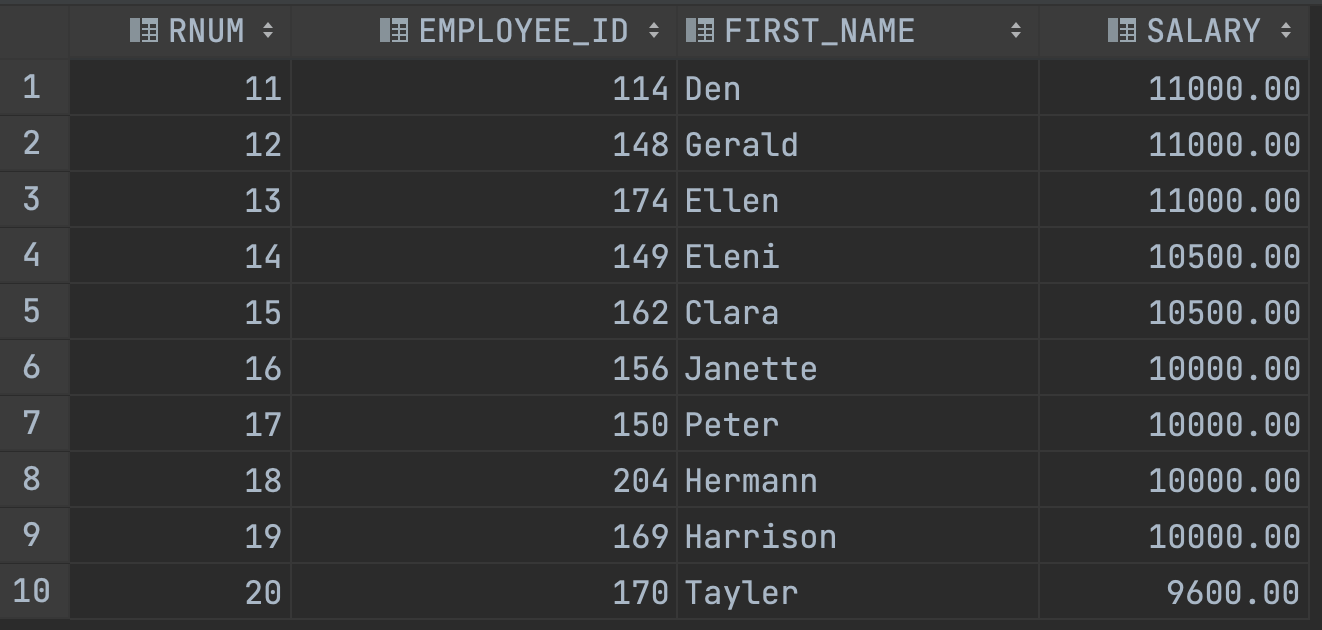
오늘 준비한 내용은 여기까지 입니다. 복습에 도움이 되시길 바랍니다.
부록
MySQL과 ORACLE DB의 차이점?
https://artrudy.tistory.com/12?category=948553
ORACLE DB의 다양한 쿼리문
https://artrudy.tistory.com/13?category=948553
