1. 개요
이번 글에서는 영속성 전이 옵션(cascade) 중 REMOVE 사용시 주의해야 할 점을 알아볼 것입니다. REMOVE 옵션과 더불어, 영속성 컨텍스트의 상태에 따라 달라지는 delete의 동작 방식을 알아볼 것입니다.
1.1. 예제 도메인
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String memberName;
public Member(String memberName) {
this.memberName = memberName;
}
}
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String teamName;
@OneToMany(cascade = {PERSIST, REMOVE})
@JoinColumn(name = "team_id", updatable = false, nullable = false)
private List<Member> members = new ArrayList<>();
public Team(String teamName, List<Member> members) {
this.teamName = teamName;
this.members = members;
}
}예제 상황은 위와 같다. Member와 Team간의 일대다 단방향 연관관계가 걸려있는 상황이다. 이때 우선 Team 쪽에 cascade = {PERSIST, REMOVE}가 설정되어 있는 상황이다.
그렇다면 Team을 저장할 때에 함께 저장된 List<Member>도 자동으로 저장될 것이다.
2. 테스트
2.1. PERSIST 테스트
테스트 케이스를 간단하게 작성하였다. REMOVE에 대해서 알아보기 전 간단하게 PERSIST 옵션에 대해서도 알아보자!
@DataJpaTest
class MemberRepositoryTest {
@Autowired private MemberRepository memberRepository;
@Autowired private TeamRepository teamRepository;
@Test
void test() {
//given
Member member1 = new Member("member1");
Member member2 = new Member("member2");
Member member3 = new Member("member3");
Team teamA = new Team("teamA", List.of(member1, member2, member3));
//when, then
teamRepository.save(teamA);
em.flush();
em.clear();
}
}그 결과로 아래와 같이 쿼리가 날아갔음을 볼 수 있다. 즉, PERSIST라는 영속성 전이 옵션 덕분에, Team에 대해서만 영속화를 진행해도, Member의 영속화는 자동으로 진행되는 것을 볼 수 있다.
insert into team (team_name,id) values ('teamA',default);
insert into member (team_id,member_name,id) values (1,'member1',default);
insert into member (team_id,member_name,id) values (1,'member2',default);
insert into member (team_id,member_name,id) values (1,'member3',default);2.2. REMOVE 테스트
테스트 맨 마지막의 em.flush()는 @DataJpaTest 내부의 @Transactional로 인해 테스트 마지막에 쿼리가 안나가고 롤백되어 버리는 현상을 막고자 호출하였다. 이로써 delete쿼리를 정상적으로 확인할 수 있을 것이다.
@DataJpaTest
class MemberRepositoryTest {
@Autowired private MemberRepository memberRepository;
@Autowired private TeamRepository teamRepository;
@Autowired private EntityManager em;
@Test
void test() {
//given
Member member1 = new Member("member1");
Member member2 = new Member("member2");
Member member3 = new Member("member3");
Team teamA = new Team("teamA", List.of(member1, member2, member3));
//when
teamRepository.save(teamA);
em.flush();
em.clear();
//then
System.out.println("========================");
teamRepository.delete(teamA);
em.flush();
}
}테스트 결과를 알아보기 전에, 나의 생각을 먼저 정리해보았다. 위와 같이 save한 이후에 영속성 컨텍스트를 모두 지워주었는데, 바로 delete 메서드를 날리면 어떻게 될까? 내 우려는 다음과 같았다.
teamA가 영속성 컨텍스트에 없으니 예외를 발생시킨다.teamA가 영속성 컨텍스트에 없으니, find로 조회 쿼리를 날려 영속성 컨텍스트에 올려둔 후에 삭제한다.
하지만 삭제하려고 할 때에, 영속성 전이 REMOVE 속성 때문에 연관된 members들 또한 영속성 컨텍스트에 없는 상황에서 어떻게 동작할지 예측이 되지 않았다. 이 부분에 대한 우려도 정리를 해보자면
members가 영속성 컨텍스트에 없으니 예외를 발생시킨다.members가 영속성 컨텍스트에 없으니, find로 조회 쿼리를 날려 영속성 컨텍스트에 올려둔 후에 삭제한다.
이제 테스트를 돌려서 발생하는 쿼리를 확인해보자.
========================
select t1_0.id,t1_0.team_name from team t1_0 where t1_0.id=1;
select m1_0.team_id,m1_0.id,m1_0.member_name from member m1_0 where m1_0.team_id=1;
delete from member where id=1;
delete from member where id=2;
delete from member where id=3;
delete from team where id=1;System.out.println("========================"); 이후의 쿼리들을 추려보았다.
위에서 내가 우려한 것 중 모두 2번 방식대로 쿼리가 호출되었다.
즉, 영속성 컨텍스트에 일단 엔티티를 올려두기 위해 select 쿼리로 team과 해당 team에 소속된 member들을 모두 불러왔다.
이후에 영속성 전이 속성인 REMOVE로 인해, team을 삭제했을 때 하위의 member들을 모두 삭제시키고 마지막에 team을 지우도록 쿼리가 날아가고 있음을 확인했다.
2.3. SimpleJpaRepository의 delete 메서드
위의 예제에서 teamRepository.delete(teamA) 를 호출하였는데, 그렇다면 delete 메서드가 어떻게 구현되었는지 확인해보자.
우선 CrudRepository 인터페이스에는 delete 메서드에 대한 스펙이 정의되어 있다.

이를 구현한 구현체인 SimpleJpaRepository를 확인해보자.
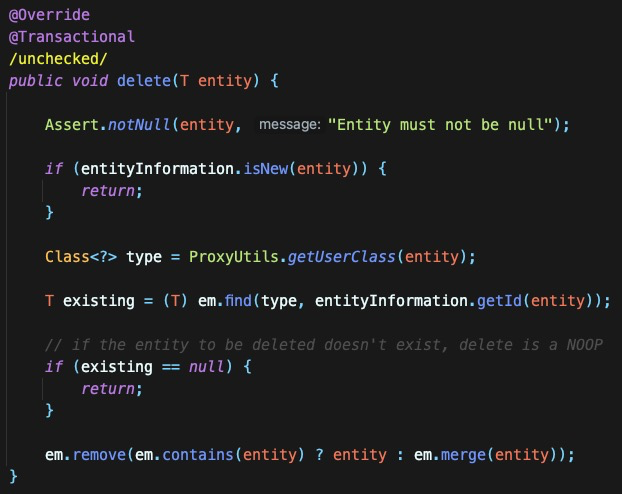
구현체에서 확인할 수 있듯이, em.find()를 호출하는 부분을 확인할 수 있다. 해당 메서드는 @Transactional이 붙어 있고, 기본 전파 옵션이 REQUIRE이므로 이전의 트랜잭션을 그대로 이어 받을 것이다. 따라서 이전에 이미 해당 엔티티가 영속성 컨텍스트에 있다면, em.find()를 호출하더라도 캐시되어 있는 엔티티를 참조하기 때문에 쿼리가 나가지 않는다. 반면에 영속성 컨텍스트에 해당 엔티티가 존재하지 않는다면 조회 쿼리가 나간다.
특이한 점은, 결과적으로 마지막에 em.remove()를 호출할 때의 로직이다. 우선 em.contains()메서드를 통해 영속성 컨텍스트에 존재하는지체크하고..
- 존재한다면 entity를 삭제한다.
- 존재하지 않으면
em.merge()를 호출한다.- 이 메서드는 주어진 엔티티가 영속성 컨텍스트에 있을 경우 해당 엔티티의 상태를 데이터베이스에 동기화하고, 영속성 컨텍스트가 없을 경우 해당 엔티티를 데이터베이스에서 조회하여 영속성 컨텍스트에 추가하는 역할을 한다.
- 즉, 이곳에서 한 번 더 영속성 컨텍스트에 엔티티를 올려두는 것을 강제한다.
2.4. Trouble Shooting
왜 스프링 데이터 JPA에서는 삭제하기 전에, 해당 엔티티를 영속성 컨텍스트에 올려 놓으려고 할까?
이에 대한 자세한 자료는 찾을 수 없어서 일단 영속성 컨텍스트의 존재 이유에 대해서 생각해보자면…
생각 나는 것은 데이터의 정합성이었다. JPA는 영속성 컨텍스트를 통해 엔티티의 상태 변화를 추적하고 이를 데이터베이스에 동기화하는 역할을 한다. 그런데 영속성 컨텍스트를 거치지 않고, 데이터베이스에 바로 변경을 가한다면 혹시 기존에 영속성 컨텍스트에 남아 있는 엔티티들 간의 동기화가 제대로 이루어지지 않았을 것이다.
우리가 직접 JPQL을 쓰는 것이 아니라 이미 구현된 SimpleJpaRepository의 메서드를 가져다 쓰는 만큼, 영속성 컨텍스트에 엔티티를 올려 관리해주기 위해 이렇게 동작하지 않나 싶다.
물론 이전 글에서 정리한 @Query를 통해 JPQL로 쿼리를 수정 쿼리를 직접 작성하고 @Modifying을 붙여 데이터베이스에 바로 쿼리를 날리는 방법도 있다.
3. 정리
이전 글에서도 delete 메서드에서 SELECT 쿼리가 발생하는 것을 확인했다. 이번 글에서는 추가적으로 cascade 옵션에 따른 삭제 로직이 어떻게 되는지 알아봤다.
이미 영속성 컨텍스트에 올라와 있는 엔티티를 삭제할 때에는 간단하게 삭제할 수 있어서 사용하면 좋을 것 같지만, 많은 엔티티가 영향을 받는 수정 쿼리나 연관관계가 얽혀 있는 경우에는 delete 때문에 오히려 N + 1 문제가 터질 수 있다. N + 1문제를 해결하기 위해 delete 전에 페치 조인으로 엔티티를 조회하도록 하는 방법이 생각났지만, 이 방법이 삭제를 하는 의도와 상황에 있어서 맞는 방법은 아닌 것 같다.
따라서 이럴 때에는 영속성 컨텍스트의 도움을 받지 않고, 직접 데이터베이스에 수정 쿼리를 날릴 수 있는 @Query + @Modifying 조합이 더 좋지 않을까 생각된다.
4. 참고
https://github.com/spring-projects/spring-data-jpa/issues/594
https://www.baeldung.com/spring-data-jpa-modifying-annotation

👍