
1. JVM 이란?
- OS와 독립적으로 바이트코드를 실행할수 있게도 해주고, 메모리를 자동으로 관리해주는 가상머신입니다.
Java compiler가 java 파일을 class 파일(byte code)로 변환시켜주고, OS가 byteCode를 이해할수 있도록 JVM이 해석해준다고 생각하시면 됩니다.- JVM의 노력으로 OS와 상관 없이 코드를 실행시킬 수 있습니다.
2. JVM 구조
- JVM은 크게
Class Loder,RunTime Data Area,Execution engine으로 나눠지는데요.
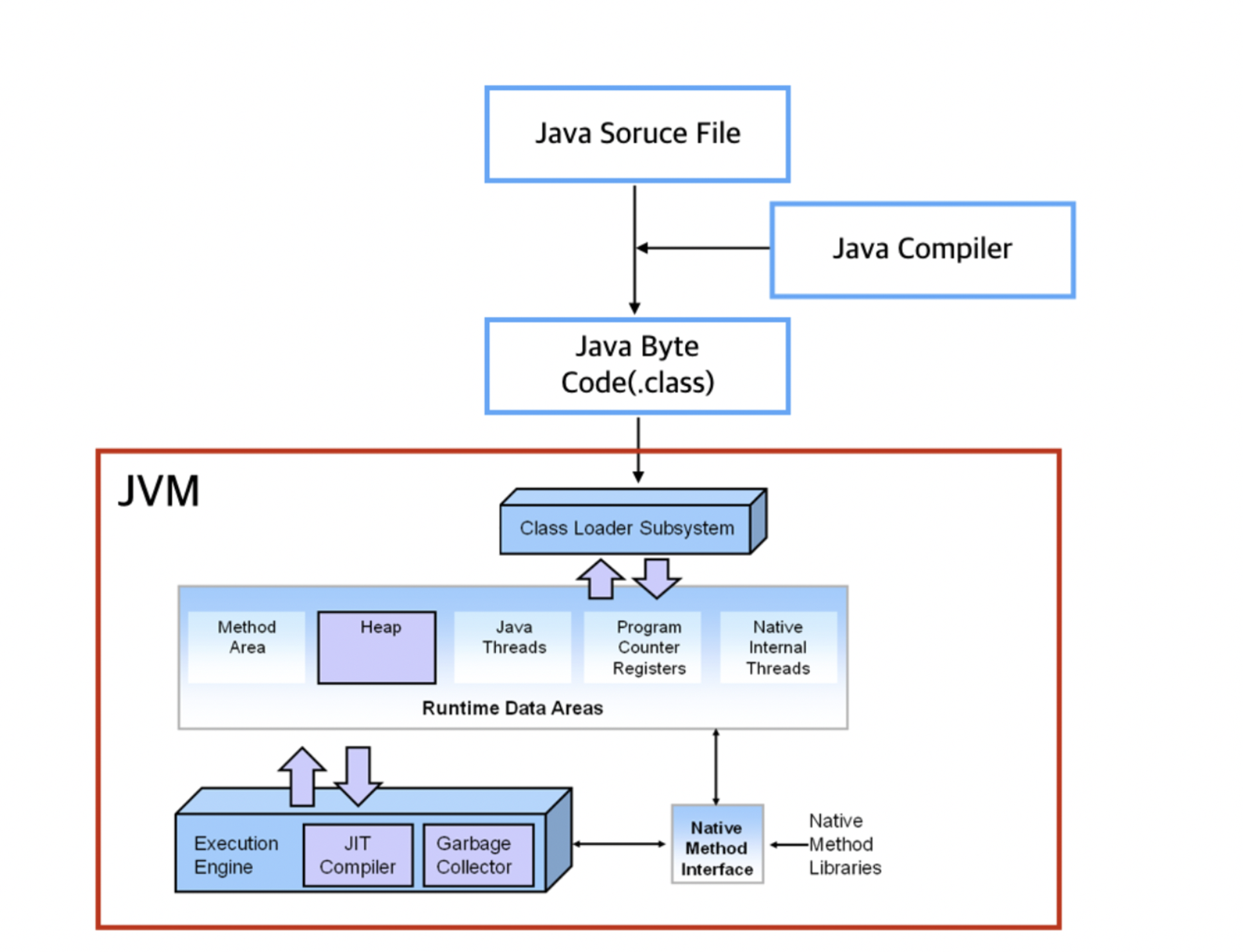
- 각각을 설명해 보겠습니다.
2-1. Class Loader
- 클래스 로더는 바이트 코드를 읽고, 클래스 정보를 메모리의 Heap, Method Area에 저장을 해주는 역할을 합니다.
2-2. Runtime Data Area
- JVM은 OS에게 메모리를 할당받은 후, 용도에 따라서 여러 영역으로 나누어 관리를합니다.
- 총 5가지 영역으로 나눌수있고, 쓰레드간 공유/비공유를 기준으로 나눌수 있습니다.
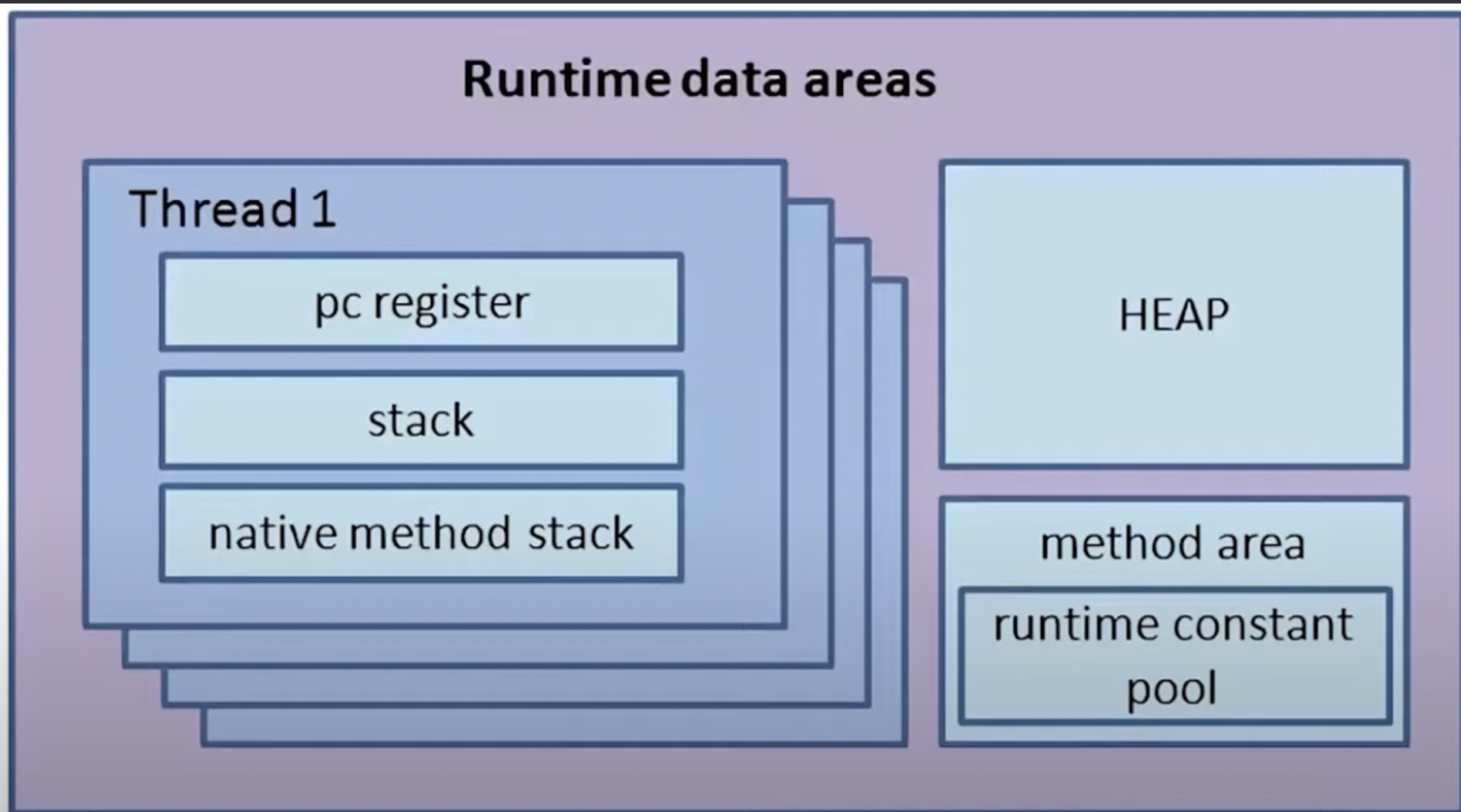
모든 쓰레드 공유 영역
- Method Area
- Heap Area
각 쓰레드 별 공유 영역
- Stack Area
- Pc Register
- Native Method Stack
Method Area
- 프로그램의 클래스 구조를 메타데이터 처럼 가지고 있고, 메서드의 코드(static변수, 인터페이스 등)를 바이트 코드 형태로 저장합니다.
Heap Area
- 어플리케이션 실행중 생성되는 객체 인스턴스를 저장하는 영역이고, GC에 의해서 관리가 되는 영역입니다.
Stack Area
- 메서드의 호출을 stack frame이라는 블록단위로 쌓으며 로컬변수와 중간 연산결과들이 저장되는 영역입니다.
PC Register
Stack Frame과 동일하게 스레드당 하나의PC Register가 존재하고, 현재 수행중인 메서드 안에서 몇번째 라인을 실행해야하는지 주소값을 가지고있는 역할을 수행합니다.
Native Method Stack
- C, C++등의 코드를 Low level코드를 실행하는 스택입니다.
- 네이티브 코드를 수행하기 위한 Stack으로, 자바언어가 아닌 다른언어 (C/C++등)를 통하여 Stack Frame이 생긴다고 하면
Stack Area가 아닌Native Method Stack에Stack Frame이 쌓인다. 이렇게 다른언어로 작성된 코드들을Native Method Library라고한다.- 성능향상을 위해서 사용된다.
2-3. Execution Engine
- 바이트 코드를 네이티브 코드로 변환시켜주고 GC를 실행하는 실행 엔진이다.
JVM Runtime Data Area에 배치된 바이트 코드는Execution Engine에 의해 실행됩니다.- 실행되는 방식은 명령어를 한줄씩 실행하는
interpreter방식과 실행시점에 자주 쓸만한 코드들을 기계어로 변역 후 저장하여 사용하는 방식JIT 컴파일러가 존재합니다.
-
JIT 컴파일러 vs interpreter
-
JIT 컴파일러
바이트코드를 머신코드로 변환하는과정에서 머신 코드를 캐시하게 됩니다. 이로인해 반복되는 기계어 변역을 줄이기 때문에 성능이 향상되게 되고, 런타임 시점에 코드 최적화 해준다.
JIT컴파일러가interperter방식보다 평균 성능이 10~20배가 향상됩니다. -
interpreter
캐시에 저장하기 때문에 실행하려는 바이트코드가 여러 번 반복되는 코드라면
JIT 컴파일러를 활용하여 많은 성능 향상을 볼 수 있겠지만, 한두 번 반복될 코드라면interperter의 방식으로 해석하는것이 효율적이다이러한 장단점 때문에 JVM의
Execution Engine은 두개의 해석 방식을 모두 사용합니다.
-
추가로 Excution engine에서 사용되는 GC는 아래 포스팅에서 확인이 가능합니다.
JIT 컴파일러의 warm up(성능 개선)
위에서 언급했듯이 JIT Compiler는 cache에 머신코드를 저장하지만 어플리케이션이 시작되는 시점에는 캐시에 데이터가 없습니다.
- 어플리케이션 로딩시점에 캐시에 데이터를 쌓는과정을 웜업이라고 하는데, 이를통해서 배포시점에 발생할수 있는 여럿 문제를 해결할수 있습니다.
warm up과 관련된 자세한 자료는 아래 링크에서 확인할수 있습니다.

나의 휘발성 메모리를 지키기위한 SSD