1. Firestore의 시작
회사에서 진행하는 신규 프로젝트의 기획이 자주 변경됨에 따라, 프론트에서 직접 api를 생성하여 원하는 형태로 데이터를 주고 받을 수 있도록 처리하기 위해 시작하게 되었다.
작업을 하면서 깨달은 중요한 3가지
데이터 설계를 하고 이를 기반으로 api를 짜는 것이 처음이었기 때문에,
- 클라이언트에서 용이하게 & 처리하기 쉽게 request 및 response 세팅하기 (리액트 쿼리처럼 커스텀 훅을 만들어 매개변수를 넣어 api를 트리거 하도록 처리하였다.)
- 재사용 및 확장성있게 데이터 및 api 설계하기
- firebase에서 배운 다양한 백엔드 지식들 (transaction 등..)
위의 3가지에 대해서 계속 생각하고 배우는 시간을 가짐으로써 서비스 개발의 전체적인 싸이클에 대해서 이해할 수 있었다.
글을 쓰게된 계기
3일전부터 작업을 하면서 위의 3가지를 유념하지 않고 개발을 했을 때, 작업이 더뎌지고 비효율성을 느끼게 되었다.
그래서, Firestore에 대한 학습 및 개발하면서 터득하게된 Firestore의 다양한 기능들 및 백엔드 지식들을 정리하고, 기존 서비스에서 어떻게 발전시켰는지 공유하고자 작성하게 되었다.
2. Firestore의 이해

Firestore는 Firbase에서 제공하는 클라우드 기반의 NoSQL 데이터베이스 서비스이다.
문서(document)와 컬렉션(collection) 구조를 기반으로 하며, 데이터를 JSON 형식으로 저장한다.
실시간으로 데이터를 동기화할 수 있는 기능을 제공하여 실시간 애플리케이션을 쉽게 개발할 수 있도록 도와준다.
주요 기능은 아래와 같다.
- 다양한 플랫폼 지원: 웹, 안드로이드, iOS 등 여러 플랫폼에서 사용할 수 있다.
- 실시간 업데이트: 데이터의 변경사항이 실시간으로 반영되어 사용자에게 즉각적인 피드백을 제공한다.
- 확장성: 대규모 애플리케이션에도 적합하며, 자동으로 확장되는 클라우드 인프라를 통해 안정적인 성능을 제공한다.
- 보안성: Firebase의 인증 및 권한 관리 기능을 통해 데이터의 안전성을 보장한다.
- 강력한 쿼리 기능: 다양한 쿼리 작업을 지원하여 데이터를 유연하게 검색하고 필터링할 수 있다.
- 오프라인 지원: 장치가 오프라인 상태일 때에도 데이터를 로컬에 캐시하여 사용할 수 있다.
Firestore 데이터 모델
SQL 데이터베이스와 달리 테이블이나 행이 없으며, 컬렉션으로 정리되는 문서에 데이터를 저장한다.
각 문서에는 키-값 쌍이 필드 형태로 들어있으며, 작은 문서로 이루어진 대규모 컬렉션을 저장하는 데 최적화되어 있다. (하단 이미지 참고)
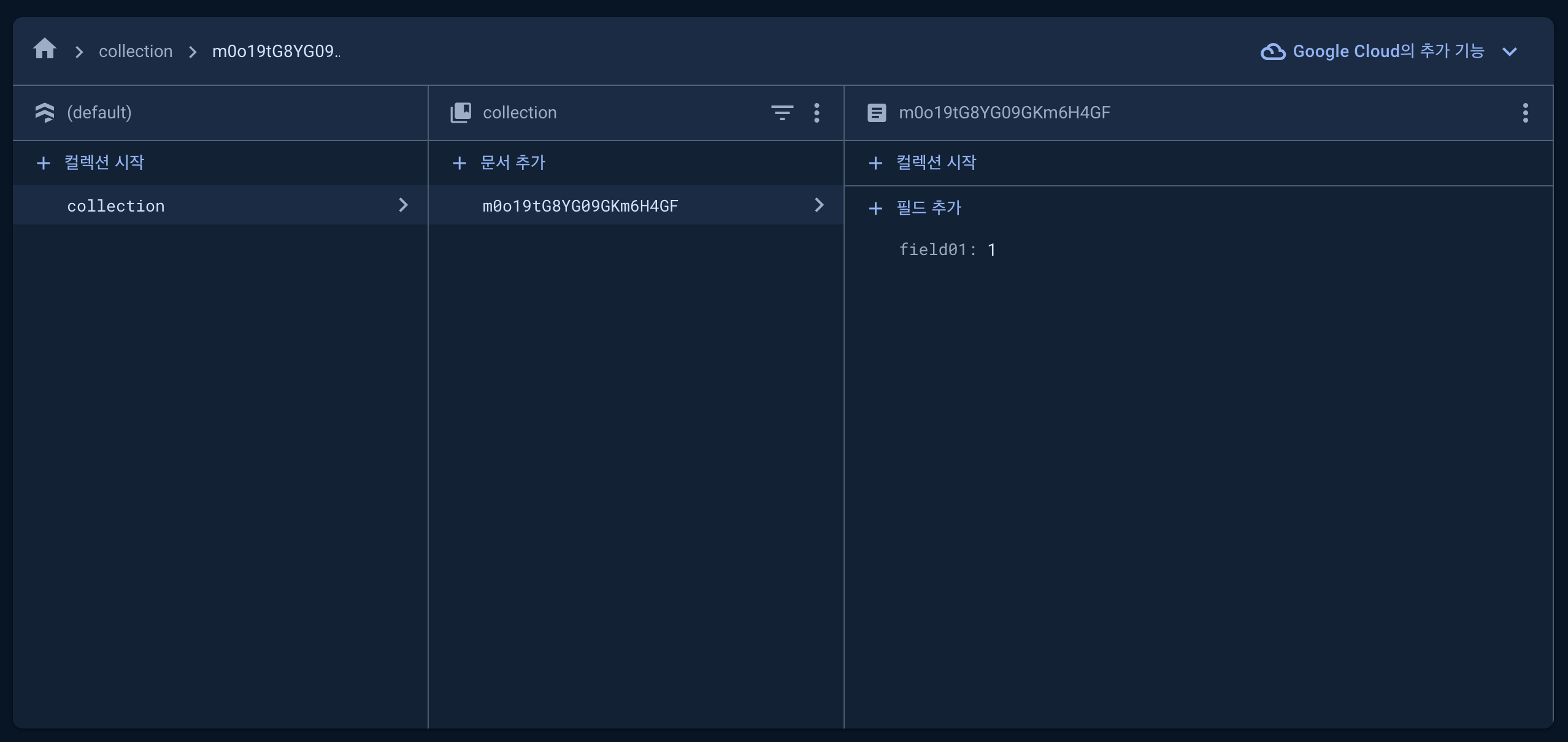
문서
Firestore의 저장 단위는 문서이다.
문서는 값에 매핑되는 필드를 포함하는 간단한 레코드로, 이름으로 식별된다.
위의 이미지처럼 m0o19tGBYG로 시작하는 문서는 field01라는 키값을 가진 필드를 가지고 있다.
m0o19tGBYG...
filed01 : 1아래 구조처럼 중첩된 객체를 맵이라고 하며, 이를 사용하여 문서 내에서도 데이터를 구조화할 수 있다.
m0o19tGBYG...
field01 :
first : 1
last : 2컬렉션
문서는 문서의 컨테이너인 컬렉션에 저장된다. 위의 이미지에서 collection이라는 이름을 가진 컬렉션이 이에 해당한다.
컬렉션 내의 문서 이름들은 고유하며, 사용자 ID와 같은 고유 키를 제공하거나 Firestore에서 임의 ID를 자동으로 생성할 수 있다.
컬렉션은 직접 ‘생성’ 혹은 ‘삭제’할 필요가 없다. 컬렉션의 첫 번째 문서가 만들어질 때, 컬렉션이 생성되며, 컬렉션의 모든 문서가 삭제되면 컬렉션도 삭제된다.
문서 참조하기
import { doc } from "firebase/firestore";
const documentRef = doc(db, 컬렉션명, 문서명);
// or
import { doc } from "firebase/firestore";
const documentRef = doc(db, `${컬렉션명}/`${문서명}`);컬렉션 참조하기
import { collection } from "firebase/firestore";
const collectionRef = collection(db, 컬렉션명);하위 컬렉션
Firestore에서 문서 내에 또 다른 컬렉션을 포함하는 개념이다.
기본적으로 Firestore는 앞서 말한것처럼 컬렉션 내에 문서를 저장하는 구조를 가지고 있지만, 문서 내에 또 다른 컬렉션을 추가함으로써 더 계층적인 구조를 만들 수 있다.
예를 들어, 온라인 상점 애플리케이션을 개발한다고 가정해 보자.
각 상점은 "상점" 컬렉션 내의 문서로 표현될 수 있다. 그리고 각 상점 문서 내에는 해당 상점에서 판매하는 제품 목록을 포함하는 "제품" 컬렉션을 추가할 수 있다. 이 경우 "상점" 컬렉션은 상위 컬렉션이 되고, "제품" 컬렉션은 "상점" 문서의 하위 컬렉션이 된다.
상점 (컬렉션)
│
├── 상점ID_1 (문서)
│ ├── 이름: "ABC 마트"
│ ├── 위치: "서울시 강남구"
│ ├── 전화번호: "010-1234-5678"
│ └── 제품 (하위 컬렉션)
│ ├── 제품ID_1 (문서)
│ │ ├── 이름: "노트북"
│ │ ├── 가격: 1500000
│ │ └── 재고: 20
│ └── 제품ID_2 (문서)
│ ├── 이름: "스마트폰"
│ ├── 가격: 1000000
│ └── 재고: 30
│
└── 상점ID_2 (문서)
├── 이름: "XYZ 매장"
├── 위치: "인천광역시 남동구"
├── 전화번호: "010-9876-5432"
└── 제품 (하위 컬렉션)
├── 제품ID_3 (문서)
│ ├── 이름: "텀블러"
│ ├── 가격: 20000
│ └── 재고: 50
└── 제품ID_4 (문서)
├── 이름: "가방"
├── 가격: 50000
└── 재고: 10
🧐 그렇다면, 필드를 계층 구조화하는 것과 하위 컬렉션을 생성하는 것의 차이가 무엇일까?
| 필드를 계층 구조화하는 것 | 하위 컬렉션을 만드는 것 | |
|---|---|---|
| 데이터 구조 | 단일 문서 내에 필드를 사용하여 계층 구조 형성 | 여러 문서 간의 관계를 나타내는 컬렉션을 추가 |
| 구조의 표현 방법 | 문서의 필드로 데이터를 표현 | 컬렉션을 추가하여 관련 문서를 그룹화 |
| 데이터 관리 | 단일 문서 내에서 데이터를 관리 | 별도의 컬렉션을 통해 관련 문서를 관리 |
| 관계 표현 | 단일 문서 내의 필드 간의 관계 | 여러 문서 간의 관계를 통해 관련 데이터 그룹화 |
| 쿼리 가능성 | 문서 내의 필드 값을 기반으로 쿼리 가능 | 컬렉션과 문서 간의 관계를 기반으로 쿼리 가능 |
| 유연성 | 단일 문서 내의 데이터 구조에 유연함을 제공 | 다수의 문서와 관계를 통해 데이터 구조를 유연하게 구성 |
🧐 어느 경우에 필드를 계층 구조화하는 것과 하위 컬렉션을 생성하는 것 중 선택해야할까?
필드를 계층 구조화하는 것의 예시:
가정: 단일 상점에 대한 정보를 관리하는 애플리케이션이 있다고 가정하자. 이 상점은 이름, 위치 및 제품 정보를 포함한다.
{
"이름": "ABC 마트",
"위치": {
"도시": "서울",
"구": "강남구",
"상세주소": "강남대로 123"
},
"제품목록": {
"노트북": {
"가격": 1500000,
"재고": 20
},
"스마트폰": {
"가격": 1000000,
"재고": 30
}
}
}위 예시에서는 하나의 상점 문서 내에 모든 정보를 담고 있다. 상점의 위치와 제품 목록은 중첩된 객체로 표현되어 있다.
하위 컬렉션을 만드는 것의 예시:
가정: 여러 상점이 있고, 각 상점은 여러 제품을 판매한다. 상점과 제품은 서로 다른 컬렉션으로 관리된다.
// 상점 문서
{
"이름": "ABC 마트",
"위치": "서울 강남구",
"전화번호": "010-1234-5678"
}
// 상점 문서의 하위 컬렉션인 제품
// 제품 문서 1
{
"이름": "노트북",
"가격": 1500000,
"재고": 20
}
// 제품 문서 2
{
"이름": "스마트폰",
"가격": 1000000,
"재고": 30
}위 예시에서는 "상점" 컬렉션과 그 안의 상점 문서가 있고, 각 상점 문서에는 하위 컬렉션으로 "제품"이 관리. 이렇게 하위 컬렉션을 만들면 각 상점의 제품 정보를 별도의 컬렉션으로 관리할 수 있다.
하위 컬렉션 참조하기
import { doc } from "firebase/firestore";
const messageRef = doc(db, 상위컬렉션, 상위 컬렉션 내 문서명, 하위컬렉션, 하위컬렉션 내 문서명);위의 방법을 적용하여 예시 내 상점 ID_1의 제품ID_2 에 접근하고자 한다면, 아래와 같이 해당 문서를 참조한다.
import { doc } from "firebase/firestore";
const messageRef = doc(db, "상점", "상점ID_1", "제품", "제품ID_2");
```참고 자료
Cloud Firestore 데이터 모델
