GROUP BY
GROUP BY를 사용할 때 SELECT 절에 사용할 컬럼은
GROUP BY로 묶은 컬럼 또는 COUNT(*), MAX(), MIN()과 같은 집계 함수들만 사용 할 수 있다.
이유는 GROUP BY로 묶은 SELECT 절에서 사용할 수 있는 컬럼들은 단순히 하나의 컬럼이 아니라 여러 컬럼들이라고 봐야하기 때문에 그룹화하지 않은 컬럼이 들어올 수가 없다.
다만 집계 함수의 괄호 ( ) 안에는 그룹화하지 않은 컬럼도 넣을 수 있다.
아래는 기본적이 GROUP BY 예시이다.
SELECT
gender
FROM table
GROUP BY gender;결과 값은
gender
m
f
이렇게만 있을 것이다. 마치 DISTINCT를 한 것 같은데 그 속은 전혀 그렇지 않다.
단순히 m 하나가 아니라 m 속에 m에 대한 여러 값이 들어있다고 봐야한다.
이를 확인하려면 count(*)와 같은 함수를 사용해보면 알 수 있다.
SELECT
gender,
COUNT(*),
AVG(height),
MIN(weight)
FROM table
GROUP BY gender;결과 ex)
gender count(*)
m 3.5
f 4.7
GROUP BY ( 2번째 )
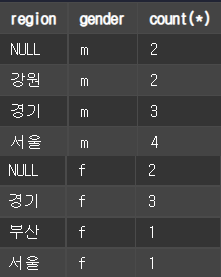
GROUP BY는 여러 개의 그룹으로도 묶어줄 수 있다.
SELECT SUBSTRING(address, 1, 2) AS region, gender, count(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender
ORDER BY gender DESC, region ASC;결과
GROUP BY HAVING
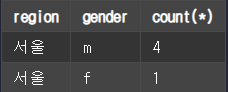
HAVING 절은 GROUP BY를 사용할 때 조건문 WHERE 대신 사용한다.
SELECT SUBSTRING(address, 1, 2) AS region, gender, count(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender
HAVING region = '서울'
ORDER BY gender DESC, region ASC;결과
WITH ROLLUP
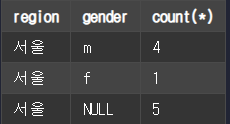
GROUP BY를 사용할 때 부분 총계를 나타낼 때 사용할 수 있다.
SELECT SUBSTRING(address, 1, 2) AS region, gender, count(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender
WITH ROLLUP
HAVING region = '서울'
ORDER BY gender DESC, region ASC;결과
출처
codeit
※ 문제가 될 경우 연락주시면 조치하도록 하겠습니다.

지식 쌓기