HA (High Availability) : 고가용성
HA는 시스템의 장애 상황시 연속적인 서비스를 제공할 수 있도록 하는 솔루션으로, 시스템 운영중의 발생하는 장애 상황을 극복한다.
- Active/Standby의 구조로 되어 이중화 구성이며, Failover 과정을 통해 넘어간다. (최근 기술은 DBMS, File, Block동기화 복제 지원)
개념에 필요한 용어
스플릿 브레인(Split Brain) : 특수한 상황 또는 네트워크 토폴로지를 갖는 Production 환경에서, 네트워크 파티셔닝 장애로 인해 시스템이 Sub-Cluster로 쪼개짐에 따라 각 Sub-Cluster가 스스로를 Primary 또는 정상적인 서비스라고 인식하는 것을 의미한다.
관제 시스템에 의해 heartbeat등으로 Alive 유무가 체크되는 서비스가 있다고 가정했을 때, heartbeat 통신이 단절되어 서비스 클러스터가 장애 상태라고 인식하고 서비스를 동시에 구동하는 경우, 또는 독립적인 두 개의 시스템이 비정상적으로 구성되어 서로가 Primary라고 믿게 되는 현상 등을 모두 포함한다.
heartbeat(핫빗) : os에서 장애발생시에 상태 체크를 하고 에러판단시 fence ip를 통해 fence에게 장애 소식을 알린다.
fence : 하드웨어 장치로 heartbeat에 의해 장애 판단을 받으면 fence가 장애 서버를 끈다.
→ Redhat에서 SplitBrain을 막기위해 사용되는 전략.
→ Passive 노드가 Cctive 노드로 부터 Heartbeat 신호를 받지 못하게 되면 Fence Device 를 통해 해당 노드를 Reboot 한다.
Active 노드를 재부팅 함으로써 Passive 노드는 Active 노드가 더 이상 실행되지 않음을 확인하고 안전하게 서비스를 시작하는 것이다
DRBD(Distributed Replicated Block Device) - 고가용성 클러스터를 구축하기 위해 디자인된 블럭 디바이스이며, 이 방식은 Network Raid-1로 동작을 하고, Raid-1의 일반적인 구성은 실시간으로 데이터를 백업하는 미러링으로 구성되어 있지만, 고가용성 클러스터에서는 Network를 통한 미러링을 구성한다.
→ 장애 발생시 Failover를 통해 데이터 복제를 한다고 이해하면 될듯.
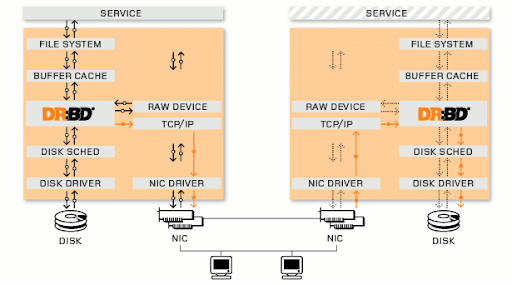
가동 원리
서버간의 데이터 동기화를 필요한 구성 구축 - 장애 발생시(N/W, H/W 등) - Acitve/Standby였던 구조 서버의 Failover 진행 - 데이터 동기화 및 서비스 이전 (서비스, 프로세스 등 지원)
