자료 구조란?
-
자료 구조란 데이터를 표현하고 저장하는 방법이다. 우리는 이미 데이터를 저장한 경험이 있다.
-
넓은 의미에서 int형 변수, 구조체, 배열도 자료 구조에 속한다.
-
자료 구조에는 선형 구조, 비선형 구조, 파일 구조(순차,색인, 직접 파일), 단순 구조(정수, 실수, 문자, 문자열)가 있다. 하지만 우리가 이번 16주간의 기간동안 다룰 자료 구조는 선형 구조와 비선형 구조이다!
-
선형 구조 : 리스트, 스택, 큐 - 자료를 표현 및 저장하는 방식이 선형(linear)이다. 즉 데이터를 선의 형태로 나란히 혹은 일렬로 저장하는 방식이다.
-
비선형 구조 : 트리, 그래프 - 비선형 구조는 데이터를 나란히 저장하지 않는 구조 이다.
-

-
자료 구조와 알고리즘은 밀접한 관계를 가진다. 자료 구조가 결정되어야 효율적인 알고리즘을 결정할 수 있기 때문이다. ⇒ 알고리즘은 자료 구조에 의존적이다(자료 구조에 따라서 알고리즘이 달라진다).
알고리즘의 성능 분석 방법
- 시간 복잡도(속도)와 > 공간 복잡도(메모리의 사용량)
- 시간 복잡도 표기법 :
1. 빅-오 표기법 : 상한 점근(최악의 성능)
2. 빅-오메가 표기법 : 하한 점근(최고의 성능)
3. 세타 표기법 : 평균(빅-오와 빅-오메가의 평균)

-
worst case를 중점으로 두고 시간 복잡도를 계산한다.
-
사실 데이터의 수 n과 그에 따른 시간 복잡도 함수 T(n)을 이용하여 정확하게 알고리즘의 성능을 구하는 것은 힘들다. 따라서 함수 T(n)에서 가장 영향력이 큰 부분을 따지는 빅-오 표기법(Big-Oh Notation)을 사용한다.
-
ex) T(n) = n^2 + 2n에서 n^2이 차지하는 비율
아래의 표를 보면 알 수 있듯이, n이 증가할수록 2n+1의 영향은 작아지고 n^2의 영향이 커진다. 그러므로 T(n) = n^2과 같이 간략하게 표현할 수 있다. 이를 빅-오 표기법으로 나타내면 O(n^2)이다. -
n n^2 2n T(n) n^2의 비율 10 100 20 120 83.33% 100 10,000 200 10,200 98.04% 1,000 1,000,000 2,000 1,002,000 99.80% 10,000 100,000,000 20,000 100,020,000 99.98% 100,000 10,000,000,000 200,000 10,000,200,000 99.99% -
빅-오 오브 n^2 ⇒ O(n^2)
-
빅-오 속도 - 오른쪽으로 갈 수록 시간이 오래 걸린다.
O(1) < O(log n) < O(n) < O(n log n) < O(n^2) < O(n^3) < O(2^n) < O(n!) -
1억번의 연산 => 1초, 10억번의 연산 => 10초

-
O(1) : 상수형 빅-오. 데이터 수에 상관없이 연산 횟수가 고정인 알고리즘. 연산의 횟수가 7회가 걸려도 O(7)이라고 하지 않고 O(1)이라고 한다.
자바 컬렉션(Java Collection)
- Java에서 컬렉션이란 데이터의 집합, 그룹을 의미하며 JCF(Java Collections Framework)는 이러한 데이터, 자료구조인 컬렉션과 인터페이스를 제공한다.
Java Collection 구조
- java.util 패키지에 선언되어있다.


Set, List, Queue는 Collection 인터페이스를 구현하고 있고,Map은 별도의 인터페이스로 선언되어 있다.
 java api 문서를 보면 알 수 있듯이 Collection은 아래와 같이 선언되어 있다.
java api 문서를 보면 알 수 있듯이 Collection은 아래와 같이 선언되어 있다.
public interface Collection extends Iterable
Collection은 Iterable을 extends 하고 있다. Iterable 인터페이스 안에는 Iterator이라는 메소드가 있다.
이 Iterator에는 3개(hasNext,next, remove)의 메소드를 확인 할 수 있다.

즉, Collection 인터페이스는 Iterator 인터페이스를 사용하여 데이터를 순차적으로 가져올 수 있다.
| List | Set | Map |
|---|---|---|
| 순서 O 중복 O | 순서 X 중복 X | (Key, value) 순서는 유지되지 않으며 key의 중복을 허용하지 않으나 value의 중복은 허용한다. |
| Vector ArrayList LinkedList | HashSet TreeSet | HashMap HashTable TreeMap |
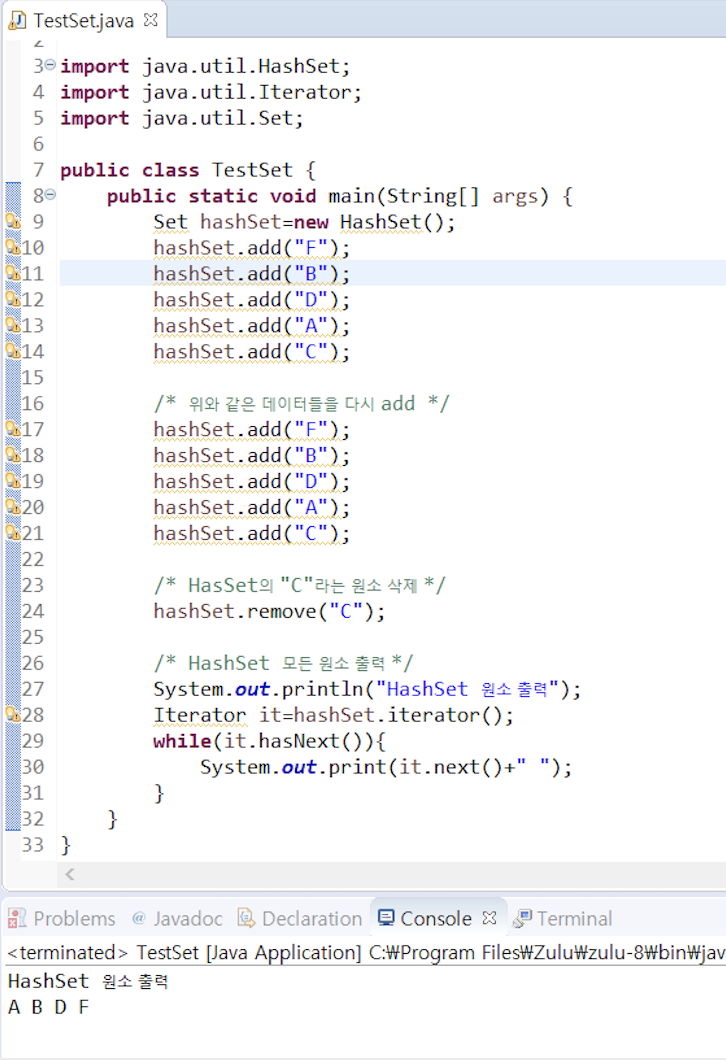
1. Set 인터페이스
순서를 유지하지 않는 데이터의 집합으로 데이터의 중복을 허용하지 않는다.
- HashSet : 가장빠른 임의 접근 속도순서를 예측할 수 없다.
- TreeSet : 정렬방법을 지정할 수 있다.
2. List 인터페이스
순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다. - LinkedList : 양방향 포인터 구조로 데이터의 삽입, 삭제가 빈번할 경우 데이터의 위치정보만 수정하면 되기에 유용스택, 큐, 양방향 큐 등을 만들기 위한 용도로 쓰인다.
- Vector : 과거에 대용량 처리를 위해 사용했으며, 내부에서 자동으로 동기화처리가 일어나 비교적 성능이 좋지 않고 무거워 잘 쓰이지 않는다.
- ArrayList : 단방향 포인터 구조로 각 데이터에 대한 인덱스를 가지고 있어 조회 기능에 성능이 뛰어나다.
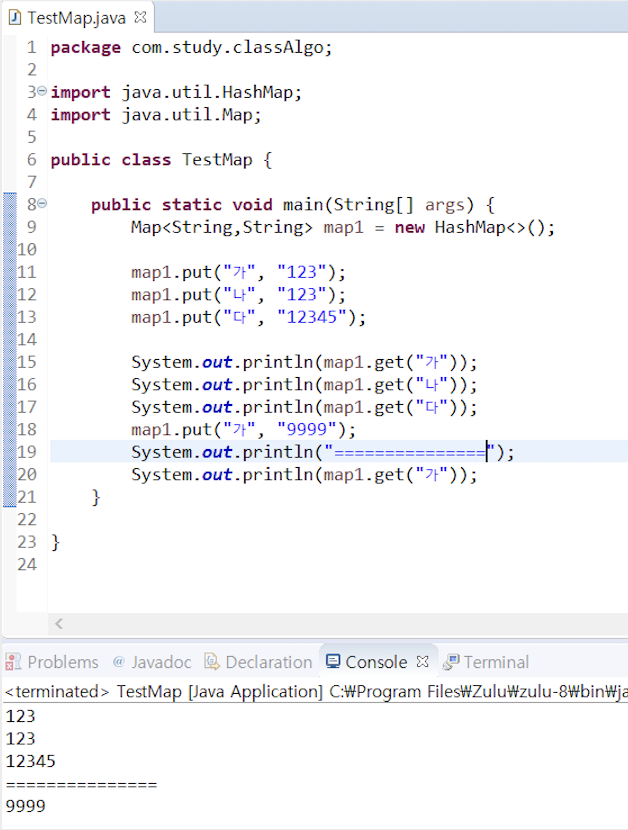
3. Map 인터페이스
키(Key), 값(Value)의 쌍으로 이루어진 데이터으 집합으로, 순서는 유지되지 않으며 키(Key)의 중복을 허용하지 않으나 값(Value)의 중복은 허용한다.
- Hashtable : HashMap보다는 느리지만 동기화 지원, null불가
- HashMap : 중복과 순서가 허용되지 않으며 null값이 올 수 있다.
- TreeMap : 정렬된 순서대로 키(Key)와 값(Value)을 저장하여 검색이 빠름
자료구조 시간 복잡도
-
그래프의 시간 복잡도

-
자료 구조의 시간 복잡도

-
정렬의 시간 복잡도

-
힙의 시간 복잡도
<img width="653" alt="스크린샷 2021-02-02 오후 7 17 03" src="https://user-images.githubusercontent.com/29567741/106585950-3ccf2500-658b-11eb-848f-a0009d98bc3c.png">
- 출처
- https://www.bigocheatsheet.com/
- https://gompangs.tistory.com/entry/알고리즘-시간복잡도Time-Complexity
- https://gompangs.tistory.com/entry/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EC%8B%9C%EA%B0%84%EB%B3%B5%EC%9E%A1%EB%8F%84Time-Complexity
- https://marcus-biel.com/java-collections-framework/
- https://docs.oracle.com/javase/8/docs/api/
- https://gangnam-americano.tistory.com/41
