
다형성은 그 생물 다형성에서 온 말이다.

다형성(多形性, polymorphism[1]), 다형(多形), 다형 현상은 생물학과 동물학에서 동종 개체들 가운데에서 2개 이상의 대립 형질이 뚜렷이 구별되어 나타나는 것을 말한다. 이러한 맥락에서 다면발현성(polyphenism)이라고도 한다.
computer science에서의 다형성
-
밝은 색 재규어와 어두운 색 재규어처럼, 근본적으로 다른 forms에 대해 같은 인터페이스를 제공하는 능력
-
computer 프로그래밍의 다형성에는 종류가 참 많은데 그 중에 내가 이 날씨가 좋은 주말에 읽어야할 것:
-
ad hoc
https://en.wikipedia.org/wiki/Polymorphism_(computer_science)#Ad_hoc_polymorphism
-> 다양한 타입의 인자를 지원하는 polymorphic 함수 -
subtyping
https://en.wikipedia.org/wiki/Polymorphism_(computer_science)#Subtyping
-> 수퍼클래스와 관련된 클래스들이 수퍼클래스 대신 사용될 수 있는 것
-
Ad hoc polymorphism
-
다형 함수는 그것이 적용되는 인수의 유형에 따라 구별된다.
-
이는 잠재적으로 이질적인 구현을 나타낼 수 있다.
-
객체지향이나 절차지향에서 함수 오버로딩/ 연산자 오버로딩으로 나타난다.
- ad hoc: 라틴어로 for this라는 뜻 => 임시라는 의미를 가짐
- 주로 일반화되지 않은 문제에 대한 급조된 해결책등을 언급할 때 사용한다.
- 얕잡는 뜻은 아니고 이러한 유형의 다형성이 유형 시스템의 근본적인 특징이 아니라는 사실을 의미한다.
parametic polymorphism과의 비교
- 매개인자 polymorphic function은 타입에 대한 언급 없이 쓰인다.
- 예: C++의 template functions
template <typename ANY> void swap(ANY &a, ANY &b) { // 구현 }
Early binding
-
dispatch 매커니즘
-
하나의 함수 이름을 제어하여 다양한 함수에게 전송할 수 있다.(정확히 어떤 함수를 호출 할지 특정하지 않고)
-
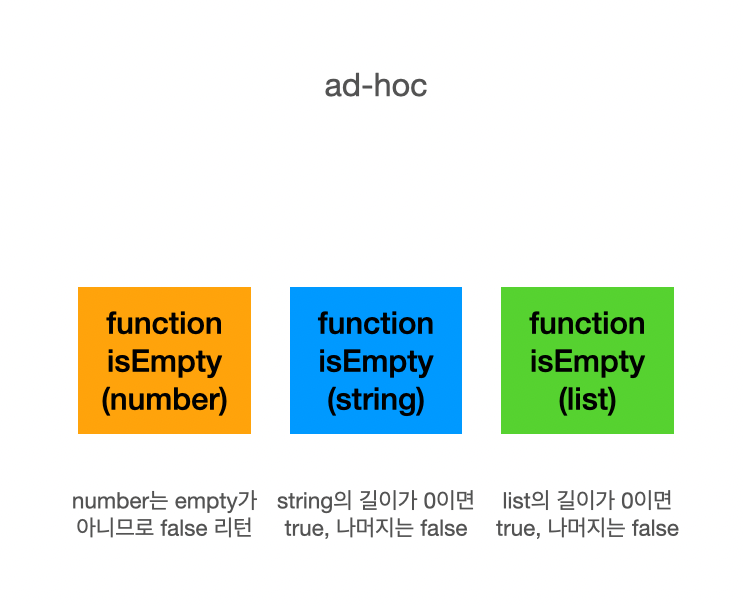
다른 유형의 여러 함수를 같은 이름으로 정의할 수 있게 함(예: 각 타입에 대해 구현된 isEmpty() 함수)
- isEmpty(number), isEmpty(string) ...
-
어떤 함수를 호출할지는 컴파일러나 인터프리터가 결정함
-
parametric polymorphic function은 모든 타입에 적용될 수 있는 generic한 함수를 써야함
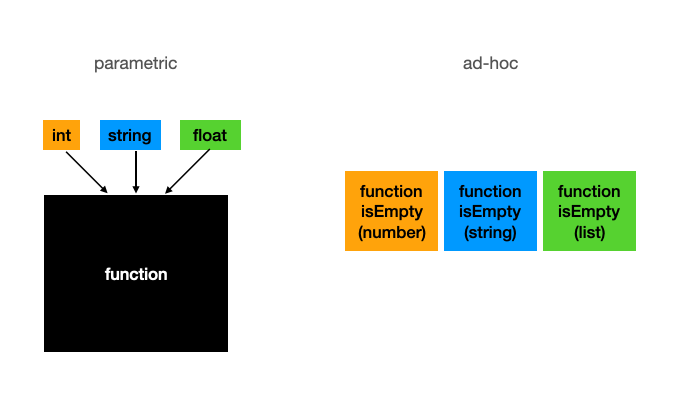
- 오버로딩을 사용하면 함수를 호출하는 컨텍스트에 따라 전혀 다른 동작을 이끌어낼 수 있다.
- 이것은 parametric polymorphism으로는 할 수 없는 일이다.
-
함수들은 이름으로 구분되지 않고 이름과 매개 변수의 개수, 순서 및 유형의 조합으로 고유하게 식별됨
-
OOP에서 이런 타입의 polymorphism은 일반적이다. 많은 경우 연산자 오버로딩이 (함수처럼) 가능하다.
-
참고: 동적 타이핑되지 않고 ad-hoc polymorphism을 사용하지 않는 경우 필요한 함수들을 isEmpty_number, isEmpty_string 과 같이 사용한다.
-
장점: 여러 상황에 특화된 코드를 같은 함수이름으로 작성할 수 있고, 특정 데이터 유형에 최적화된 코드를 작성할 수 있다.
-
단점: 구현의 일관성을 보장하지 않을 수 있음
-
이 오버로딩은 컴파일 시간에 수행되기 때문에 late binding을 대체할 수 없다.
Late binding
-
ad-hoc 다형성이 다르게 동작하는 방법이 있다.
-
smaltalk 언어를 예로 들자. smaltalk에서는 오버로딩이 런타임에 일어난다. 각 오버로드된 메세지들은 실행될 때 resolve된다.
-
이런 이유를 자세히 들여다보자.
-
smaltalk의 ad-hoc 다형성은 다른 언어들과 조금 다르다.
-
스몰토크는 늦은 바인딩 실행 모델을 가지고 있고, 이해되지 않는 메시지를 객체에 처리할 수 있는 기능을 제공하기 때문에 특정 메시지를 명시적으로 오버로드하지 않고 다형성을 사용하여 기능을 구현할 수 있다.
-
일반적으로 권유되지 않지만, 프록시를 구현할 때 상당히 유용하다.
-
또, 일반적으로 class 메소드나 생성자 오버로드는 다형성으로 보지 않는데,class가 regular 객체인 uniform 언어가 있다.
-
예를 들면, smaltalk에서는 class가 일반 객체이다. 클래스에 보내는 메세지를 오버로드할 수 있고, 상위 클래스를 상속하지 않고 클래스 처럼 동작하는 객체를 만들 수 있다.
-
이것이 smaltalk의 강력한 reflection 능력을 가능하게 한다.
Subtyping
=== subtype polymorphism === inclusion polymorphism
- 프로그래밍 언어 이론에서 서브타이핑(subtype)이 다른 데이터형(supertype)과 어떤 치환가능성의 개념에 의해 관련되는 데이터형(supertype)의 일종
-
S가 T의 서브타입일때, T가 예상되는 모든 컨텍스트에서 S가 안전하게 사용될 수 있음
-
결국 이 다형성은 "모든 컨텍스트", "안전하게 사용되는"의 의미에 의존한다.
-
프로그래밍 언어의 타입 시스템이 subtype 관계를 정의한다. 언어가 conversion type을 지원하지 않을 경우 사소해질 수 있다.
-
subtyping 관계 때문에, 항(term)이 하나 이상의 타입에 속할 수 있다.
-
그러므로 sutyping은 type 다형성의 한 종류이다.
-
OOP에서 polymorphism을 말하면 보통 이 다형성을 말한다.
(C++ 같은 generic 프로그래밍에서 보통 parametric 다형성을 말하는 것 처럼 - STL은 제네릭 프로그래밍의 핵심) -
서브타이핑을 OOP의 상속 관계와 혼동해서는 안된다.
- 서브타이핑: 인터페이스(유형)간의 관계(interface inheritance)
- 상속: 기존 객체에서 새로운 객체를 만들어낼 수 있는 언어 기능에서 비롯된 구현관계(implementation inheritance)
기원
- 객체지향에서 주류로 채택됨(일부에서 다형성과 동의어로 쓰기도 함)
- 안전 치환 원칙은 이를 대중화한 리스코프의 이름을 따서 리스코프 치환 원칙이라 부름
예시

-
위 그림에서 사용한 표기기법은 UML인데, 하늘을 향해 열린 화살표는 bird가 supertype, 나머지가 subtype임을 보여준다.
-
float가 예상되는 곳에 integer를 사용하는 것이 허용되는 언어가 있을 수 있고 또는 Number라는 제네릭 타입을 숫자 타입의 전반의 일반적인 supertype으로 사용할 수 있다.
- 두번째 경우에서는 Integer <: Number, Float <: Number 관계가 생기지만, Integer와 Float은 서로 아무 관계가 없다.
-
프로그래머는 서브타이핑을 이용해서 좀 더 코드를 추상활 할 수 있다.
하위집합
-
타입이론에서 하위집합은 S가 T의 서브타입인지 평가하기 위해 사용된다.
-
타입이란 값들의 집합이다.
- 집합은 모든 값들을 나열하는 것으로 묘사될 수 있다.(extensionally)
- 또는 가능한 값의 영역에 대해 자격을 서술함으로써 묘사될 수 있다.(intensionally)
-
일반적으로 프로그래밍 언어에서 타입은 값들을 listing 함으로써 확장하여 정의된다.
-
구조체나 interface같은 사용자 정의 타입들, 혹은 classes는 이미 존재하는 값들을 사용해서 의도적으로 정의된다.(프로토타입을 복사 혹은 확장함으로써)
-
표기법
T: 타입의 값들의 집합
T: 타입
<:: is subtype of
:>: is supertype of -
T는 S를 포함한다.
- 값들의 집합이 T 정의되어있고, S 의 상위 집합이라면
- 모든 S 의 멤버가 T 의 멤버가 될 수 있다.( S ⊆ T )
-
어떤 타입이 하나이상의 타입을 포함할 수 있다.
-
만약에 S가 T의 서브타입이면, ( S ⊆ T )
- T 를 제한하는 서술어 T는 S 를 정의하는 S의 일부여야 한다.
-
만약에 S가 T를 포함하고 S가 T를 포함한다면, 두 타입은 같다.
- 이름이 다르면 다른것으로 간주하는 시스템에서는 다르게 볼 수 있다.
-
서브타입이 수퍼타입에 비해 많은 정보를 가지고 있으므로 구체적이라고 여겨진다.
-
서브타입이 더 많은 정보를 가지기 때문에 가지는 단점은 만연하는 서브타입들을(그것을 생성하거나 만들 일의 수를) 줄이는 선택들을 포함하여 나타낸다는 것이다.
-
하위집합의 관점에서, 타입 정의들은 집합들을 정의하는데 서술어를 사용하는 Set-builder 노테이션으로 나타낼 수 있다. 서술어는 가능한 값들의 집합(도메인, D)을 넘어 정의될 수 있다.
-
서술어(predicates)는 값을 선택기준과 비교하는 부분 함수들이다.
- integer 값이 100보다 크거나 같고 200보다 작은가?와 같은 것
- 이 비교와 일치하면 값을 리턴하고, 그렇지 않으면 리턴하지 않는다.
-
이런것을 List comprehensions라고 하고 이런 패턴은 많은 프로그래밍 언어에서 쓰인다.
- 두개의 서술어가 있다고 가정하자.

-
T 타입에 대한 서술어는 S 타입에 대한 서술어의 일부로 나란히 놓여있다.
-
S 타입이 되려면 두가지 조건을 모두 만족해야한다.
-
그래서 S는 T의 서브타입이다.
-
S에 속하는 값은 T에도 속한다.
Relationship with inheritance
- 서브타이핑과 상속은 독립적인 관계이다.
- S는 T의 하위 유형도 파생 유형도 아닙니다.
boolean과 float의 관계를 보자. 그것들은 서로 하위유형도, 파생유형도 아니다.
- S는 하위 유형이지만 T의 파생 유형은 아닙니다.
int32, int64를 보자. 거의 대부분의 OOP언어에서 int64는 int32를 상속하지는 않는다.
하지만 int32는 int64의 서브타입이 될 수 있다. 왜냐면 어떤 32bit int 값이라도 64bit int 값으로 프로모트 될 수 있다.
- S는 하위 유형이 아니라 T의 파생 유형입니다.
객체를 리턴하는 메소드 m을 가지는 T 클래스, 그리고 S가 T를 상속할때
만약에 S가 하위 유형이 되려면 S의 m이 T의 m의 하위유형이어야 한다.
그런데 이 예시에서는 m이 this(self)를 첫번째 parameter로 받으며 같은 타입의 객체를 리턴한다고 가정하고 있다.
따라서 이 경우는 S의 m이 T의 m에 속하려면 두 타입이 같아야함을 의미한다.
하지만 상속은 재귀적인 관계가 아니므로(서로 같지 않다는 뜻), S는 T의 서브타입이라고 할 수 없다.
- S는 T의 하위 유형이자 파생 유형이다.
만일 S의 모든 메서드와 fields가 T의 하위유형 일때
위키에서는 상속과 하위유형을 구분하고 있는데, 일반화된 리스코프 치환원칙 관련해서 이야기할때 상속에 대해서도 subtyping polymorphism으로 설명하는 것 같다.
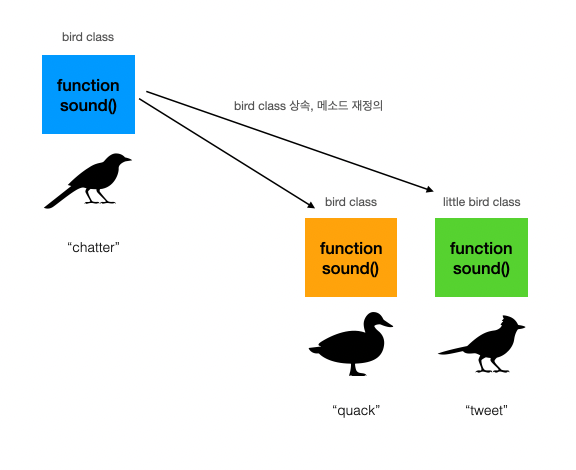
- 내용보강: JS에서는 Object가 toString 메소드를 가지고 있고, 이 메소드를 다른 클래스에서 상속하여 타입마다 구현하는데 이것은 subtyping에 해당한다.
