Multi-head Attention
self-attention block이 무수히 있는 block으로 아래의 그림처럼 self-attention을 알아야만 이해가 가능하다. (여기서 self-attention이란 Scaled Dot-product Attnetion과 같은 개념이며 왜 Scaled Dot-product로 불리는지는 뒤에서 설명하겠다.)
Self-attention
문장을 이해하기 위한 문맥적 정보와 단어의 값어치를 한번에 Sequential한 속성을 잃지 않고 볼 수 있는 연산 방식으로 영문으로는 "Comparing sentences with themselves"로 설명한다.
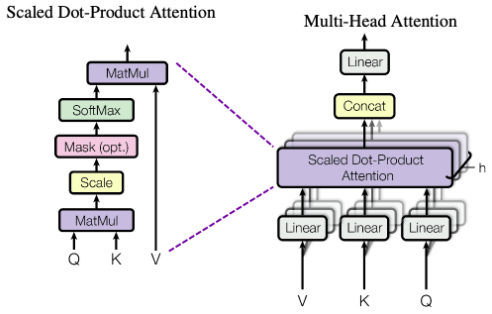
Query, Key, Value 3가지 가중치가 필요하며 첫번째 사진 왼쪽의 그림처럼 총 4가지 단계로 구성되어 있다(opt.는 말그대로 옵션이며 사용한다 해도 attention value행렬을 구하는 단계에선 생략가능하다.).
- 1차 MatMul (Query와 Key의 내적)
- Scale (수치 조정, Scaling)
- SoftMax (Softmax 함수화)
- 2차 MatMul (QK와 V의 내적)
다음과 같은 단계로 하나씩 뜯어보자.
1차 MatMul
우선, 내적의 정의를 보면 두 벡터의 방향이 일치하는 정도 또는 식의 유도에 따라 얼마나 두 벡터가 유사한지에 대한 정보를 알기 위한 연산으로 볼 수 있다.
따라서 Query와 Key행렬의 내적은 Query 원소 하나하나(단어 하나하나)가 Key에 해당되는 다른 모든 단어들과 얼마나 유사한지 논문의 표현을 빌리면 "관련성"정도를 나타낼 수 있습니다.
여기서 내적을 하기 위해서는 행렬의 성질 때문에 Query의 열과 Key의 행 차원이 맞아야 연산을 할 수 있는데, 여기서 얻어지는 Query, Key 가중치는 문장의 길이 x 벡터의 차원입니다. 예시로 문장이 "밥먹고 양치하는 나"라고 가정하면 단어별로 분리했을 때, 기준으로 "밥, 먹다, 양치, 나"로 총 4의 길이를 가지고 있는 문장입니다. 벡터의 차원을 임의로 64라고 가정하면, 4x64를 가지는 Q,K 행렬이 생성됩니다.
행렬의 성질을 이용하여 Key 행렬을 Transpose하여 64x4의 행렬을 만든 후 내적을 하게 되면 4x4 행렬을 갖게 됩니다. 이 행렬을 우리는 Attention Score라 할 수 있습니다.
Scale
얻어진 AttentionScore 행렬의 원소값이 너무 크면 너무 값이 치중되었을 경우나, 학습 시 기울기 연산이 매우 어려워질 가능성이 있다. 특히, 문장의 길이가 길어져 max_length를 더더욱 높이는 방향으로 연구가 진행되고 있는데, 내적의 연산에 따라 숫자가 커지게 된다. 따라서 값에 영향을 전역적으로 미치는 값으로 나눠줘 행렬 크기 자체를 줄여버리는 방식이 있는데, All you need is attention에서는 임의의 벡터 차원의 루트로 나눠준다.
따라서, 다음과 같이 나타낼 수 있다.
Softmax
한 단어에 대해서 어떤 토큰(단어)이 관련성이 높고 유사한지 알기 위해선 단어 별 Attnetion Score보단 Softmax함수를 취해 확률로써 나타내는 것이 선택하기 쉽다. 여기서, 이전 단계에서 scaling이 되지 않았을 경우 Softmax함수에 의해 미세한 값들은 너무 작아지고, 학습 단계에서 기울기가 소실될 가능성이 높다. 따라서 Scaling과 Softmax의 단계 서순은 달라지면 안된다는 부분이다.

2차 MatMul (QK와 V의 내적)
이후 얻어진 문맥적 정보와 단어 하나하나가 가지고있는 가치에 대한 합산이 이뤄지면 문장의 구조를 전부 이해한 한번의 연산이 이뤄지는데 이것을 Self-Attention이라고 한다.

Reference
Deeplearning Bible 3 - https://wikidocs.net/162098
