BIG QUESTION
딥러닝을 배우면서 CNN모델에 대해 배웠다. 초기에 나는 컴퓨터가 대체 이미지를 어떻게 인식하는 지 이해가 안됐다. Grayscale? RGB? 이미지 강도? 이것들이 어떻게 고양이를 고양이라고 인식하는 것인가......?
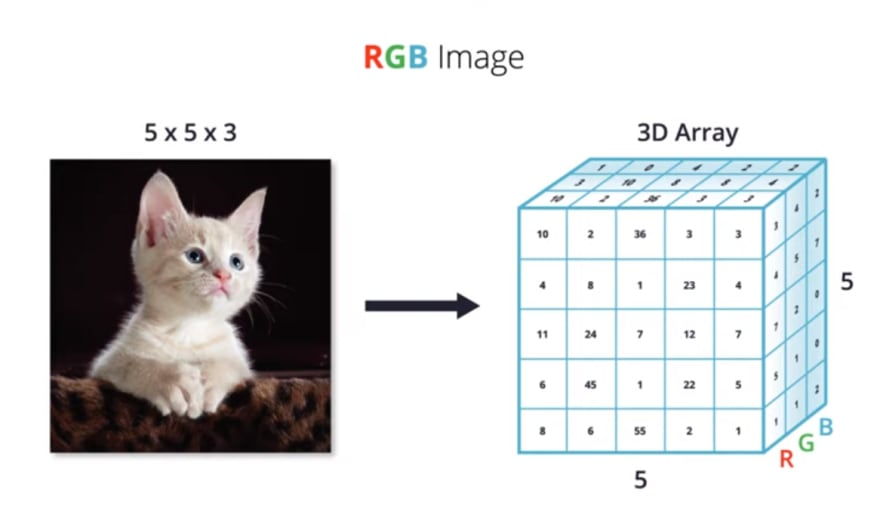
위 사진을 보면 553 크기의 하얀색 고양이 이미지를 RGB 값으로 표시해준다. 저 수치들이 무엇을 뜻하는거지? 라 묻는다면 대답은 늘 "이미지 강도다!" 였다.
아니 그래서 저 이미지 강도가 어떻게 고양이를 표현하는 것이냐? 그렇다면 다른 색상의 똑같은 사진을 모델에 입력하면 컴퓨터는 과연 그 사진이 똑같다는 고양이라는 것을 아는 것인가? 고양이를 [8, 1, 23], [24, 7, 12], [45, 1 ,22] 과 같은 수치(이미지 강도로) 인식이 가능하다고?
그렇다면 모든 고양이 손은 비트와 같은 수치로 정해져있는 것인가?
정답
간단하게 요약해서 말하자면 이미지 강도는 그져 밝기일 뿐이다. 그 안에 담긴 내용물 얼마나 밝은 지, 어두운 지만 나타내는 것이다. 일단 n*n 픽셀에 담긴 내용물(예. 손) 따로 그리고 이미지 강도 따로 존재한다고 설명을 하겠다.
보통 딥러닝 기초 강좌들을 보면 553, 773과 같이 작은 크기의 input 이미지를 예시로 든다. 하지만 우리가 모델을 훈련하거나 테스트할때 사용하는 실제 이미지들의 크기는 그보다 훨씬 크다. 553 크기의 고양이 이미지 속에 있는 하나의 픽셀에는 2272273 크기의 고양이 이미지보다 훨씬 더 많은(?) 내용물을 담고 있을 것이다.
윗 사진을 보면 4 * 3 픽셀이 고양이의 손 전체를 담고 있다. 그리고 그 강도는 1이라고 한다. 이 부분에 대해서 짚고 넘어갈 부분이 있다. 이미지 강도는 0~255 range 의 값들로 표현이 되는데 0에 가까울 수록 어둡고 255에 가까울수록 밝다. 따라서 위 예시는 그냥 대충 아무 수치를 집어 넣었을 확률이 크다. 저런 예시들이 하두 많아서 공부를 하면서 많은 시행착오를 겪었다.
본론으로 돌아가자면 실제 큰 크기의 이미지 속 픽셀들은 정보를 얼마나 담고 있을까? 553 크기의 사진을 10248003 으로 확대시키면 과연 하나의 픽셀이 손 전체를 담고 있을까? 물론 가능하긴 하다. 손이 매우 작다는 가정하에 말이다. 만약 윗 사진을 그대로 늘린다면 어떨까? 아마 똑같은 손을 담는데 몇십개 혹은 몇백개의 픽셀이 필요할 수 있을 것이다. 여기서 필자가 말하는 것은 하나의 손을 확대하면 몇십개의 픽셀들로 구성이 되어 있고 그 픽셀들은 작은 선, 굴곡, 혹은 다른 아주 작은 정보들을 담고 있을 것이다.
정확한 답은 아니지만 CNN은 이미지 내 모든 점들을 융합해 하나의 모양을 생성해 feature들을 추출한다고 일단 이해를 해보자! 이게 무슨 말이냐? Edge Detection을 알게 되면 모든 의문이 풀릴 것이다.
Edge Detection
앤드류 웅 교수님의 Computer Vision, Edge Detection 영상을 보자마자 모든 궁금증이 풀렸다.
앞서 말하지만 Feature Extraction을 이해하기 위해서 합성곱 원리부터 먼저 알아야된다. 모른다면 이것부터 먼저 보고 올 것을 추천한다.
Feature extraction (특징 검출은)의 핵심은 filter(kernel)이다. Filter들이 사진을 스캔하며 특징들을 검출하는 역할을 한다. 그리고 사진 내 receptive field와 filter간의 합성곱연산을 수행해서 나온 activation map이 해당 receptive field 속 특징을 뽑아온 '정보 덩어리'라 이해해도 괜찮을 것 같다. 다시 말해 합성곱연산을 하여 특징을 뽑기 때문에 합성곱 인공신경망이라 부르는 것이다.
쓸데 없는 소리는 그만하고 바로 edge detection을 설명하겠다

예시로 5*4 의 이미지가 있다고 가정을 해보자.
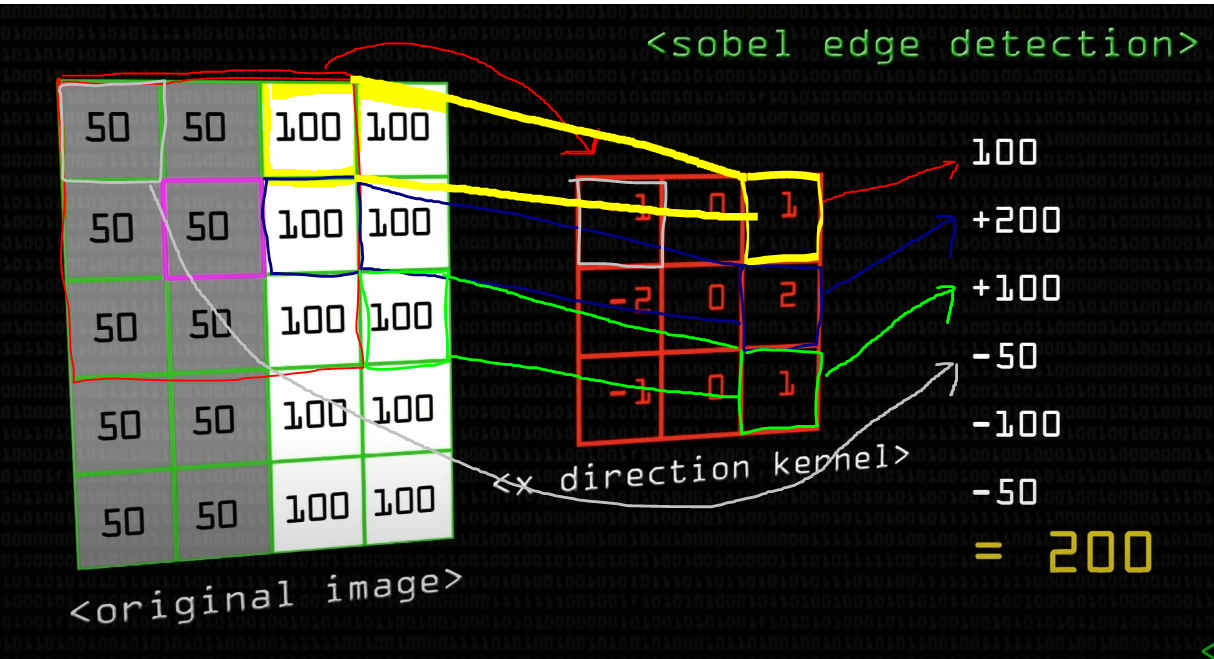
사진 중간을 보면 수직선을 검출하는 sobel filter 가 있다.
해당 3*3 필터로 왼쪽 사진에 합성곱 연산을 하면 어떤 값이 나오는 지 계산을 해보자.
합성곱 연산
1. 우상 --> 우하 (100 1 + 100 2 + 100 1)
2. 중간은 2 1 ~ 2 3은 모두 가중치 0으로 곱하기 때문에 값이 없고 ( 0 50 + 0 50 + 0 50)
3. 좌상 --> 좌하 (50 1 + 50 -2 + 50 * -1)
모든 값들을 더하면 200이란 값이 나온다
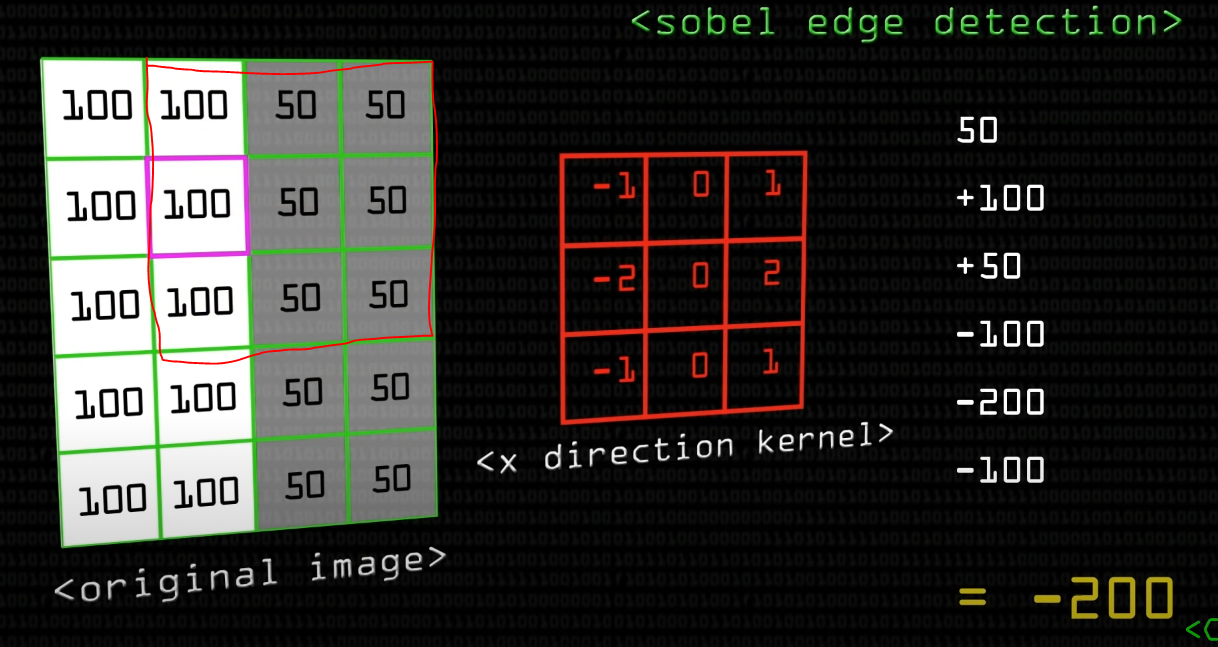
그리고 그 다음 receptive field에 대해 filter로 합성곱 연산을 수행해주자
모두 하면 최종 200이란 값이 또 나온다
결론은 모든 합성곱 연산을 다하면 좌측은 모두 200 ([200, 200, 200]이고 우측은 모두 -200[-200,-200,-200] 인 3 * 2 activation map이 나올 것이다. 이게 어떻게 보일까? 하나의 수직선으로 보일 것이다. 이해가 안된다면 바로 연산을 해서 보면 알게 될 것이다. 직접 연산을 수행해서 이것이 빛의 강도라고 생각하면 한쪽이 매우 어둡고 반대쪽은 배우 밝은 activation map을 보게 될 것인데 그 양측의 대조되는 밝기로 중간에 수직선이 하나 나오는 것을 알게 될 것이다.
물론 현실 속 우리가 학습하는 사진들은 모두 이와 같이 단순하지만 않을 것이다. 그래서 머신 러닝에서는 수직선만 뽑는 필터가 아닌 수평선, 대각선 등 다양한 요소들을 검출하는 filter들을 사용자가 직접 설정하여 모델을 돌린다. CNN은 해당 필터의 모든 w들이 무작위의 값으로 시작하여 모델이 올밣은 w를 찾을 때까지 학습을 지속적으로 돌린다. 이 모든 것은 사람의 손길 없이 CNN 모델 본인이 알아서 수행하는 것이고 이 또한 머신러닝 모델과 딥러닝 모델의 차이점이라 얘기할 수 있다.

위는 오른쪽 사진에 수직선을 뽑는 filter로 돌렸을 때 얻은 형태이다

위는 오른쪽 사진에 수평선을 뽑는 filter를 돌렸을 때 얻은 형태이다
여기서 질문: sobel filter 한번만 돌렸다고 저런 형태가 나온다고?
바로 저런 형태가 나오는 것은 아니다. CNN은 여러 layer들로 구성되어 있는데 하위 레이어(초기 레이어)들에서는 아주 작고 미세한 선부터 뽑아서 레이어가 깊어지면 깊어질수록 이 선들이 조합을 이루기 시작하여 나중에는 하나의 모양을 지난 형태를 형성하게 된다. 이부분은 backpropogation을 배우게 되면 더욱 명확해 질 것이다.
또 다른 질문: 수직선, 수평선, 대각선과 같은 특징들만 뽑는 것이냐?
그것은 아니다. 머신러닝은 다양한 fitler들이 존재하고 머신러닝 모델에서는 우리가 해당 filter들이 어떤 특징을 뽑을 지 직접 설정을 해준다(w값들을 지정해준다). 하지만 CNN에서는 모델이 스스로 filter내 weight값들을 찾아내기 때문에 CNN이 어떠한 filter들을 사용하는 지 우리는 단순 추측만 할 수 있다.
