Day 3
for 문
for i in my_list:
print("값 : ", i) --> i 는 리스트(출처)내 값들과 동들어 출력 [ ex. print('값 : ', i) = 값 : i(1), 값 : i(2)
이중 for 문
for 안에 또 for
append() : 덧붙이다, 첨부하다
list(range(1, 10, 2)
list comprehension: for문 속 for문을 더욱 간편하게 사용하기 위한 수단 같다
각 리스트별로 일일히 코드를 짜는 등 append()와 같은 함수를 안 넣고 한줄에 result_list = [(i, j) for i in range(2) for j in my_list] 식으로 해결
제너레이터(Generator)
--> 많은 양의 데이터를 처리하는데 편리함을 주는 것..? 데이터내 for문을 2번 사용하면 많은 양의 메모리가 올라오고 그중에서 또 데이터를 추리기 위해 for를 한번 더 사용할 수 있게 해준다?
len() 함수: 수량을 카운트 [예. generator 속 글자수 or 데이터갯수?]
format() 함수: 문자열 내 지정한 {} 안에 format()로 각각 값을 넣어준다, 다른 변수에 저장된 값을 가져오는 것도 가능하다, 순서를 지정해주는 것도 가능
,^, --> 각각 왼쪽 정렬, 가운데 정렬, 그리고 오른쪽 정렬을 의미한다

>> : 오른쪽 shift <<:: 왼쪽 shift
오늘 나를 고뇌하고 고생시킨 놈 --> yield()
yield()는 코드의 순서를 양보해준다 --> 양보해준다는게 무슨 의미인가? yield 앞에 나오는 첫 print를 뒤로 미뤄서 그다음에 나오는 print 뒤에 출력을 해준다!!!
코드 블록의 개념을 이제서야 이해....
8-3 노드
enumerate(): --> 리스트의 값과 함께 리스트내 순서를 함꼐 출력해준다
for i, value in enumerate(my_list):
print("순번 : ", i, " , 값 : ', value) --> value 에 해당 순번의 데이터 값이 나온다
note: 여기서 i가 순번, value가 list내 해당 순번의 값을 출력한다. 순번, 값은 그져 추가된 문자열, 즉 i와 value의 값이 뭔지를 설명하기 위해 임의적으로 추가한 것이다.
8-4 노드
try - except
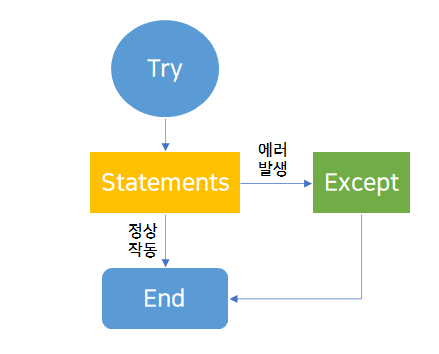
8-5 노드
Multiprocessing
병렬 처리 & 순차 처리
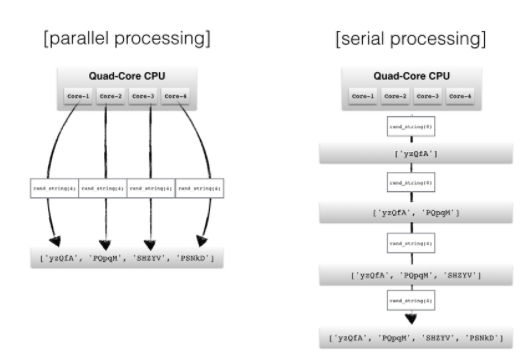
코드 시작점을 알리는 코드
if name == == 'main':
pool - multiprocessing.Pool(processes=4):
pool.map(count, num_list):
pool.close():
pool.join():
8-6 노드
8-7 노드
8-8 같은 코드 두번 짜지 말자! [lambda]
익명 함수...(?)
1 - 함수 이름, 입력값들을 정의
2 - return을 사용해 결과를 반환
Python Master
append과 extend의 차이: 둘다 두개의 리스트를 합할 수 있지만 하나는 추가하고 하나는 연결을 한다. 추가를 할때 추가된 리스트의 영역이 기존 리스트에 그대로 존재. 연결되면 추가된 리스트의.
그렇다면 원하는 위치, 자리에 특정한 요소를 추가하고 싶다면? --> insert()
instert(0, 요소): 리스트의 맨 처음에 요소를 추가
insert(len(리스트), 요소): 리스트의 끝에 요소를 추가

0