출처 - 한국정보화진흥원 2015년 발행 "개인정보 비식별화 기술 활용 안내서"
가명처리
-
휴리스틱 익명화
- 식별자에 해당하는 값들을 몇 가지 정해진 규칙으로 개인정보를 숨기는 방법이다.
- 성명을 홍길동, 임꺽정 등으로 몇몇 일반화된 이름으로 대체하여 표기하거나, 소속 기관명을 화성, 금성 등으로 일반적 명칭을 쓰지 않는 몇몇 대명사로 대체하도록 사전에 규칙을 정해서 수행함.
- 성명, 소속(직장)명, 이메일 계정 등
- 홍길동, 임꺽정 등 데이터 셋이 필요하며, 다양한 항목에 대해서 데이터 셋을 미리 구비해 둘 필요가 있다.
- 누가 봐도 실제 데이터가 아님을 알 수 있는 데이터 셋이어야 한다.
-
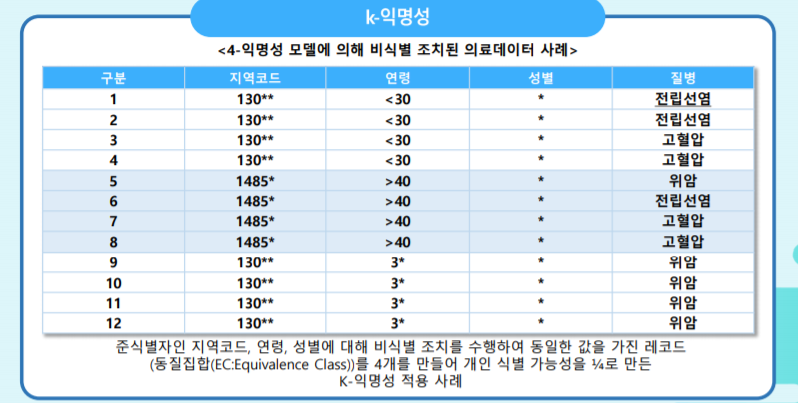
K-익명화
- 동일한 속성 값을 가지는 데이터를 k개 이상으로 유지하여 데이터를 공개하는 방법임. 지정된 속성이 가질 수 있는 값을 일정 수준(k개) 이상으로 유지함으로써 프라이버시 누출을 방지함.
- 예를 들어 3-anonymity를 수행하면, 최소한 3개 이상의 데이터들끼리 같은 속성 값으로 대체되어 전체 자료가 10개의 대표 데이터로 표현될 수 있는 기법임.
- 일반적으로 준식별자에 대해서 비식별처리를 함(준식별자는 대부분의 경우 분석 대상의 분류와 관계 있고, 대부분의 분석에서 분석 대상을 개별 레코드로 분석하는 것이 아니라 집단으로 묶어서 분석하기 때문임)
-
암호화
- 정보의 가공에 있어서 일정 규칙의 알고리즘을 적용하여 암호화함으로써 개인정보를 대체하는 방법임.
- 단방향 암호화(일반적으로 hash)를 사용하는 것이 개인정보의 식별성을 완전히 제거하는 것으로, 보다 안전함.
- 주민등록번호, 여권번호, 의료보험번호, 외국인등록번호, 사용자 ID, 신용카드번호, 기관번호, 디바이스 ID 등
- 이름, 주민등록번호를 하나로 묶어 해시함수 처리해서 개인 식별자로 사용하고, 삭제해버리는 것이 깔끔할 것 같음.
-
교환 방법
- 추출된 표본 레코드에 대해서 이루어짐. 미리 정해진 변수(항목)들의 집합에 대하여 데이터베이스의 레코드와 연계해서 사전에 정의된 외부값으로 레코드의 값을 대체하는 방법임.
- 남자 1, 여자 2 // 서울시 1, 경기도 2, 충청도 3 등등
- 분석에 필요는 하지만(남/여 등) 그대로 살려두기에는 찜찜한 경우에, 외부값을 사전에 다른 곳에 저장해두고, 데이터베이스에서는 교환하는 방법인 것으로 추정됨.
총계처리
- 총계처리 기본방식
- 수집된 정보에 민감한 개인정보가 있을 경우 데이터 집단 또는 부분으로 집계(총합, 평균 등) 처리를 하여 민감성을 낮춤.
- 예를 들어, 특정 나이 값이 있는 경우 집단의 평균 나이값(대표값)을 구한 후 각 개인정보 속성값을 구해진 대표값으로 대체하거나 해당 집단의 소득을 전체 평균을 구한 뒤 일정 규칙의 오차를 가감하여 각 개인정보의 소득 속성값을 변환함.
- 나이, 신장, 소득, 카드 사용액, 유동 인구, 사용자수, 재고량 등
- 부분집계
- 분석 목적에 따라 부분 그룹만 비식별 처리. 즉, 다른 속성값에 비하여 오차 범위가 큰 항목이나 속성값에 대하여 통계값(평균 등)을 활용하여 값을 변환.
- 예를 들어, 40대의 소득 분포 편차가 다른 연령대에 비해 매우 클 경우, 40대의 소득만 선별하여 평균값을 구한 후 40대에 해당하는 각 개인정보의 소득 속성값을 해당 평균값으로 대체함.
- 라운딩
- 집계 처리된 값에 대하여 라운딩(올림, 내림, 사사오입) 기준을 적용하여 최종 집계 처리
- 라운딩으로 인해 전체 통계값의 유의미한 변화가 있을 수 있다는 걱정..
- 데이터 재배열
- 기존 정보값은 유지하면서 개인정보와 연관이 되지 않도록 해당 데이터를 재배열, 즉, 개인의 정보가 타인의 정보와 뒤섞임으로써 전체 정보의 손상없이 개인의 민감 정보가 해당 개인과 연결되지 않도록 하는 방법.
- 데이터에 실질적인 변형이 있기 때문에 데이터가 분석 목적에 맞지 않게 될 수 있으니 주의해서 처리할 것.
데이터 값 삭제
- 속성값 삭제
- 원시 데이터에서 민감한 속성값 등 개인식별 항목을 단순 제거하는 방법.
- 분석 목적에 필요하지 않은 데이터들은 모두 삭제하여야 한다.
- 속성값 부분 삭제
- 민감한 속성값에 대하여 전체를 삭제하는 방식이 아닌 해당 속성의 일부값ㅇ르 삭제함으로써 대표성을 가진 값으로 보이도록 하는 방법.
- 예를 들어 상세 주소의 경우 부분 삭제를 통하여 대표지역으로 표현 가능하다.(서울특별시 중구 무교동 77번지 → 서울특별시 중구) 이 경우 범주화의 경우와 유사하지만, 속성값 부분 삭제는 텍스트 데이터 등에도 폭넓게 활용 가능하다.
- 데이터 행 삭제
- 타 정보와 비교하여 값이나 속성의 구별이 뚜렷하게 식별되는 정보 전체를 삭제, 즉, 특정하게 민감한 속성값 하나가 아닌 해당 정보를 가진 개인의 내용 전체를 제거하는 방법.
- 준식별자 제거를 통한 단순 익명화
- 단순 익명화 방법은 식별자뿐만 아니라 잠재적으로 개인을 식별할 수 있는 준식별자를 모두 제거함으로써 프라이버시 침해 위험을 줄이는 방법.
범주화
- 랜덤 올림 방법
- 수치데이터를 임의의 수 기준으로 올림 또는 내림하는 방법으로, 총계처리의 라운딩 방법과 같은 의미로 사용됨.
- 범위 방법
- 수치데이터를 임의의 수 기준의 범위로 설정하는 기법(소득 3000만원 ~ 4000만원)
- 상한과 하한을 정해 이를 초과하는 값들을 범주화하여 표현하기도 하며, 세분정도 제한 방법이라고 부름. 예를 들어, '< 3000만원', '3000만원 ~ 3999만원' , '4000만원 ~ 4999만원', ....... , '> 7000만원' 과 같이 나눌 수 있음.
- 제어 올림 방법
- 랜덤 올림 방법에서 어떠한 특정 속성값을 변경시킬 때 행과 열의 합이 일치하지 않는 단점을 해결하기 위해서 행과 열이 맞지 않는 것을 제어하여 일치시키는 기법. 실무적으로 잘 쓰이지는 않는 방법이라고 함.
데이터 마스킹
- 임의 잡음 추가 방법
- 소득과 같은 민감 개인식별 항목에 대해 임의의 숫자 등의 잡음 추가(더하거나 곱)하여 식별 정보 노출을 방지하는 기법.
- 예를 들어, 생년월일의 경우 실제 생년월일에 사전에 정의한 6개월의 잡음을 추가한다고 하면, 원래의 생년월일 데이터에 1일부터 최대 6개월의 날짜가 추가되어 기존의 자료와 오차를 가질 수 있도록 적용.
- 이 방법의 특징은 지정된 평균과 분산의 범위 내에서 잡음이 추가되므로 원 자료의 유용성을 해치지 않음.
- 공백과 대체
- 빅데이터 자료로부터 비식별 대상 데이터를 선택한 후, 선택된 항목을 공백으로 바꾼 후에 대체법을 적용하여 공백 부분을 채우는 기법. 특수문자('*', '_') 등이 많이 사용됨.

비전공자 출신 화이트햇 해커