- 다른 전략 뭐 있는지도 알아보기
Redis?
- Redis : Remote Dictionary Server, 'Key-Value'구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터베이스 (DBMS)
→ Redis는 데이터 처리 속도가 빠른 NoSQL 데이터베이스
- NOSQL DB : 'Key-Value' 형태로 저장하는 DB
Redis 장점
Redis의 장점은 여러개가 있지만 지금은 입문이므로 딱 하나만 기억할 것
Redis는 in-memory에 모든 데이터를 저장한다.
→데이터의 처리 성능이 굉장히 빠르다
MySQL과 같은 RDBMS의 DB는 대부분 디스크(Disk)에 데이터를 저장한다.
하지만 Redis는 메모리(RAM)에 데이터를 저장한다.
Disk보다 RAM의 데이터 처리속도가 월등하게 빠르다.
→ 그렇기에 Redis의 데이터 처리 속도는 RDBMS에 비해 훨씬 빠르다.
DBMS vs RDBMS
- DBMS : DataBase Management System >>> Redis, LevelDB, MongoDB, Cassandra
- RDBMS : Relational DataBase Management System >>> MySQL PostgreSQL, Oracle DB SQLite ...
Redis 주요 사용 사례
- 캐싱 (Caching)
- 세션 관리 (Session Management)
- 실시간 분석 및 통계 (Real-time Analytics)
- 메시지 큐 (Message Queue)
- 지리공간 인덱싱 (Geospatial Indexing)
- 속도 제한 (Rate Limiting)
- 실시간 채팅 및 메시징 (Real-time Chat And Messaging)
이 중에서 내가 가장 필요한 캐싱만 배워볼 것임
Redis 설치(MacOS)
- 설치
brew install redis - 확인
brew services info redis
- 실행 / 중지
brew services start redis
brew services stop redis - redis 접속
redis-cli-redis 테스트(레디스 실행 + 접속 후 사용할 것)
ping
// response : PONGRedis 기본 명령어
- 캐싱 기능에 필요한 필수 7가지만 배워보기
- 저장 (SET)
set key value
set joe:name "hunter joe" ""를 붙이는 이유 : 띄어쓰기가 있는 value면 필요, 띄어쓰기가 없으면""필요 없음
- 조회(GET)
get key
get joe:name
// "hunter joe"- 저장된 모든 키 조회
keys *
keys
1) "joe:name"
2) "somekey"없는 데이터를 조회하게 되면 nil이 출력
- 삭제 (DEL)
del key
del joe:name
// (integer) 1- 만료시간 설정(TTL: Time To Live)
redis 특성상 메모리 공간이 한정 되어 있기 때문
set key value ex 30: (30sec)
set joe:pet dog ex 30- 만료시간 확인(TTL)
ttl key
ttl joe:pet
// (integer) 15 <- 15초 남음ttl이 만료된 키값, ttl을 설정하지 않은 키값 조회
- ttl이 만료된 키갑을 조회하면
-2출력- ttl을 설정하지 않은 키값을 조회하면
-1출력
- 모든 데이터 삭제 (FLUSHALL)
flushall
// OKkey 네이밍 컨벤션
가장 자주 활용하는 네이밍 컨벤션
콜론:을 활용해 계층적으로 의미를 구분해 사용
EX)
user:100:profile: 사용자들(user) 중 PK가 100인 사용자의 프로필product:123:detail: 상품들 중 PK가 123인 상품의 세부사항
컨벤션의 장점
1. 가독성 : 데이터의 의미 + 용도 쉽게 파악
2. 일관성 : 코드 일관성 + 유지보수 용이
3. 검색 및 필터링 용이 : 패턴 매칭을 사용해 특정 유형의 key 검색이 쉽다.
4. 확장성 : 서로 다른 key와 이름이 겹쳐 충돌할 일이 적어진다.
PK( Primary Key)
id name age 100 John 25 101 Doe 30
- 데이터베이스에서 각 행(row)을 고유하게 식별하는 값
id의100or101이 PK이다.
캐싱 전략 (자주 쓰는거 위주)
Cache Aside (= Look Aside, Lazy Loading) 전략
게시판 서비스를 배포했다고 가정하고 Cache Aside 작동 흐름 알아보기
1. 처음 게시판 서비스 배포 -> DB, Redis에는 아무런 데이터도 없음
2. 사용자가 게시글 작성 -> DB에 저장(Redis에는 X)
3. 사용자가 데이터 조회 요청 -> DB에서 바로 데이터 조회 X Redis에 있는 지 먼저 확인)
4. Redis에 데이터가 없는 걸 확인 후 DB로부터 데이터 조회해서 응답
5. DB로부터 조회한 데이터를 응답한 뒤 Redis에도 데이터를 저장
6. 다시 한번 사용자가 데이터를 조회하려고 요청
7. Redis에 조회하고자 하는 데이터가 있는 지 조회 -> 데이터가 존재하니 Redis로 부터 데이터를 응답
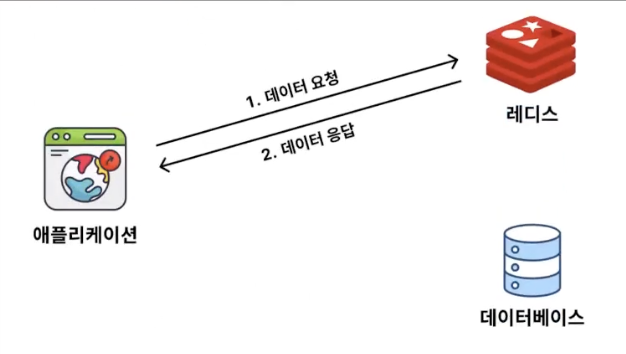
즉, Cache Aside 전략은 캐시에서 데이터를 확인하고 없다면 DB를 통해 조회해오는 방식
Cache Hit, Cache Miss
-
캐시에 데이터가 있을 경우 : Cache Hit
-
캐시에 데이터가 없을 경우 : Cache Miss
Write Around 전략
- Cache Aside 전략이 데이터를 어떻게 조회할 지에 대한 전략이였다면
- Write Around 전략은 데이터를 어떻게 쓸 지(저장,수정,삭제)에 대한 전략이다.
- Write Around 전략은 Cache Aside 전략과 같이 자주 활용되는 전략이다.
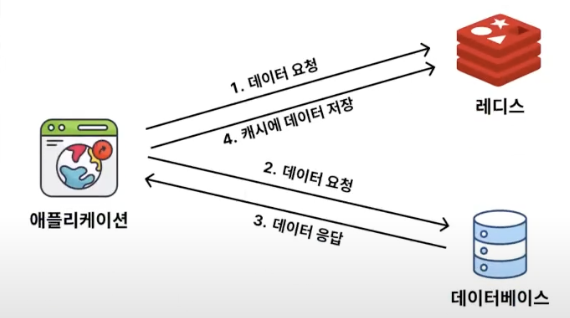
Write Around 전략은 데이터를 저장할 때는 레디스에 저장하지 않고 DB에만 저장하는 방식
그러다 데이터를 조회할 때 Redis에 데이터가 없으면 DB로부터 데이터를 조회해서 Redis에 저장시켜주는 방식
즉, Write Around 전략은 쓰기 작업(저장, 수정, 삭제)를 캐시에는 반영하지 않고, DB에만 반영하는 방식
Cache Aside, Write Around 전략의 한계점
한계점
1. 캐시된 데이터와 DB 데이터가 일치하지 않을 수 있다.

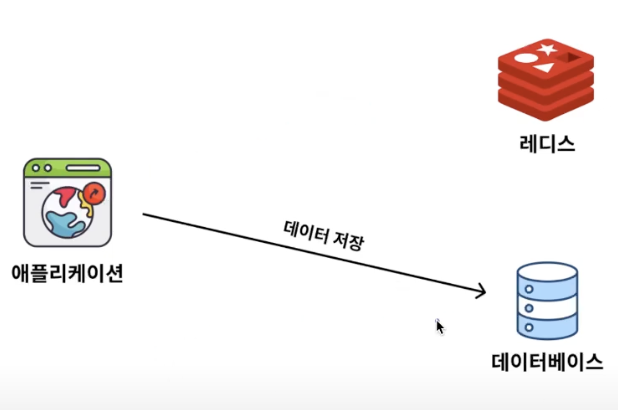
Cache Aside와 Write Around 전략을 같이 썼을 때의 한계점 중 하나는
캐시된 데이터와 DB 데이터가 일치 하지 않을 수 있다는 점이다. → 데이터의 일관성을 보장할 수 없다는 뜻이기도 하다.
Write Around 전략에 따르면 데이터를 수정할 때 DB만 업데이트를 시키기 때문에 기존 저장된 Redis의 데이터 값과 DB의 데이터 값은 다를 수 밖에 없다.
EX) 프로필 수정에서 내 이름을 JOE => DOE 로 바꾸고 프로필 조회를 했더니 JOE라고 표시된다는 뜻
2. 캐시에 저장할 수 있는 공간이 비교적 적다.
DB는 Disk에 저장해서 많은 양을 저장하기 용이하지만, 캐시는 RAM에 저장하기 때문에 DB에 비해 많은 양의 데이터를 저장할 수 없다.
한계 극복
1. 캐시된 데이터와 DB 데이터가 일치 하지 않을 수 있다.
캐시된 DB의 데이터를 일치시키기 위해 데이터를 수정할 때마다 동시에 업데이트 시키면 성능적으로 느려짐
그렇다고 성능 향상을 위해 DB의 데이터만 업데이트 시키면 Redis와 DB의 데이터가 일치하지 않음
→ Trade Off발생
따라서 데이터 조회 성능 개선 목적으로 Redis를 쓰는 경우에는 데이터의 일관성을 포기하고 성능 향상을 택한 것
이러한 이유로 캐싱을 적용하기에 적절한 데이터는 다음과 같다.
- 자주 조회되는 데이터
- 잘 변하지 않는 데이터
- 실시간으로 정확하게 일치하지 않아도 되는 데이터
하지만 장기간 데이터가 일치하지 않는 건 문제임
→ 이 때 Redis의 TTL 기능 사용 할 것 (만료 시간 설정)
- 일정 시간이 지나면 데이터가 캐시에서 삭제된다.
- 그럼 특정 사용자가 조회를 하는 순간 Cache Miss가 발생한다.
- DB의 데이터를 새로 조회해 와서 캐시에 데이터를 넣게 된다.
- 즉, 데이터가 새롭게 갱신되는 효과가 생김
2. 캐시에 저장할 수 있는 공간이 비교적 적다.
위에서 활용한 TTL 기능을 활용하면 캐시의 공간을 효율적으로 쓸 수 있다.
→ Why? : 자주 조회하지 않는 데이터는 만료 시간에 의해 데이터가 삭제되기 때문
결론
Cache Aside + Write Around 전략을 사용할 때는 주로
TTL을 같이 활용한다.
캐싱으로 조회 성능 개선 전 확인할 것
데이터 조회 성능을 개선하는 방법
- SQL 튜닝
- 캐싱 섭서 활용 (Redis 등)
- 레플리케이션 (Master/Slave 구조)
- 샤딩
- DB 스케일업 (CPU, Memory, SSD 등 하드웨어 업글)
많은 성능 개선 방법 중 'SQL 튜닝'을 먼저 고려할 것
1. SQL 튜닝을 제외한 나머지 방법는 추가적인 시스템을 구축해야 한다.
→ 따라서 금전적, 시간적 비용이 추가적 발생
→ 조금 더 복잡해진 시스템 구조로 인해 관리 비용 증가
그렇기에 SQL 튜닝은 기존의 시스템 변경 없이 성능을 개선할 수 있다.
근본적인 문제를 찾자
근본적 문제가 SQL 튜닝일 가능성이 높다.
SQL자체가 비효율적으로 작성됐다면 아무리 시스템적으로 성능을 개선하더라도 한계가 있다.
참고 자료
