
5장 웹서버
다채로운 웹서버
웹 서버는 HTTP 요청을 처리하고 응답을 제공한다.
웹 서버는
웹 서버 소프트웨어와웹페이지 제공에 특화된 장비모두를 가리킨다.
웹 서버 구현
웹 서버는 HTTP 및 그와 관련된 TCP 처리를 구현한 것이다.
웹 서버의 형태
- 다목적 소프트웨어(웹 서버를 표준 컴퓨터 시스템에 설치하고 실행 가능)
- 마이크로프로세서(사용자에게 판매할 전자기기 안에 몇 개의 컴퓨터 칩만으로 구현된 것)
다목적 소프트웨어 웹서버
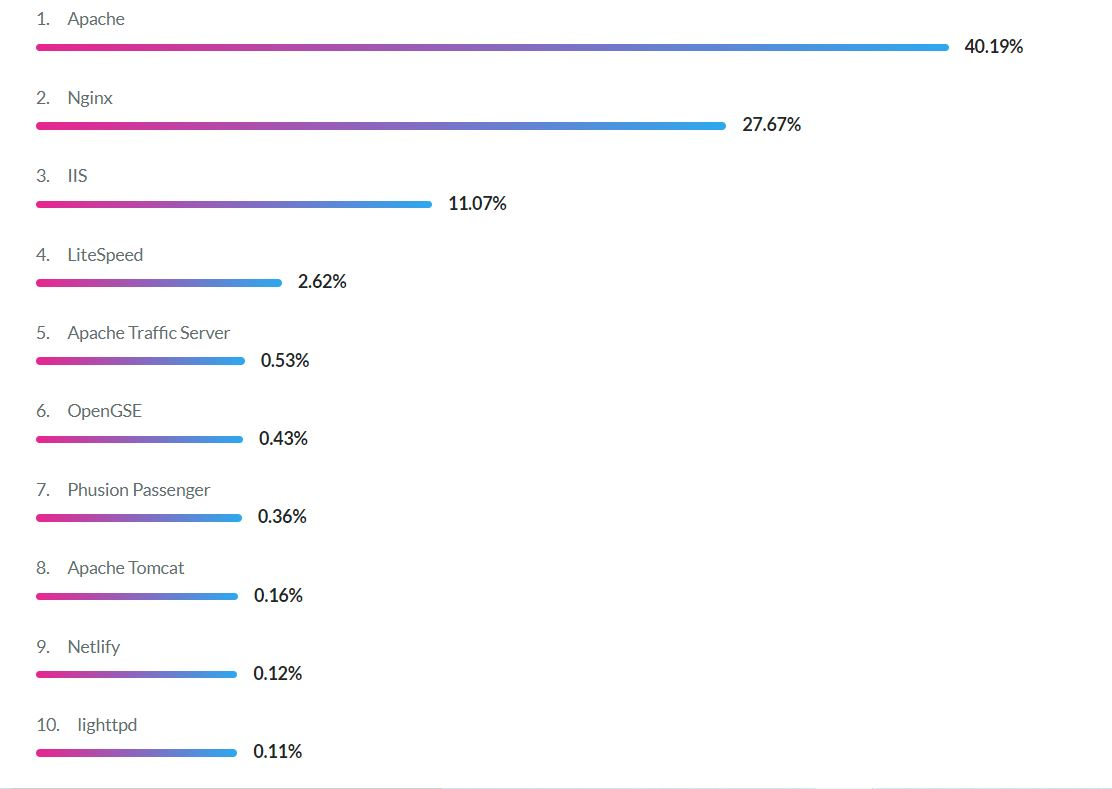
주로 몇 가지 웹 서버 소프트웨어만이 널리 사용
- 모든 인터넷의 37% → 마이크로소프트 웹 서버
- 35% → 아파치 웹 서버
- 14% → nginx 서버
2022년 version
임베디드 웹 서버
일반 소비자용 제품에 내장될 목적으로 만들어진 작은 웹 서버 → 간편한 웹 브라우저 인터페이스로 관리할 수 있게 해줌
간단한 펄 웹 서버
일반적인 HTTP/1.1의 기능들을 지원하려면, 풍부한 리소스 지원, 가상 호스팅, 접근 제어, 로깅, 설정, 모니터링, 그 외 성능을 위한 각종 기능들이 필요하다.
대신 최소한으로 기능하는 HTTP 서버는 30줄 이하의 펄(perl) 코드로도 만들 수 있다. → 책에서는 type-o-serve라는 예제를 사용. 자세한 코드는 책 참조(C, Python으로 만드는 소켓 서버와 비슷한 듯)
진짜 웹 서버가 하는 일
공통적으로 다음과 같은 일들을 수행한다.
- 커넥션을 맺는다. — 클라이언트의 접속을 받아들이거나, 원치 않는 클라이언트라면 닫는다.
- 요청을 받는다. — HTTP 요청 메시지를 네트워크로부터 읽어 들인다.
- 요청을 처리한다. — 요청 메시지를 해석하고 행동을 취한다.
- 리소스에 접근한다. — 메시지에서 지정한 리소스에 접근한다.
- 응답을 만든다. — 올바른 헤더를 포함한 HTTP 응답 메시지를 생성한다.
- 응답을 보낸다. — 응답을 클라이언트에게 돌려준다.
- 트랜잭션을 로그로 남긴다. — 로그파일에 트랜잭션 완료에 대한 기록을 남긴다.
단계 1: 클라이언트 커넥션 수락
클라이언트가 이미 서버에 열려있는 지속 커넥션이 있다면 그것을 사용하고 없다면 새 커넥션을 연다.
새 커넥션 다루기
서버는 클라이언트와 커넥션을 맺고 그 커넥션에서 IP 주소를 추출하여 어떤 클라이언트인지 확인한다. 그 이후, 새 커넥션을 커넥션 목록에 추가하고 어떤 데이터들이 오가는지 지켜보기 위한 준비를 하는데, IP 주소나 호스트 명이 인가되지 않았거나 악의적이라고 알려진 것인 경우 커넥션을 닫는다.
클라이언트 호스트 명 식별
웹 서버는 역방향 DNS를 사용해서 클라이언트의 IP 주소로부터 호스트 명을 변환하도록 하여 이를 구체적인 접근 제어와 로깅을 위해 사용할 수 있다.
호스트명 룩업은 웹 트랜잭션을 느려지게 할 수 있어서 대부분의 웹 서버에서 호스트 명 분석을 꺼두거나 특정 콘텐츠에 대해서만 켜둔다.
ident를 통해 클라이언트 사용자 알아내기
ident 프로토콜은 서버에게 어떤 사용자 이름이 HTTP 커넥션을 초기화했는지 찾아낼 수 있게 해준다. 일반적으로 113번 포트를 사용하고, 웹 서버 로깅에 유용하기 때문에, 널리 쓰이는 일반 로그 포맷의 두 번째 필드는 각 HTTP 요청의 ident 사용자 이름을 담고 있다.(보통 아파치에서 가용한 정보가 없는경우 -(하이픈)으로 채운다.)
그러나 공공 인터넷에서는 아래의 이유로 잘 동작하지 않는다.
- 클라이언트들이 identd 신원확인 프로토콜 데몬 소프트웨어 실행 X
- HTTP 트랜잭션을 유의미하게 지연시킴(ident가)
- 방화벽이 ident 트래픽이 들어오는 것을 막는 경우가 많다.
- ident 프로토콜은 안전하지 않고 조작하기 쉽다.
- ident 프로토콜은 가상 IP 주소를 잘 지원하지 않는다.
- 클라이언트 사용자 이름의 노출로 인한 프라이버시 침해의 우려가 있다.
단계 2: 요청 메시지 수신
요청 메시지 파싱시 요청 메서드, URI, 버전 번호를 찾으며, CRLF(캐리지 리턴 줄바꿈)를 기준으로 읽는다.
메시지의 내부 표현
몇몇 웹 서버는 요청 메시지를 쉽게 다룰 수 있도록 내부의 자료 구조에 저장하여 관리한다.
커넥션 입력/출력 처리 아키텍처
고성능 웹 서버는 수천 개의 커넥션을 동시에 열 수 있도록 지원하는데, 웹 서버의 아키텍처의 차이에 따라 요청을 처리하는 방식이 달라진다.
단일 스레드 웹 서버
한 번에 하나씩 요청, 심각한 성능 문제를 발생시켜 보통 로드가 적은 서버나 type-o-serve와 같은 진단도구에서만 작성
멀티프로세스와 멀티스레드 웹 서버
여러 개의 프로세스 혹은 고효율 스레드를 할당하는데 필요할때 혹은 미리 만들어짐으로써, 수많은 프로세스나 스레드는 너무 많은 메모리나 시스템 리소스를 소비한다.
따라서 보통 웹 서비스들은 최대 개수에 제한을 건다.
다중 I/O 서버
대량의 커넥션 지원을 위해 많은 웹 서버가 다중 아키텍처를 채택하였다. 실제로 해야 할 일이 있을 때, 커넥션에 대해 작업을 수행한다.
다중 멀티스레드 웹 서버
멀티스레딩과 다중화를 결합한것 → 여러 개의 스레드는 각각 열려있는 커넥션을 감시하고 각 커넥션에 대해 조금씩 작업 수행
단계 3: 요청 처리
HTTP 메서드에 따라 요청을 처리하는 단계
단계 4: 리소스의 매핑과 접근
요청 메시지의 URI에 대응하는 콘텐츠를 식별하는 과정
Docroot
웹 서버 파일 시스템의 특별한 폴더이며 웹 콘텐츠를 위해 예약해 둔 것을 docroot라고 부른다.
이를 사용하는 과정에서 서버는 상대적인 url이 docroot이외 부분이 노출되는 일이 생기지 않도록 주의해야한다.
가상 호스팅된 docroot
가상 호스팅된 웹 서버는, 각 사이트에 그들만의 분리된 문서 루트를 주는 방법으로 한 웹 서버에서 여러 개의 웹 사이트를 호스팅한다.
서버는 두 웹 사이트를 HTTP Host 헤더나 서로 다른 IP 주소를 이용해 구분할 수 있다.(docroot 설정을 해주어야 함)
사용자 홈 디렉터리 docroots
사용자들이 한 대의 웹 서버에서 각자의 개인 웹 사이트를 만들 수 있도록 해주는 것으로, URI는 사용자의 개인 문서 루트를 가리킨다.
디렉터리 목록
파일이 아닌 디렉터리 URL에 대한 요청을 받을 때 다음과 같은 행동을 취하도록 웹 서버를 설정할 수 있다.
- 에러를 반환
- 디렉터리 대신 특별한 ‘색인 파일'을 반환
- 디렉터리를 탐색해서 그 내용을 담은 HTML 페이지를 반환
모든 파일의 이름을 우선순위로 나열해주는 디렉터리 색인 파일 자동 생성 기능도 있고 웹서버에서 이를 끄고 킬수 있다.
동적 콘텐츠 리소스 매핑
아파치는 아래와 같은 기능들을 제공한다.
- 실행 가능한 프로그램이 위치한 디렉터리로 매핑 되도록 설정하는 기능
- 특정 확장자의 파일만 실행하도록 설정
오늘날의 애플리케이션 서버는 서버사이드 동적 콘텐츠 지원기능을 갖고 있다.(ex: MS의 액티브 서버 페이지, 자바 서블릿)
서버사이드 인클루드
이 서버사이드 인클루드가 설정되어 있다면 서버는 그 리소스의 콘텐츠를 클라이언트에게 보내기 전에 처리한다.(동적 콘텐츠를 만드는 쉬운 방법)
접근 제어
웹 서버는 클라이언트의 IP 주소에 근거하거나 비밀번호를 요구하여 각각의 리소스에 접근 제어를 할당할 수 있다.
단계 5: 응답 만들기
응답 메시지는 응답 상태코드, 응답 헤더, 응답 본문을 포함한다.
응답 엔터티
응답 본문이 있다면 주로 아래의 내용을 포함한다.
- 응답 본문의 MIME 타입을 서술하는 Content-Type 헤더
- 응답 본문의 길이를 서술하는 Content-Length 헤더
- 실제 응답 본문의 내용
MIME 타입 결정하기
- mime.types: 웹 서버는 각 리소스의 MIME 타입 계산을 위한 확장자별 MIME 타입이 담겨 있는 파일을 탐색한다. → 확장자 기반 타입 연계
- 매직 타이핑(Magic typing): 파일 내용 검사후 알려진 패턴에 대한 테이블에 해당하는 패턴을 찾는다. 이 방법은 파일이 표준 확장자 없이 이름 지어진 경우에는 편리하다.
- 유형 명시(Explicity typing): 파일 확장자나 내용에 상관없이 어떤 MIME 타입을 갖도록 웹 서버를 설정하는것
- 유형 협상(Type negotiation): 한 리소스가 여러 종류의 문서 형식에 속하도록 결정한다. 또한 협상 과정을 통해 사용하기 좋은 형식을 판별할 것인지의 여부도 설정 가능하다.
리다이렉션
웹 서버는 요청을 수행하기 위해 브라우저가 다른 곳으로 가도록 리다이렉트 할 수 있다.
- 영구히 리소스가 옮겨진 경우(301 Moved Permanently)
- 임시로 리소스가 옮겨진 경우(303 See Other, 307 Temporary Redirect)
- URL 증강(문맥 정보를 포함시키기 위해 재 작성된 URL로 리다이렉트 시켜 상태정보가 추가된 완전한 URL을 포함한 요청을 다시보냄)
- 부하 균형(좀 덜 부하가 걸린 서버로 리다이렉트)
- 친밀한 다른 서버가 있을 때(어떤 사용자에 대한 정보를 가지고 있는 다른 서버로 리다이렉트)
- 디렉터리 이름 정규화(URI 요청 시 빗금 빠뜨린경우 이를 추가하여 리다이렉트)
단계 6: 응답 보내기
서버는 커넥션 상태를 추적하여 비지속적인 커넥션이면 메시지 전송후 커넥션을 닫는다.
지속적인 커넥션이면 Content-length 헤더를 바르게 계산하기 위해 특별한 주의를 필요로 하는 경우가 있을 수 있다. 또한 클라이언트가 응답이 언제 끝나는지 알 수 없는 경우에 커넥션은 열린 상태를 유지한다.
단계 7: 로깅
트랜잭션 완료 시 로그를 로그파일에 기록
추가 자료조사(TCP 흐름제어, 오류제어, 혼잡제어)
흐름제어
송신측과 수신측의 데이터 처리 속도 차이를 해결하기 위한 기법
수신측에서 받을 수 있는 데이터 양보다 더 많은 데이터가 들어오면 초과된 데이터들이 손실될 수 있다.
1. Stop and Wait
매번 전송한 패킷에 대해 확인응답을 받아야만 그 다음 패킷을 전송하는 방법
패킷을 하나씩 보내기 때문에 비효율적이다.
2. Sliding Window
수신측에서 설정한 윈도우 크기만큼 송신측에서 확인응답 없이 세그먼트를 전송할 수 있게 하여 흐름을 동적으로 조절하는 기법
윈도우에 포함된 패킷을 계속 전송하고, 수신 측으로부터 확인 응답이 오면 윈도우를 옆으로 옮겨 다음 패킷들을 전송한다.
재전송
수신 측으로부터 확인 응답을 받지 못하면, 패킷을 재전송한다.
보통 타이머를 이용해 구현한다.
혼잡제어
송신측의 데이터 전달과 네트워크 데이터 처리 속도를 해결하기 위한 기법이다.
→ 발생하는 원인으로 한 라우터에 데이터가 몰릴 경우 데이터를 모두 처리하지 못해 재전송하면서 혼잡을 가중시켜 오버플로우 혹은 데이터 손실을 발생시킨다. 따라서 이러한 네트워크 혼잡을 피하기 위해 송신측에서 보내는 패킷 수를 조절하는 작업을 혼잡제어라고 한다.
혼잡제어기법
- AIMD(합 증가 곱 감소 방식)
- 패킷을 보내고 문제 없으면 window의 크기를 1씩 증가 시킴
- 만약 실패하면 패킷의 보내는 속도를 절반으로 줄인다.
- 초기 네트워크 대역폭을 사용하지 못해 오랜시간이 걸리고, 네트워크가 혼잡해지고 나서야 대역폭을 줄이는 방식이다.(미리 감지하지 못함)
- Slow Start
- 윈도우의 크기를 1, 2, 4, 8... 과 같이 지수적으로 증가 시킨다.
- 혼잡이 발생하면 window size를 1로 떨어뜨린다.
- 혼잡현상이 발생하고 난후, 네트워크 수용량을 예측하여 그 절반까지 이전처럼 지수함수 꼴로 증가시키고 그 이후부터는 완만하게 1씩 증가시킨다.
- Fast Retransmit
- 패킷을 받는 수신자 입장에서는 세그먼트로 분할된 내용들이 순서대로 도착하지 않을 수 있다.
- 이러한 경우 잘 도착한 마지막 패킷의 다음 순번을 ACK 패킷에 실어 보낸다.
- 이런 중복 ACK 패킷을 3번 받게 되는 경우 재전송이 이루어진다.
- Fast Recovery
- 혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이며 선형증가 시킨다.
- 이후 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
혼잡 제어 정책
혼잡이 발생하면 윈도우 크기를 줄이거나, 혹은 증가시키지 않으며 혼잡을 회피한다 라는 전제를 깔고 있다.
가장 유명한 정책 2가지 Tahoe와 Reno 이고 기본적은로 처음에 Slow Start 정책을 사용하다가 네트워크가 혼잡하다고 느껴졌을 때는 AIMD 방식으로 전환하는 방법을 사용한다.
3 ACK Duplicated 혹은 Timeout이라는 2가지 시나리오가 발생하면 윈도우의 크기를 줄이게 된다.
또한 ssthresh라는 Slow Start 임계점이 존재하고 이는 여기까지만 slow start를 사용하겠다는 의미이다.
Tahoe
Slow Start를 사용하여 자신의 윈도우 크기를 지수적으로 증가시키다가 sshtresh를 만난 이후부터는 AIMD에서 사용하는 합 증가 방식을 사용한다. 또한 sshtresh를 혼잡이 발생할 때마다 그의 반으로 설정한다.
그러나 윈도우 크기를 다시 1로 변경하기 때문에 윈도우 크기를 키울 때 너무 오래걸린다는 것이 단점이다. 그래서 나온 방법이
빠른 회복 방식을 활용한TCP Reno이다.
Reno
3 ACK Duplicated를 만났을 때 윈도우의 크기를 반으로 줄이고, Timeout을 만났을 때 윈도우 크기를 1로 만든다. 그러나 sshtresh는 3 ACK Duplicated가 일어났을 때만 반으로 줄인다.
오류제어
훼손된 패킷을 감지하고 손실된 패킷은 재전송하고, 순서에 맞지 않는 세그먼트를 버퍼에 저장하는 일을 한다.
Stop And Wait
송신 측에서 패킷을 보내고 보낸 패킷에 대한 응답이 오면 다음 패킷을 보냄
그러나 Sliding Window 기법을 사용하면 데이터를 연속적을 보내는 방식이라 의미가 없음 따라서 재전송 기반의 오류 제어, ARQ(Automatic Repeat Request)를 사용!
ARQ
TCP는 기본적으로 재전송 기반의 오류 제어를 사용하지만, 수 많은 데이터를 주고 받아야 하는 상황에서 이 방법은 비효율적이기 때문에 이러한 재전송을 최대한 적게하는 방식으로 TCP는 오류를 제어한다.
1. Go-Back-N
여러개의 데이터를 연속적으로 보내다가 오류가 발생한 데이터부터 다시 재전송하는 방식
이미 수신한 데이터를 폐기하고 다시 재전송해야한다는 단점
2. Selective Repeat
오류가 발생한 데이터만 골라서 재전송하는 방식
송신측은 오류가 발생한 패킷만 재전송하는데, 수신측의 버퍼에 순서가 보장되지 않는다는 단점이 존재한다. 그렇기 때문에
재정렬이 필요하고 이는 또 다른 버퍼 공간을 필요로 한다.
참고 사이트
https://velog.io/@jsj3282/TCP-흐름제어혼잡제어-오류제어#5-tcp의-제어-3--혼잡제어
https://steady-coding.tistory.com/507
https://gyoogle.dev/blog/computer-science/network/흐름제어 & 혼잡제어.html
