2.Page replacement
Need for page replacement
free frame이 없을 때, page replacement가 일어나야 한다.
steps
- secondary storage에서 page 찾는다.
- main memory에서 free frame을 찾는다. 있으면 사용하고 없으면
page replace algorithm을 통해 swap out시킬(secondary storage로 보내기) victim frame을 고른다. disk로 보낸다.(사실 기존에서 변경된 사항이 있는 경우만 하면 된다modified) - 데리고 올 page를 새롭게 비워진 frame에 넣는다. page table과 frame table을 업데이트 한다.
- 프로세스를 다시 수행한다.
이때, modified 되었는지, 즉 꼭 disk로 swap out시킬 필요 있는지 바로 알기 위해 modify (dirty) bit이 사용된다. (page transfer overhead 줄어듬) 이는 page table에 valid-invalid bit과 함께 쓰여진다.
또한, page fault를 적게 일으킬 swap out시킬 victim frame을 고르는 일 = page replace algorithm도 중요하다.
Page Replacement Algorithm
page-fulat rate가 가장 낮은 page를 찾는 알고리즘.
어떤 일련의 순서로 페이지에 접근하는지 memory reference string을 만들어보자.
한 프로세스가 접근하는 주소를 촤르륵 펼쳐보자. 같은 페이지에 있는 주소에 연달아 접근한다면, 묶어주자. (collapse, 연속적 access라면 첫번째 page fault에서 memory에 올려주었을 것이기 때문이다)
page fault vs. number of Frame
frame 개수가 많아질수록 page fault는 감소할 것이다.
메인 메모리에 올라와 있을 수 있는 애들이 많아진다는 거니까.

1) First-In-First-Out (FIFO Algorithm)
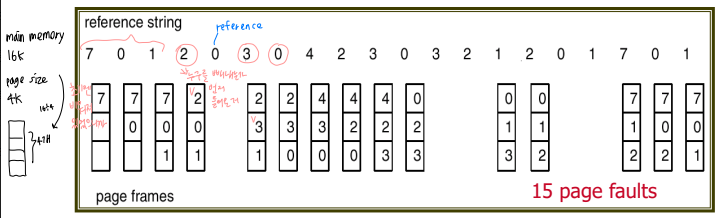
page replacement를 누구로 할 것인가. 제일 먼저 들어왔던 애.
이해하고 구현하기 쉽지만 성능은 항상 좋지만은 않다.
FIFO illustrating Belady's Anoamly

2) Optimal(OPT or MIN) Algorithm
미래에 긴 시간동안 사용되지 않을 page를 replace해준다.
lowest page faul rate, 하지만 Belady's Anomaly는 해결못함
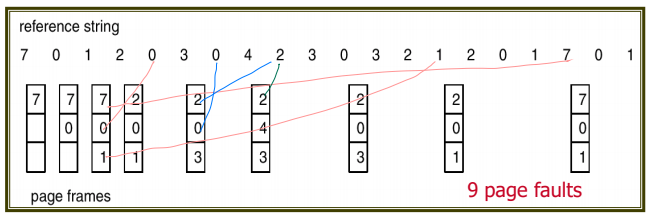
하지만 미래의 일을 어떻게 아는가? 추정해야 한다. 하지만 역시나 구현하기 어렵다.
따라서 실제로 사용하진 않고, 다른 alogrithm이 얼마나 이상적으로 잘 도달했는가 비교하기 위한 목적으로 사용된다.
3) Least Recently Used(LRU) Algorithm
오랫동안 사용하지 않을(optimal) ~~ 오랫동안 사용되지 않았던
계속 사용되지 않았다면 앞으로 사용되지 않을수도!
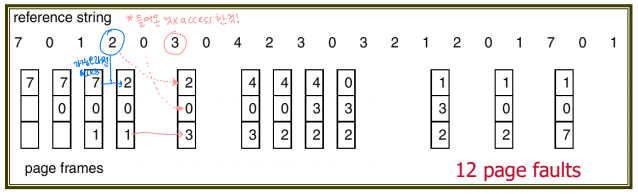
page fault가 좀 줄었다. 성능 좋다!
가장 많이 사용하지만, 구현하기 어렵다. HW의 지원이 필요하다.
Implementing LRU Algorithm
① Counter implementation
모든 page table entry는 access 번호를 저장하는 counter가 있다.
page가 쓰일 때마다 가상의 clock을 이 counter에 저장한다.
clock은 매 메모리 reference마다 증가한다.
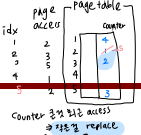
replace가 필요할 때, counter 값이 가장 작은 page를 선택한다.
② Stack implementation
page number stack을 doubly linked list 형태로 만든다.
page를 쓸 때마다 top으로 옮긴다.
즉, stack의 top은 항상 최근에 사용된 page를 의미한다.
replace는 stack의 bottom을 선택하면 된다. 따라서 search가 필요없다.
하지만 linked list 형태는 많은 업데이트를 필요로 하고, overhead가 커진다는 단점이 있다.
LRU 구현이 어렵다.
비슷한 걸 구현해보자.
LRU Approximation Algorithm
① Reference Bit Algorithm
각 페이지마다 counter 쓰듯이 reference bit을 사용한다. 초기값 0
page를 쓸 때마다 1로 바꾼다.(by HW)
replace는 1로 바뀌지 않은, access되지 않은 0인 애로 고른다.
구현이 간단하다. 하지만 어떤 것이 나중에 접근되었는지, 순서를 모른다.
② Additional Reference Bits Algorithm (Reference Byte Algorithm)
reference bit을 여러 bit로 사용한다.
refernce bit과, 추가적인 reference byte
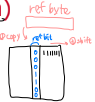
8 bit(1 byte)를 각 page table마다 둔다.
일정한 간격마다 reference bit을 reference byte로 옮긴다.(shift right, copy)
8 time periods를 기록할 수 있다.
replace는 가장 작은 수를 선택하면 된다.
왼쪽에 1로 적힌 게 있을수록(수가 클수록) 최근에 접한 거니까.

③ Second Chance (Clock) Algorithm
page의 circular list를 사용한다.
초기에 page가 load될 때 reference bit을 1로 설정
replace할 때가 되면, reference bit을 검사한다.
reference bit가 0이라면 replace한다.
reference bit가 1이라면, 잠시 0으로 바꾸어주고 두 번째 기회를 준다. 다시 접근되면, 0일 때 접근되는 거니까 replace한다.
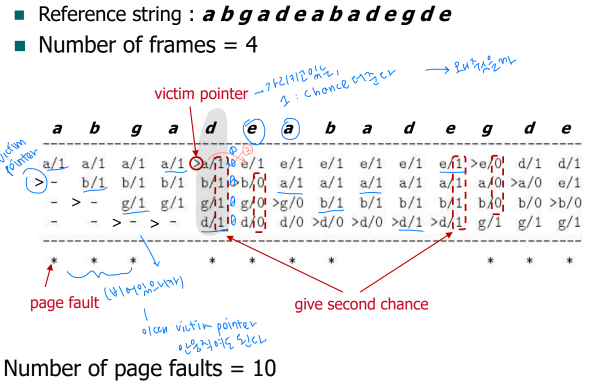
모든 reference bit 1이라면 FIFO처럼. (모두 0으로 바꾸어주네)
(1이라서 0으로 바꿔 주고, victim pointer를 옮기고. 결국엔 한 바퀴 돌고나면 a가 0이라서 replace)
second chance를 통해 다시 한 번 가까운 미래에 access되는 애가 swap out되는 일 없게 해줄 수 있다.
초기에 load되서 access되지 않는 애와 계속 access되는 애를 구분짓자는 것이 목적
④ Enhanced Second Chance Algorithm
reference bit 외에 modify bit을 또 써서 구현할 수 있다.
4개의 class로 구분되는데, (refer, modify)
1. (0,0) : not recently, not modified : 얘가 replace하기 좋은 애(swap out 안해도 됨)
2. (0,1) : not recently, modified
3. (1,0) : recently, not modified
4. (1,1) : recently, modified
더 정확하게 victim 고를 수 있지만 search 문제가 발생할 수 있다.(circular queue 여러번 탐색)
4) Couting-Based Algorithms
이전의 알고리즘은 모두 시간 기반 알고리즘
① Least Frequently (LFU) Algorithm
가장 count가 적은 것을 replace
바로 직전 access한 애를 선택할 가능성도 있다
② Most Frequently(MFU) Algorithm
가장 count가 적은 것이 최근에 사용된 것이기 때문에
가장 큰 애를 선택하자.
