2. Non-contiguous Allocation
1) Paging
어디 한 번 비연속적으로 할당을 해보자!
먼저 우리가 생각하는 process는 연속적으로 생겼다. PCB를 떠올려보면..끄덕. 그런데 이걸 효율적으로 저장하기 위해서는 비연속적으로 넣어야 하니까.. 잘라야겠다!
😮
먼저, CPU에 의해 만들어지는 logical memory 가상 메모리를 일정한 크기로(fixed-sized blocks) 자른다. 이걸 page라고 부른다.
그럼 이 자른 걸 physical memory에 넣어야하는데, 쉽게 생각하기 위해 physical memory도 같은 크기로 잘라보자. 이는 frame이라고 부른다.
이 page 또는 frame의 크기는 HW에 의해 정해지며, 2의 지수승으로 표현된다. 4KB(2^12) ~ 1GB(2^20)까지!
자 그럼 이 자른 것들이 비연속적으로 이곳저곳에 퍼질텐데, 그 위치를 어떻게 연결할 수 있을까.
바로 "page table"이 있다.
logical address를 physical address로 바꾸어준다.
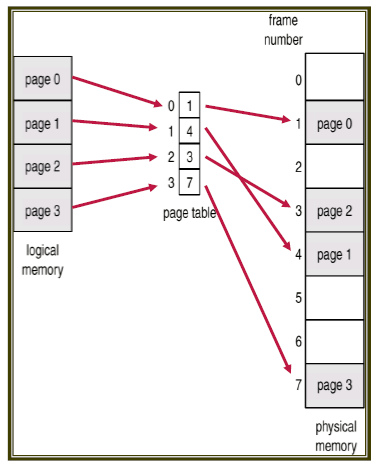
🤖page table : 삐빅삐빅 page 1? 너는 어디 보자.. 4번 frame으로 가라!하지만 이런 방식을 사용해도 꽉 차기 전 가장 마지막 process에 대해서 internal fragmention은 존재한다. 물론 external fragmentation은 줄였지만 말이다.
① Address Translation Scheme
CPU는 logical address를 이렇게 만든다.
- page number (p) = page table index
- page offset (d) = page table을 통해 알아낸 frame index에서 얼마만큼 더 갈까
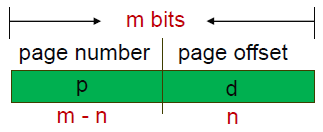
m bit 길이의 주소가 있다고 하자.(m : 32bit or 64 bit)
page offset이 n bit라고 하면, (n : 4KB or 8KB = 2^12B or 2^13B or more...)
곰곰.. 나머지 page number의 길이는 m-n bit이다!
어라,
page offset의 길이는 frame에 도착했을 때 얼마나 더 갈 수 있는지 범위를 나타내기도 한다. frame 단위(=page 단위)로 잘랐으니 아무리 많이 가봐야 frame 크기(=page 크기) 안에서 움직이는 셈이다.
그러니까, 즉 page offset의 길이는 하나의 page size를 나타낸다!
그럼 page number가 page table의 index라고 했으니,
page number의 길이는 총 page table이 몇 개의 칸👾으로 이루어져있는지 알 수 있다.
오오오
예를 들어, 32 bits CPU이며 page size가 4KB라고 하면,
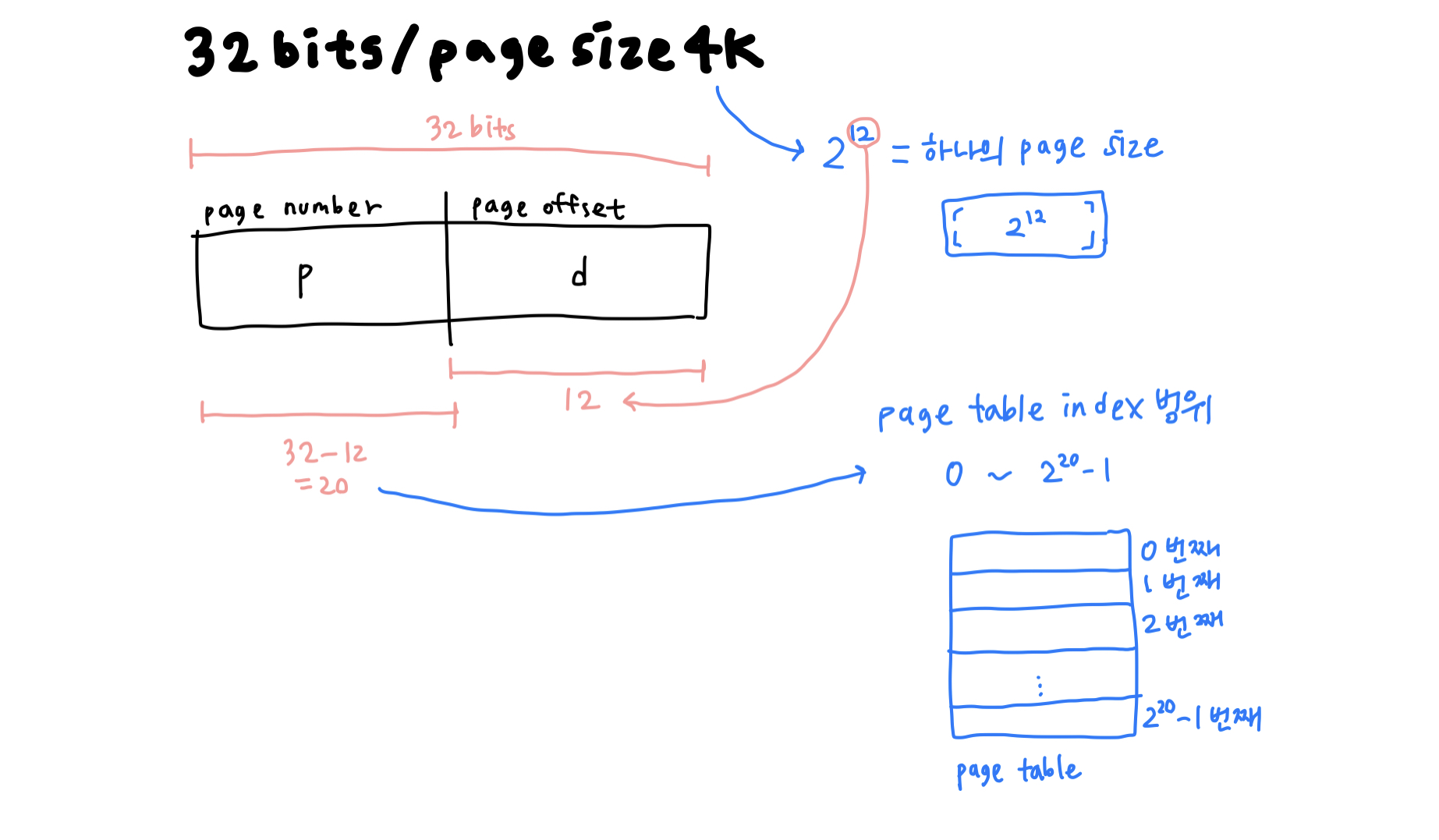
- 하나의 page size는 2^12B구나,
- page table은 2^20개의 칸으로 이루어져 있구나! (0 ~ 2^20 -1 의 index를 가지는 구나)
이해할 수 있다.
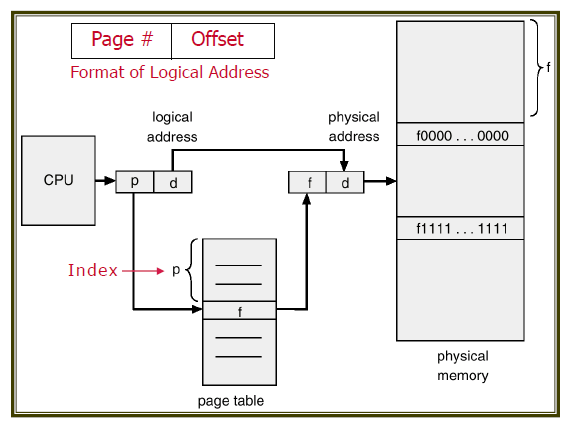
[page number👾 + page offset👻]의 구조를 가진 logical address를 통해 page table로 간다.
page table은 page number👾를 보고 그 칸에 들어 있는 frame number💀를 알려준다.
🤖 : 여기로 가면 돼!phsical address가 완성 됐다. [frame number💀 + page offset👻]
그러면 physical memory의 frame number💀로 가서, page offset👻만큼 더 가면 되는 거다!
[frame number x page 크기 + offset]이 physical address의 정확한 주소인 거다!
찾았다!
② Memory Loading and Free Frames
실행할 process가 memory에 오면, 일단 어디 보자- 얼마만큼의 page로 표현될 수 있는가 가늠해야 한다.
그리고 frame이 몇 개나 비어 있는지 알고 있어야 한다.free frame
비어 있는 frame에 process를 page단위로 잘라 넣고, page table에 어디 frame에 넣었는지 기록한다.
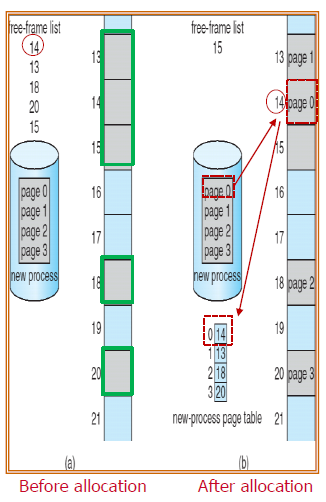
process : 나 좀 커! 여러 page 단위로 되거던?
cpu : 그래? 그럼 자르자. 콩콩콩
어디 보자, 빈 frame이 어디 있더라..여기, 여기, 여기네.
0번째 조각은 여기 넣고, 1번째 조각은 저기, ...
이걸 기록해두자. 이 process의 page table은 ..끄적끄적
0번째 조각은 14번째 frame에 넣었고, 1번째 조각은 13번째 frame..(그럼, 할당되어야 할 page 수와 free frame 수는 같다는 게 보인다.
하지만 /속닥속닥/ virtual memory를 사용하면
free frame 수보다 할당되어야 할 page 수가 더 클 수도 있다! /속닥속닥/ Ch10에서 다룬다)
③ Page Table Implementation
page table은 process와 함께 main memory에 적재된다.
page table을 위한 register도 있다.
- PTBR (page-table base register) : page table을 가리킨다
- PRLR (page-table length register) : page table의 크기
이 레지스터들은 모두 PCB에 담겨있으며 context switching을 통해 옮겨진다.
모든 data/instruction access는 두 번의 memory access를 한다.
page table 찾아가는데 한 번,
data/instruction (physical memory)찾아가는데 두 번.
그래서 overhead가 발생한다.
이를 줄이기 위해서 HW cache인 TLB(translation look-aside buffer = associative memory)를 사용한다.
TLB는 보통 작은 size를 가진다.
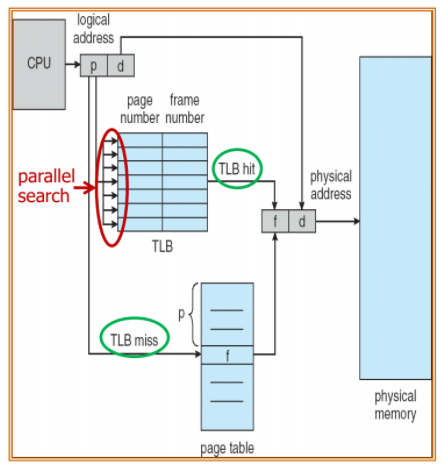
page table의 미니 버전인 TLB cache에서 먼저
logical address의 page number를 parallel search한다.(extra overhead)
TLB에 page number가 있으면 hit! frame number를 찾아 physical address를 완성할 수 있다!
TLB에 page number가 없으면 miss! page table로 가서 page number를 찾고, frame number를 알아내 physical address를 완성한다!
④ Effective Access Time
memory cycle time을 1 microsecond라고 하자.
Associative Lookup(TLB access) = ε
hit ratio(TLB에 있을 확률) = α
Effective Access Time 유효한 접근 시간
EAT = (1 + ε)α + (2 + ε)(1 - α)
= 2 + ε - α
1 + ε : TLB access(ε) + memory access
2 + ε : TLB access(ε, miss) + page table access + memory acccess
1 - α : miss ratio⑤ Memory Protection
예를 들어 process와 관련된 정보에만 메모리 접근을 허용해야 하는데,
막 다른 process 영역 걸 건드리면 안 되기에
memory protection이 필요하다.
이를 위해, 일단 모든 process는 page table을 거치기에
page table은 각 frame마다 protection bit를 가지고 있다.
valid-invalid bit 이라고 부른다.
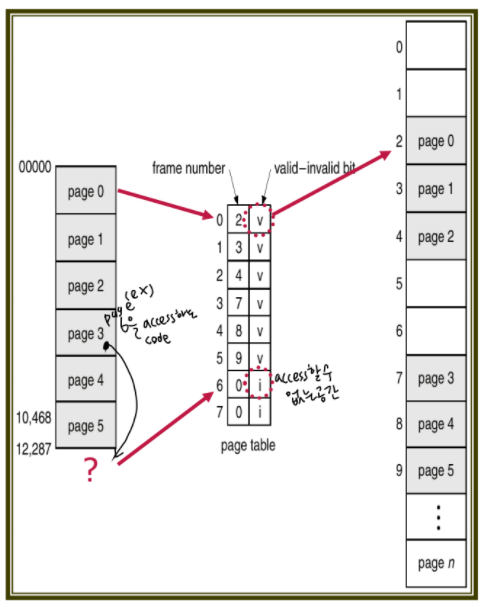
또는 PTLR (page table length register)를 이용한다.
⑥ Shared Pages
page를 공유하는 경우도 있다. (당연히 같은 frame에 정보가 위치한다(
하지만 이때, code는 read-only(reentrant) code여야 한다.
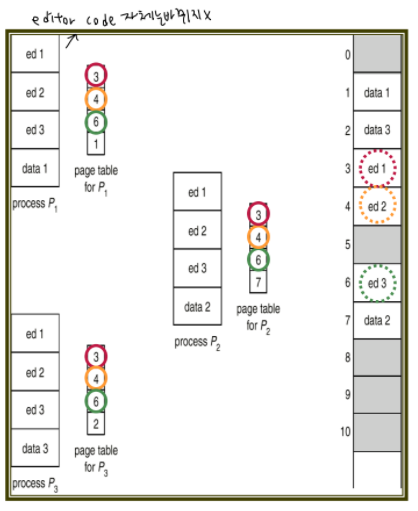
예를 들어 서버 하나에서 100명이 vi editior를 사용한다고 하자.
각 process가 vi editior code에 접근한다.
같은 page를 공유하며, 이 때 메모리에 있는 editior code 자체는 바뀌지 않는다.
⑦ Structure of the Page Table
page table을 어떤 구조로 구현할 수 있을까
⑴ Hierarchical Page Table
page table은 제법 크기가 큰데다 process마다 존재해서 많다!
부피가 참 크다.
또한 page table은 메모리에 연속적 공간으로 저장한다.
어, 연속적 공간을 사용하므로 또다른 dynamic allocation problem을 일으킨다.
page table을 page 단위로 또 나누어서 table을 만들자.
- 2-level page table
예를 들어, 32-bit machine, page size 4K일 때
page offset은 12 bits(4K = 2^12)이며
page number은 20 bits(32-12 = 20)이다.
page table을 또 나누어보자.
10 bits / 10 bits

p1은 outer page table index가 된다.
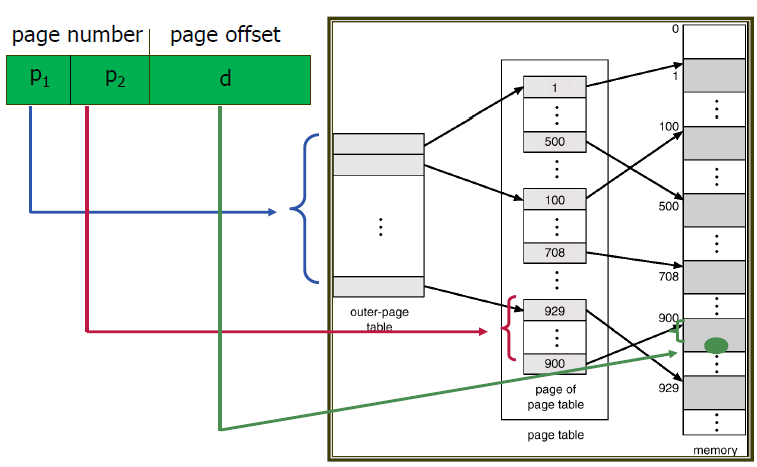
뚜둥뚜둥 단계별로 찾아가는 거다!
자 이때 왜 p2를 10으로 잘랐을까?
p2의 길이가 10이라면 2^10개의 칸(entry)을 갖는다는 것을 말한다.
각 칸(entry)마다 4 bytes를 가진다면 2^10 x 4 = 4K
4K? 이는 offset의 길이와 같다! 즉 page 크기와 같다!
2번째 page table 총 size가 page 하나의 크기라는 말이다!
이제 page table을 메모리에 딱 맞게 쏙 넣을 수 있다.
- For a System with Larger Address Space
64-bit address space를 가지는 system이라면 어떨까.- 2-level을 사용한다?

일단 offset은 12,
p2는 10, 그러면 p1은 64-12-10 = 42
42의 길이를 갖는 p1은 2^42개의 칸(entry)을 갖는다
그러면 한 칸당 4bytes라고 가정한다면,
page table 총 size는 무려 2^42 x 4bytes/entry = 2^44 bytes (16TB)
...우와웅! 너무 크다! 그럼 또 나눠볼까? - 3-level
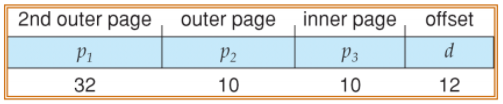
page table 총 size 16GB(2^32 x 4 = 2^34)
그래도 여전히 크다.
그리고 여러 level이 생길수록 TLB miss일 때 access 시간은 길어진다.
- 2-level을 사용한다?
이 방법은 아닌 것 같다. 절레절레
그럼
-
Hashed Page Table
hash function을 이용하여 hash값을 찾아 frame number를 찾는 방법도 있다.

-
Inverted Page Table
process별로 따로 가지고 있던 page table을 합치는 방법도 있다.
pid를 함께 포함한 page table을 구현하여
pid와 page number를 찾아 physical address를 완성한다.
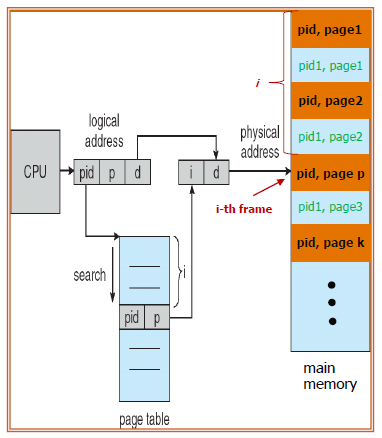
전체적인 page table size를 줄일 수 있다는 장점이 있지만,
table을 search하는 시간이 또 필요하다.
2) Segmentation
paging은 system view였다면 segmentation은 user view이다.
program은 segment의 collection이다.
segment는 main program, procedure, function, method, object...등의 우리가 개념적으로 알고 있는 것들의 묶음이다.
이 묶음끼리는 연속적인 할당을 해주는 것이다.
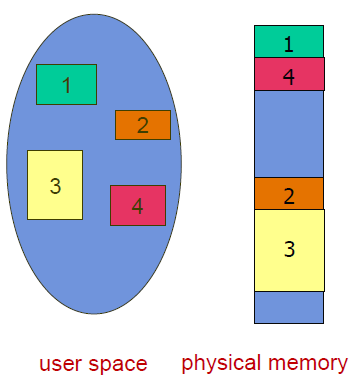
segment table은 variable size를 가지고 있다.
process를 자르는 대신 우리가 아는 개념끼리는 묶어주는 것
logical address는 이러한 구조를 가진다.
<segment-number, offset>
segment table은 두 차원의 physical address 정보를 지니고 있다.
- base : physical address의 시작 지점
- limit : length of segment
segmentation을 위한 두 레지스터도 있다.
- STBR (segment-table base register) : segment table의 위치를 가리킨다
- STLR (segment-table length register) : 프로그램이 사용한 segments 개수를 나타낸다

'segment-number와 offset'의 정보를 가진 logical address에서
segment-number를 segment table의 index로 이용하여 찾아간다.
그 칸에는 두 가지 정보가 있는데, limit, base 정보가 있다.
자, 그럼 offset이 limit을 넘어가는지 확인한다.
넘어가지 않았다면, base와 더해서 physical address를 얻는다.
만약 넘어간다면, trap!
- sharing : 같은 segment number를 이용하여 공유할 수 있다
- protection : segment table에 valid/invalid bit이나 read/write/execute 권한을 주는 방법으로 보호할 수 있다.
- allocation : 각 segment는 first/best fit 을 이용하여 할당할 수 있다(하지만 dynamic allocation problem이 발생한다)
- relocation : dynamic, by segment table
segmentation with paging - IA-32
두 방법을 합쳐서 쓰는 방법도 있다!
각 segment들을 fixed size(page 단위)로 나누는 것이다.
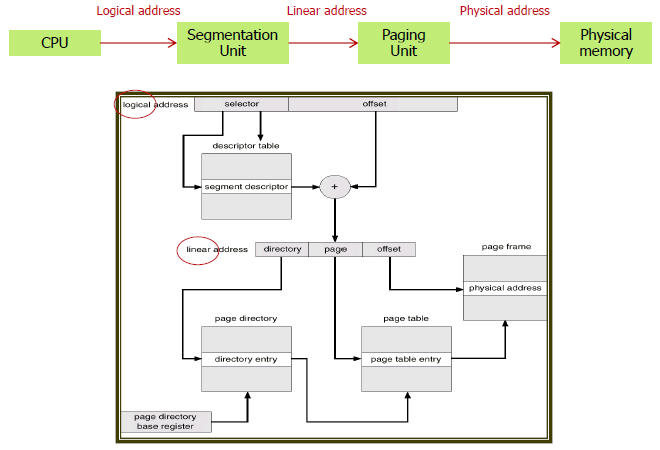
logical address의 segment number를 따라 얻어진 값이 page table을 가리킨다! 는 것
참 길었다! 휴! Ch9가 끝났다. Virtual memory로 가자!
