들어가기
자료구조를 공부할 때나 암호화 해시 함수(SHA-1 등)를 어떤 것으로 선택할 것인지 결정할 때와 같은 순간에 마추치는 개념이 해시다. 이번에 알고리즘 공부를 하다가 해시의 개념을 다시 복습해 보고 싶고, 개발의 꽤 근본 개념이 되는 구나라고 생각이 들어 이곳에 정리하려고 한다. 또, 해시를 구현할 때 충돌(collision) 줄이는 로직을 어떻게 작성할 수 있는가에 대한 여러 가지 방법론을 알아보자.
Hash, Hashing, Hash Function
Hash, 인스타그램에서 해시태그로 많이 들어 본 것 같은데.. 그건 해시 기호(#) 때문에 그렇게 불리는 것이고 자료구조의 해시와는 의미가 다르다고 한다. (어떤 상관관계가 있으려나..?)
아무튼 단순 명료하게 정리하면, 해시(Hash)는 유일한 값(반복되지 않는 값)을 저장하기 위한 자료구조이다. Dictionary(Map)자료 구조와 같이 (key, value) 쌍 형태로 저장한다. 모든 데이터가 유일한 key를 가지기 때문에 해시 자료들은 특정한 값을 아주 빠르게 찾는다는 특징을 가지고 있다. 어떻게? 라고 생각해 보면, 유일 key로 탐색을 빠르게 하는 방법에 대해 쉽게 떠오르는 것이 있을 것 같다.
그렇다. 바로 색인(Indexing)을 가진 값으로의 Mapping을 통해 검색과 저장의 평균적인 시간 복잡도가 O(1)에 수렴하게 만드는 것이다. 또한, 그러려면 아직 색인되어있지 않은 값들을 index값으로 바꿔주어야 하는데 그렇게 해시를 추출하는 과정을 해싱(Hashing)이라고 하고, 그때 사용되는 함수를 해시 함수(Hash Function)라고 한다.
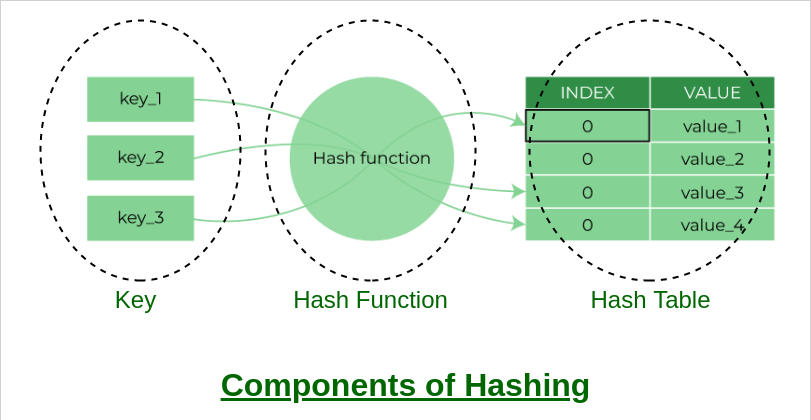
직접 주소 테이블(Direct Address Table)
개념들을 보고 나니 유일한 key가 있다면 그냥 index로 쓰면 되지 않나 하는 의문이 든다. 실제로 그러한 방식은 있다.입력받은 value가 곧 key가 되는 데이터 매핑 방식을 직접 주소 테이블(Direct Address Table)이라고 한다.
하지만 만약 3개의 key가 주어졌다고 가정하자.
- 399
- 645
- 685
이 값을 그대로 테이블에 넣어준다면 각각 인덱스가 399, 645, 685로 저장된 데이터를 제외하고 나머지는 undefined로 채워진다. 그럼 값은 없지만 메모리 공간은 할당되어 있는 상태가 되기 때문에 공간의 효율성이 좋지 못하다.
Javascript에서 직접 주소 테이블을 매핑할 때 Array를 쓴다면, js에서는 배열이 일반적인 밀집 배열(dense array)이 아니고 이미 해시 테이블이기 때문에 메모리와는 상관이 없을 수 있지만 일반적인 이야기를 하겠다. - MDN 관련 내용 참고
그러한 공간의 효율성을 위해서 보통은 인덱스를 매핑하기 위한 해시 함수를 사용하여 테이블을 만들고 그것을 해시 테이블이라고 한다.
해시 테이블(Hash Table)
앞서 말한 문제를 해결하기 위해 해시 함수로 인덱스 매핑된 최종 데이터를 해시 테이블이라고 한다. 인덱스를 통해 액세스 할 수 있는 테이블에 (키, 값) 쌍을 저장되며 생성된다. 그럼 해시 테이블을 Javascript를 사용하여 구현해 보자.
이메일 주소록을 저장해야 하는 상황을 예시로 들어보자.
(이름, 이메일) 의 데이터가 아래와 같이 주어졌다.
- (Gandalf, gandalf@email.com)
- (John, johnsnow@email.com)
- (Tyrion, tyrion@email.com)
우리는 이 값들 중 이름을 Key로 삼아 색인(Indexing) 해야 하고, 그럴려면 앞서 말한 해시 함수를 이용해야 한다. 가장 흔한 형태의 해시 함수는 일명 루즈루즈(lose lose) 함수이다. 키를 구성하는 문자의 아스키(ASCII)값을 단순히 더해서 숫자로 리턴하는 함수이다. 지금은 이걸 예시로 사용해서 아래와 같은 형태로 해시 테이블을 만들어보자.

우선 해시 테이블의 골격부터 만들어준다.
function HashTable() {
const table = [];
}그리고 사용할 해시 함수(HashTable의 private method)를 다음과 같이 작성한다.
// Lose Lose Hash Function
const hashFuction = (key) => {
let hash = 0;
for (var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash;
};key를 구성하는 각 문자의 아스키 값을 합하는 함수다. 결과 값을 저장할 변수를 선언하고, key 문자열의 길이만큼 반복하면서 문자별 아스키 값을 hash 변수에 더한다.(js의 String 객체의 charCodeAt 내장 메소드를 이용한다.)
반복문이 종료되면 Hash의 최종값을 반환한다.
해시 함수를 작성했으니 다음 세 가지 기본 메소드를 추가해 보자.
- add
this.add = (key, value) => {
const position = hashFuction(key);
console.log(position + " - " + key);
table[position] = value;
};key 인자를 해시 함수에 넣고 반환된 결과 값(position)으로 테이블에 저장해야 한다. 여기서는 확인 용도로 position을 콘솔에 표시하는데, 필요 없으면 삭제하거나 주석 처리해도 된다. 어쨌든, table 배열의 position 인덱스에 value를 추가한다.
다음은 데이터를 읽어오기 위한 get 메소드를 작성하자.
- get
this.get = (key) => {
return table[hashFuction(key)];
};앞서 만든 해시 함수로 key의 인덱스를 찾고, 이 인덱스에 해당하는 table 배열의 값을 반환한다.
마지막으로 데이터를 삭제하기 위한 remove 메소드다.
- remove
this.remove = (key) => {
table[hashFuction(key)] = undefined;
};HashTable 인스턴스에서 어떤 원소를 삭제하려면 해시 함수를 이용하여 인덱스를 찾아 table 배열의 값을 undefined로 만들어주면 된다.
HashTable은 Array처럼 table 배열의 원소 자체를 삭제할 필요는 없다. 배열 전체에 원소들이 분포되어 있으므로 어떤 인덱스엔 값이 할당되지 않은 채 기본 값 undefined가 들어 있다. 다음에 기존의 다른 원소를 조회/삭제 시 어차피 해시 함수로 인덱스를 찾을 수 없을 테니 문제될 것은 없다.
이제 HashTable 클래스를 사용해 보자.
const hash = new HashTable();
hash.add("Gandalf", "gandalf@email.com");
hash.add("John", "johnsnow@email.com");
hash.add("Tyrion", "tyrion@email.com");실행 결과, 다음과 같이 콘솔에 출력될 것이다.
- 685 - Gandalf
- 399 - John
- 645 - Tyrion
get 메소드도 잘 작동하는지 시험해보자.
console.log(hash.get("Gandalf"));
console.log(hash.get("SomeoneElse"));결과는 다음과 같다.
- gandalf@email.com
- undefined
Gandalf는 HashTable에 존재하는 key이므로 값을 반환하지만, SomeoneElse라는 key는 없으므로 배열에서 해시 함수에 의해 생성된 인덱스로 접근 시 찾지 못하고 undefined(존재하지 않음)를 반환한다.
이번엔 Gandalf를 테이블에서 지워보자.
hash.remove("Gandalf");
console.log(hash.get("Gandalf")); Gandalf는 더 이상 없으므로 실행 결과는 undefined이다.
공간 효율성은 아직 좋지 못하다
하지만 위의 결과에서 확인할 수 있듯이 아직도 3개의 값에 매핑된 인덱스는 각각 399, 645, 685로 이 값들 이외의 빈 공간이 너무 많다. 그래서 보통은 해시 함수 내의 결과값 리턴 전에 특정 숫자를 나누어 준 나머지 값을 리턴한다던지 하는 방법을 사용하여 값을 줄여준다.
// Lose Lose Hash Function
const hashFuction = (key) => {
let hash = 0;
for (var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37; // 10을 나누어고 나머지 숫자를 리턴한다.
};그러면 리턴되는 값은 무조건 0~36 사이의 값이 나온다. 그럼 위의 예시에서 매핑된 인덱스는 각각 399, 645, 685에서 29, 16, 19로 줄어들 것이다. 위에서는 최대 685번째 인덱스에 값을 저장하고 682개의 빈 공간을 가진 테이블을 생성해야 했지만 지금은 최대 29의 크기를 가진 테이블을 생성하면 된다.
충돌(Collision)
하지만 이러한 방식은 당연히 인덱스간 충돌을 마주한다. 수 많은 데이터를 37개의 인덱스로만 뽑아낸다면 중복된 값이 나오는게 당연하다. 해시 함수에 입력할 수 있는 데이터의 가짓수는 무한한데, 출력으로 나올 수 있는 해시 값이 유한하기 때문에 발생한다는 것이다.
(이러한 특징을 비둘기집 원리라고 한다.)
그래서 해시 함수를 고도화해서 충돌을 최대한 줄이기도 하고, 테이블을 생성할 때 다양한 방법론을 통해 해결하기도 한다. 고도화된 해시 함수는 유명한 것이 많고 암호화에도 사용된다(MD5, SHA 등). 다양한 정보들을 알고리즘을 통해 고정된 길이의 데이터로 매핑하면 암호화된 데이터로 사용하기에 많은 장점이 있기 때문이다. 여러 해시 함수에 대한 내용을 정리하자면 너무 길어지니 이번에는 깊게 보지 말고 방법론만을 정리해보자. 방법론의 경우도 유명한 것이 많지만 몇 개만 정리해 보겠다.
선형 탐사법(Linear Probing)
방법론 중 가장 간단한 원리를 가지고 있고, 단순히 매핑해야 할 인덱스에 이미 값이 들어가 있을 경우에 한 칸씩 이동해보며 빈 공간을 찾아 나서는 방법이다. 아래의 간단한 충돌 상황을 보자.
const hashFuction = (key) => {
return key % 10;
}
console.log(hashFuction(9)); // 9
console.log(hashFuction(99)); // 9값 9을 해싱하여 9번 인덱스로 테이블에 매핑했다고 가정하자. 그러면 다음 값 99는 9번 인덱스에 이미 값 9가 매핑되어 있기 때문에 충돌되어 넣을 수 없다. 이를 피하기 위해 10번 인덱스로 가서 할당된 값이 없으면 값 99를 매핑한다. 만약 다음 값에서 또 9번 인덱스를 해시값으로 가진다면 9번, 10번을 거쳐 11번 인덱스에 매핑되면 된다.

제곱 탐사법(Quadratic probing)
하지만 선형 탐사법은 이런 식으로 덩치가 커지기 때문에 특정 해시값 주변 인덱스가 모두 채워져 있는 일차 군집화(primary clustring)문제에 취약하다고 한다. 그래서 한칸씩 늘어나는 것이 아닌 제곱수로 늘어나는 제곱 탐사법도 있다.
데이터 매핑에서 충돌이 일어나면 1의 제곱값의 칸을 옮긴다. 여기에서도 충돌이 일어나면 이번엔 2의 제곱값을, 그 다음엔 3의 제곱값을 옮기는 식이다.

이렇게 하면 충돌이 발생하더라도 데이터의 밀집도가 선형 탐사법보다 많이 낮아지기 때문에 다른 해시값까지 영향을 받아서 연쇄적으로 충돌이 발생할 확률이 많이 줄어든다.
그래도 결국 해시값이 9로 여러 번 나올 때, 즉 하나의 해시값이 계속 나온다면 연속적인 충돌이 발생하는 것은 피할 수 없다. 결국 데이터의 군집은 피할 수 없고 이차 군집화(Secondary Clustering)문제를 야기한다.
이중 해싱(Double Hashing)
이중 해싱은 말 그대로 해시 함수를 이중으로 사용하는 것을 말한다. 2개의 해시 함수를 준비해서 하나는 최초의 해시값을 얻을 때, 또 다른 하나는 해시의 충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용한다. 이렇게 되면 최초 해시값이 같더라도 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시값이 달라져 일차 군집화(primary clustring)문제와 이차 군집화(Secondary Clustering)문제 모두를 완화할 수 있다.
체이닝 (Chaining)
위의 방법들은 해시값 하나에 이미 매핑된 값들이 있어 점유된 인덱스를 피해야 했다. 하지만 점유된 인덱스를 피하지 않고 점유된 인덱스에 어떻게든 자료를 추가하는 방식들도 있다. 체이닝 방법은 연결 리스트(Linked List)를 이용해서 이러한 방법을 구현한 것 중 하나다. (트리 구조를 사용하는 방식도 있다.)
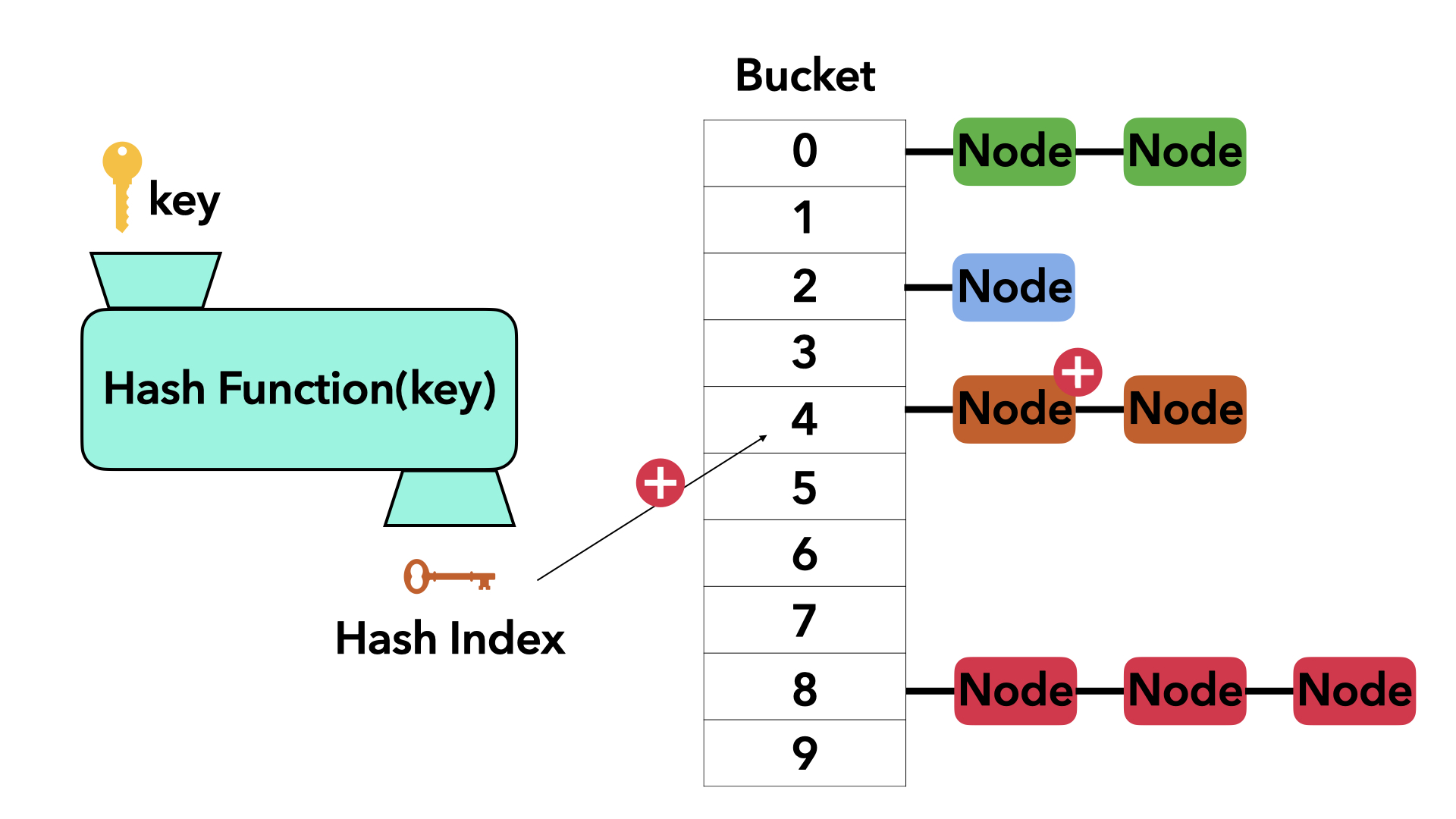
이런식으로 하나의 인덱스에 충돌이 난다면 기존의 값에 충돌된 값을 next 포인트로 연결해서 Linked List를 만든다.
앞서 만든 해시 테이블 add 메서드 코드에 이를 추가를 해보면 다음과 같다.
this.add = (key, value) => {
const position = hashFuction(key);
const node = new Node(key, value); // 연결 리스트의 노드 (연결 리스트 코드는 생략한다.)
if(table[position]) {
// 기존에 데이터가 있을 경우
// 새 데이터를 head에 넣고 next에 기존 데이터를 이어준다.
const current = table[position];
table[position] = node;
table[position].next = current;
} else {
// 기존에 데이터가 없을 경우
// 새 데이터를 head로 넣어준다.
table[position] = node;
}
};이런식으로 매핑한다면 같은 인덱스에 중첩된 값이 오더라도 충돌이 날 경우는 없을 것이다.
데이터를 불러와야하는 경우도 앞서 만든 해시 테이블 get 메서드 코드에 다음과 같이 추가해 보자.
this.get = (key) => {
const position = hashFuction(key);
let current = hashTable[position];
while (current) {
if (current.key === key) break;
current = current.next;
}
return current.value;
};마무리
자주 마주치는 개념인데 확실하게 정리한 건 처음인 것 같다. 이런 식의 시간들이 많을수록 제대로 공부하는 것이라고 생각하지만 겉핧기로 공부할 때가 더 많은 것 같다. 제대로 하는 공부를 꾸준히 해서 퍼즐이 맞춰지는 느낌을 자주 마주칠 수 있도록 해야겠다.
참고
Learning JavaScript Data Structures and Algorithms 한국어판
ratsgo님 블로그
Plus Ultra님 블로그

6개의 댓글

안녕하세요, 포스팅 읽으며 많은 공부가 됐습니다 감사합니다! :)
그런데 포스팅을 읽다가 조금 궁금한 점이 생겨 여쭤봅니다!
/ Lose Lose Hash Function
const hashFuction = (key) => {
let hash = 0;
for (var i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37; // 10을 나누어고 나머지 숫자를 리턴한다.
};그러면 리턴되는 값은 무조건 0~36 사이의 값이 나온다. 라고 하셨는데,
hash 값이 0일 일이 없어서 0~36 사이의 값이 나온다고 하신 게 맞으실까요?
정보 감사합니다. https://news.hada.io/topic?id=13627 기사에서 해시 테이블 자료구조로 검색 시간을 상당히 단축해서 궁금하던차에 덕분에 많이 알아갑니다!