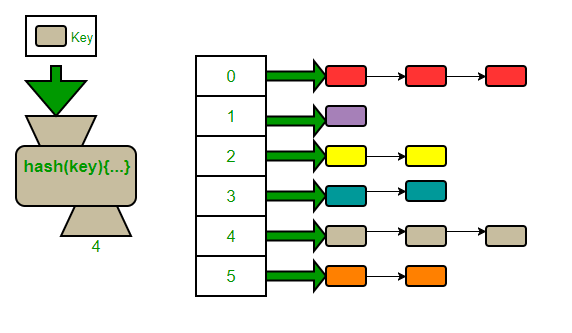
해시테이블
해시 테이블은 키(key)와 값(value) 한 쌍의 데이터를 저장한다.
배열에서 값을 찾는 경우
선형 탐색으로 데이터량에 비례해 계산 시간이 늘어난다.
해시 테이블 (데이터 저장)
하나의 데이터를 추가할 때
e.g.) Kim(키):25(값)
1. 데이터를 저장하기 위한 배열을 준비한다.
e.g.) 길이가 5인 배열
2. 해시 함수를 이용해 키의 해시값을 계산한다.
e.g.: Kim - hash(Kim) -> 해시값 5342
3. 구한 해시값을 배열의 길이(여기서는 5)로 나누어 나머지를 구한다.
e.g.) 5342 mod 5 = 2
4. 구한 수와 동일한 배열 인덱스에 해당 데이터를 저장한다.
e.g.) 배열[2]에 Kim의 데이터를 저장
5. 위의 처리를 반복해서 다른 데이터도 배열에 저장한다.
e.g.) Lee(키):31(값)
Lee - 해시함수 -> 해시값 4821
4821 mod 5 = 1
배열[1]에 Lee의 데이터를 저장
Jay(키):28(값)
Jay - hash(Jay) -> 해시값 2683
2683 mod 5 = 3
배열[3]에 Jay의 데이터를 저장
6. 아래와 같이 이미 배열[인덱스]에 값이 있는 경우가 발생한다.
e.g.) Yoon(키):33(값)
Yoon - hash(Yoon) -> 해시값 3782
3782 mod 5 = 2
배열[2]에 Yoon의 데이터를 저장
6-1. 이런 경우 리스트 구조로 기존 데이터와 연결한다.
해시 테이블은 몇 가지 종류가 있는데
리스트를 이용하는 방법을 연쇄법이라고 한다.
7. 모든 데이터를 저장하면 해시 테이블이 완성된다.
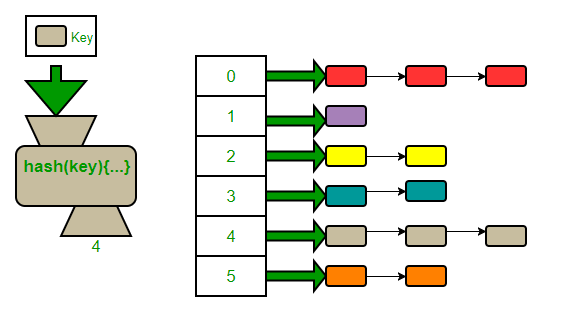
해시 테이블에서 값을 찾는 경우
* Yoon의 나이를 찾는 경우
Yoon의 나이가 몇 번째 인덱스에 저장돼 있는지 알기 위해서
1. Yoon의 해시값을 구해서 배열의 길이로 나머지를 구한다.
e.g.) Yoon - hash(Yoon) -> 해시값 3782
3782 mod 5 = 2
2. 배열[2]에 저장된 데이터가 있다.
배열[2]에 있는 리스트를 선형 탐색한다.
3. 대응하는 데이터를 찾으면 Yoon의 나이가 33세인 것을 알 수 있다.해시 테이블의 장점
해시 테이블은 해시 함수를 이용해 배열 내 특정 데이터에 빠르게 접근할 수 있다
Separate Chaining 방식
Linked List를 이용해 해시값이 충돌하더라도 유연하게 대응할 수 있다.
해시 테이블에서 사용하는 배열의 크기는 너무 작으면
충돌이 많아지고 선형 탐색의 빈도가 높아지게 된다.
반대로 배열의 크기가 너무 크면
데이터가 없는 상자가 많아지므로 메모리를 낭비하게 된다.
