Batch??
Batch는 대량의 데이터나 작업을 자동화하여 처리하는 일괄처리 방식을 의미한다. 일괄처리는 대용량 데이터를 처리하고, 백그라운드에서 실행되어 시스템 리소스를 효율적으로 사용하고, 빠르고 안정적이다.
Batch는 배치 프로그램 형태로 작성되어, 주로 일반적인 컴퓨터 시스템에서 별도의 요청없이 실행된다. 예시로는 계좌 거래 내역 처리, 신용 카드 결제 내역 처리, 대규모 데이터 분석 및 가공 등이 있다.
Batch는 따라서 일정 주기나 일정 시간마다 실행되며, 이를 스케줄링하여 자동으로 실행할 수 있다. 최근에는 데이터 처리 및 분석을 위한 Batch 프로세싱을 활용하는 것이 중요하고, Spring에서 사용하는 프레임워크가 바로 Spring Batch이다. 또한 스케줄러를 사용하기 때문에 Spring Quartz와 같은 스케줄러도 지원한다. → 이건 나중에 알아보기로 하자.
Spring Batch에서는 크게 두 가지 형태로 작업을 처리할 수 있다.
- Chunk-Oriented Processing
- TaskletStep
Chunk-Oriented Processing
Spring Batch의 핵심 패턴 중 하나이다. 해당 패턴에서는 입력 데이터를 미리 정의된 크기의 덩어리(chunk)로 분할한다. 이후 각 덩어리를 순차적으로 처리한다.
아키텍처를 보면서 이해해보자.
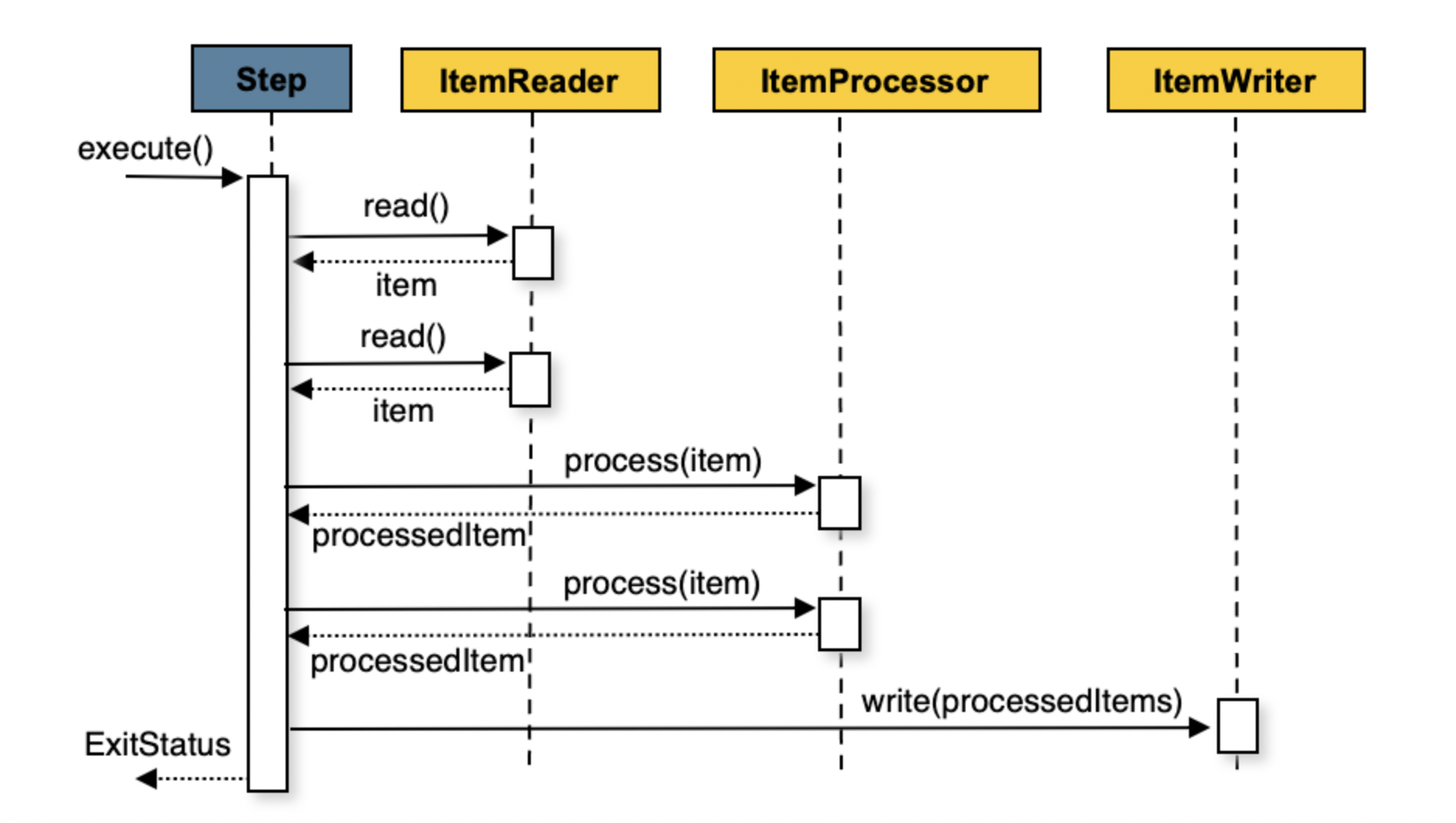
ItemReader
입력 데이터를 읽는 데 사용된다. 입력데이터를 Chunk 단위로 읽어들인다. 파일의 형식에 따라 Reader를 골라서 사용할 수 있다.
ItemProcessor
ItemProcessor에서 단위 데이터를 처리한다. 데이터를 가공하여 출력데이터를 생성한다. 각 데이터를 변환하거나, 유효성 검사를 실시하거나, 필드를 추가할 수 있다.
ItemWriter
처리된 데이터를 출력한다. 데이터베이스에 저장하기 위해서 JdbcBatchItemWriter를 사용하여 chunk 단위로 데이터베이스에 저장할 수 있다.
전체 과정이 새롭지만 간단하게 요약하자면 읽고, 가공하고, 저장하고의 과정을 거친다. → 갑자기 아주 간단해짐.
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DataSource dataSource;
@Bean
public ItemReader<Person> reader() {
JdbcCursorItemReader<Person> reader = new JdbcCursorItemReader<>();
reader.setDataSource(dataSource);
reader.setSql("SELECT id, firstName, lastName FROM people");
reader.setRowMapper(new PersonRowMapper());
return reader;
}
@Bean
public ItemProcessor<Person, Person> processor() {
return new PersonItemProcessor();
}
@Bean
public ItemWriter<Person> writer() {
JdbcBatchItemWriter<Person> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("INSERT INTO processed_people (id, firstName, lastName) VALUES (:id, :firstName, :lastName)");
writer.setDataSource(dataSource);
return writer;
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Person, Person> chunk(10)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
@Bean
public Job processJob() {
return jobBuilderFactory.get("processJob")
.incrementer(new RunIdIncrementer())
.flow(step1())
.end()
.build();
}
}Tasklet
마찬가지로 작업을 수행하기 위한 인터페이스이다. 해당 인터페이스를 이용하여 Reader, Processor, Writer의 조합이 하는 일을 똑같이 처리할 수 있다. 그러나 이를 직접 구현하기 위해서는 매우 복잡한 코드가 소요된다. 따라서 해당 인터페이스를 이용해서는 단일로 수행될 커스텀한 기능들을 선언할 때 사용한다. → 보통 매우 간단한 작업들을 작성한다.
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("helloJob")
.start(helloStep())
.build();
}
private Step helloStep() {
return stepBuilderFactory.get("helloStep")
.tasklet(((contribution, chunkContext) -> {
System.out.println("Hello Spring Batch");
return RepeatStatus.FINISHED;
})).build();
}
}인사를 해 보았다.
Spring Batch의 전반적인 흐름에 대해 알아봤다. 다음에는 Quartz 스케줄러 사용, 대용량 데이터베이스 처리와 같은 것들을 다루어 볼 예정이다.
- 이미지 출처
