[Java] 엘라스틱 서치 + Docker Compose
Spring yml 설정
일단 메인 디렉토리에
docker-compose.yml을 만들어 준다.
이는 도커 컨테이너 설정 파일을 만든 것이며
이리 하면 docker-compose up를 자동적으로 사용해 설정을 읽는다
version: '3.8' # Docker-compose 파일 포맷 버전
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:9.0.0 #도커 다운로드 이미지
container_name: es-container #이미지로 만들 컨테이너 이름
environment:
- discovery.type=single-node # 단일 노드 클러스터 사용
- ES_JAVA_OPTS=-Xms512m -Xmx512m #Elasticsearch JVM 메모리 설정 (512MB 고정)
- xpack.security.enabled=false # 개발환경 보안 비활성화
ports:
- "9200:9200" #ElasticSearch 용 포트 개방
volumes:
- es-data:/usr/share/elasticsearch/data #Elastic Search로 저장된 정보가 등록되는 공간
networks:
- elastic #네트워크 이름 elastic
#volume 설정
volumes:
es-data:
driver: local #로컬 디스크에 저장 (기본),컨테이너가 사라져도 남아있음
#만약 컨테이너와 함께 정보를 지우고 싶다면 docker-compose down -v로 볼륨도 지워야지 데이터가 같이 사라짐
#networks 설정
networks:
elastic:
driver: bridge # Docker 기본 네트워크 드라이버 (가상 네트워크, 컨테이너 간 통신 가능)
를 설정 한다.
도커 이미지
https://www.elastic.co/docs/deploy-manage/deploy/self-managed/install-elasticsearch-docker-basic
도커의 공식 이미지는
docker.elastic.co/elasticsearch/elasticsearch:9.0.0공식 사이트에 들어가면 위와 같이 알 수 있다.
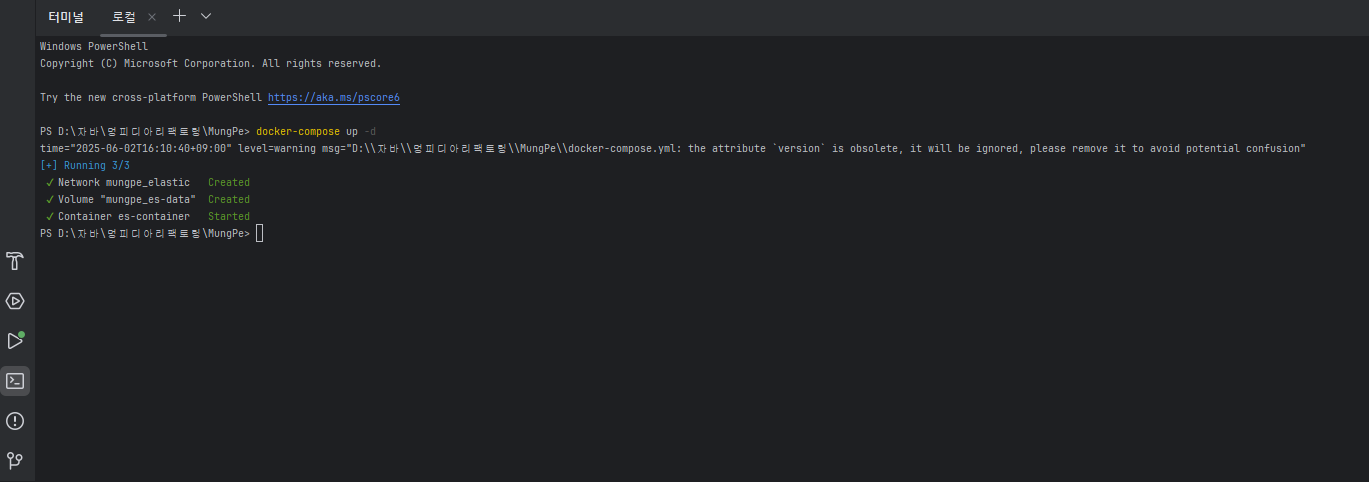
그 후에는 터미널에서 docker-compose up -d 를 실행하면 된다.
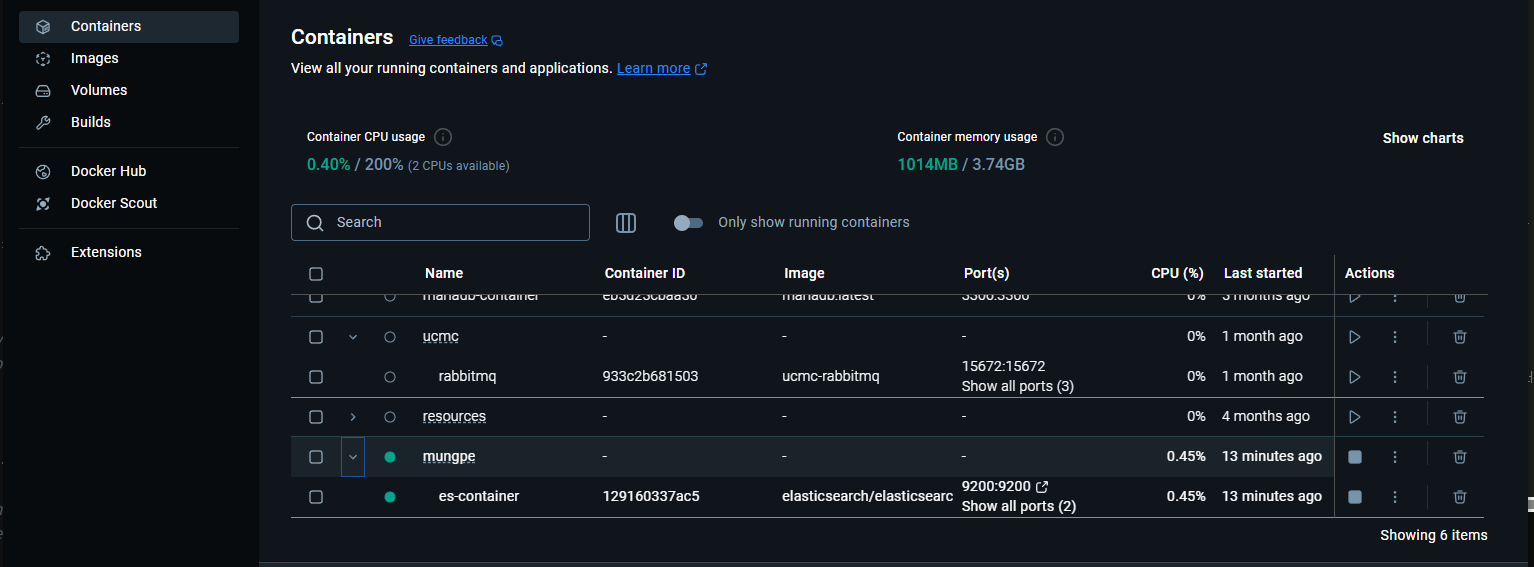
성공 했다면 docker-desktop 에서 이렇게 작동이 될 것이고
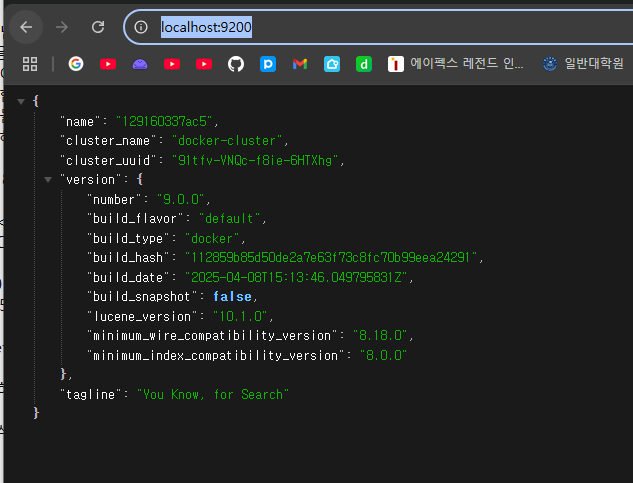
docker desktop이 없다면 인터넷에서 http://localhost:9200 로 접속 시에 위와 같은 화면이 나온다면 문제가 없는 것이다.
그래들 추가
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'yml 추가
spring:
elasticsearch:
uris: http://localhost:9200
username: # 보안 활성화 시 필요
password: # 보안 활성화 시 필요java 설정
dto
@Data
@Document(indexName = "documents")
@EqualsAndHashCode(onlyExplicitlyIncluded = true)
public class SearchDto {
@Id
@EqualsAndHashCode.Include
private String id;
private String title;
private String content;
}위 클래스는 Elasticsearch 문서 매핑 클래스이다.
title과 content는 내가 검색 대상으로 삼을 필드 이름이며, 이 필드들에 대해 부분 검색(Containing) 또는 전문 검색(Full-text Search) 을 수행할 수 있다.
Elasticsearch는 RDB와 별개의 검색 전용 저장소이며, DB처럼 영속성을 가지지만 Spring Data JPA와는 별도로 작동한다.
따라서 기본 DB를 삭제해도, Elasticsearch에 저장된 문서들은 삭제되지 않는다.
Elasticsearch에 저장된 정보는 컨테이너 내부 경로 또는 외부에 마운트된 volume 경로에 저장된다,
그렇기에 Docker로 컨테이너를 삭제하거나 해당 볼륨을 정리해야만 완전히 제거된다.
Repository
public interface ElasticRepository extends ElasticsearchRepository<SearchDto, String> {
List<SearchDto> findByTitleContaining(String keyword);
List<SearchDto> findByContentContaining(String keyword);
}위 메서드들은 주어진 keyword가 title 또는 content 필드에 포함되어 있는지(부분 일치) 확인한 후, 해당 문서들을 반환한다.
게시물 등록 Service
@Override
@Transactional(readOnly = false)
public BoardMessageResponse createPost(BoardRequest request, List<MultipartFile> sourceImage) throws IOException {
// 포스트 저장
Board newPost = savePost(request);
log.info("newPost = {}", newPost);
List<byte[]> files = imageConvertService.convert(sourceImage);
for (byte[] fileData : files) {
//유니크 파일 경로 만들기
String fileName = UUID.randomUUID().toString();
//s3 업로드
String imageUrl = s3StorageService.upload(fileData,fileName);
log.info("imageUrl = {}", imageUrl);
// product image 객체 생성
imageService.savePostImage(imageUrl, newPost.getId(), ImageDomainType.POST);
}
//엘라스틱 서치에 추가
SearchDto dto = new SearchDto();
dto.setId(Type.BOARDDATA + "_" + newPost.getId().toString());
dto.setTitle(newPost.getTitle());
dto.setContent(newPost.getContent());
elasticRepository.save(dto);
return BoardMessageResponse.builder()
.message("Success Created Post")
.result(true)
.build();
}
기존의 게시물 작성 코드에 SearchDto 객체를 생성 해주는 코드를 추가 해준다.
검색 Service
@Slf4j
@Service
@RequiredArgsConstructor
public class ElasticService {
private final ElasticRepository elasticRepository;
private final BoardService boardService;
private final PediaService pediaService;
public SearchBothResponse searchInfo(String keyword) {
// 반환용 게시판 리스트
List<GetBoardMessageReponse> boardResponses = new ArrayList<>();
// 게시판 검색
List<SearchDto> boardResults = mergeResults(keyword);
for (SearchDto boardResult : boardResults) {
Long postId = Long.valueOf(boardResult.getId().split("BOARDDATA_")[1]);
GetBoardMessageReponse post = boardService.getPost(postId);
boardResponses.add(post);
}
SearchBothResponse result = SearchBothResponse.builder()
.message("Success Get Both Document")
.result(true)
.boardResults(boardResponses)
.build();
return result;
}
//title을 검색한 내용과 Content로 검색한 내용이 LinkedHash로 겹치는 것을 합쳐준다.
public List<SearchDto> mergeResults(String keyword) {
Set<SearchDto> mergedSet = new LinkedHashSet<>();
List<SearchDto> byTitleContaining = elasticRepository.findByTitleContaining(keyword);
List<SearchDto> byContentContaining = elasticRepository.findByContentContaining(keyword);
mergedSet.addAll(byTitleContaining);
mergedSet.addAll(byContentContaining);
List<SearchDto> mergedList = new ArrayList<>(mergedSet);
log.info("mergedList = {}", mergedList);
return mergedList;
}
}
keyword로 title과 content를 각각 검색했을 때, 동일한 문서가 중복으로 검색될 수 있다.
이를 방지하기 위해 LinkedHashSet을 사용하여 중복을 제거하면서도 삽입 순서를 유지한 결과 리스트를 만든다.
Controller
@Slf4j
@RestController
@RequestMapping("/api/search")
@RequiredArgsConstructor
public class ElasticController {
private final ElasticService elasticService;
@GetMapping(path = "/both")
public ResponseEntity<SearchBoardResponse> searchBoth(@RequestParam String keyword) {
log.info("Search Both 컨트롤러 도착");
SearchBoardResponse result = elasticService.searchInfo(keyword);
log.info("result = {}", result);
return ResponseEntity.ok(result);
}
}
이렇게 하면 기본적인 엘라스틱 서치의 설정은 끝난다.
