03-1. 소스 코드와 명령어
고급 언어와 저급 언어
고급 언어
- 우리가 흔히 사용하는 파이썬, JAVA, C 같은 프로그래밍 언어
- 개발자가 이해하기 쉽게 만든 언어
저급 언어(명령어)
-
컴퓨터가 이해하고 실행하기 위해 만들어진 언어
-
모두 명령어로 이루어져 있음
-
- 기계어 : 0과 1로 이루어진 명령어로 구성된 저급 언어 (16진수로 표현할 때도 있음)
-
- 어셈블리어 : 기계어를 사람이 읽기 편한 형태로 번역한 저급 언어
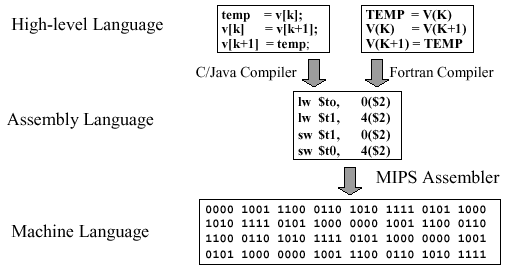
고급 언어 저급 언어
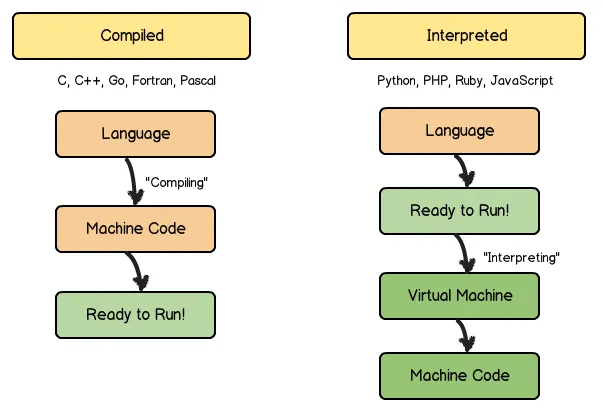
고급 언어에서 저급 언어로 변환은 크게 두가지가 있음
-
컴파일 언어는 소스 코드를 컴파일 하는 도중에 오류가 발생하면 소스 코드 전체가 실행되지 않음
-
인터프리터 언어는 소스 코드를 인터프리트 중 오류가 발생하면, 오류가 발생하기 전까지의 코드는 실행됨
-
프로그래밍 언어가 반드시 컴파일/인터프리터로 양분 되는 것은 아니다!
컴파일 언어
소스 코드(고급 언어) 컴파일러(컴파일) 목적 코드(저급 언어)
-
컴파일러가 전체 소스 코드를 본 다음에 통째로 목적 코드로 컴파일 해줌
-
컴파일 언어로 작성된 소스 코드는 컴파일러에 의해 저급 언어로 변환되고(컴파일 과정), 컴파일의 결과로 저급 언어인 목적 코드가 생성됨.
인터프리터 언어
인터프리터에 의해 한 줄씩 실행
- 소스 코드 전체가 저급 언어로 변환되기까지 기다릴 필요 없음
03-2. 명령어의 구조
무엇을 대상으로 무엇을 수행하라.
- 명령어는 크게 연산코드(op-code)과 오퍼랜드(operand)으로 이루어져 있음
연산 코드
수행할 연산
- 연산 코드는 CPU마다 다양함
-
데이터 전송
- MOVE : 데이터를 옮겨라
- STORE : 메모리에 저장하라
- LOAD(FETCH) : 메모리에서 CPU로 데이터를 가져와라
- PUSH : 스택에 데이터를 저장하라
- POP : 스택의 최상단 데이터를 가져와라
-
산술/논리 연산
- ADD / SUBTRACT / ... : 사칙 연산
- INCREMENT / DECREMENT : 오퍼랜드에 1을 더해라 / 빼라
- AND/ OR / ... : 논리 연산
- COMPARE : 두 개의 숫자 또는 TRUE / FALSE 비교
-
제어 흐름 변경
- 실행의 순서를 옮기는 유형
-
입출력 제어
- READ / WRITE / ...
오퍼랜드
연산에 사용될 데이터 또는 연산에 사용될 데이터가 저장된 위치(주소 필드)
-
연산에 사용되는 값 자체보다는 연산에 사용되는 데이터가 저장된 위치가 더 자주 담긴다
-
오퍼랜드가 없는 경우(0-주소 명령어)도 존재하며 오퍼랜드가 여러 개 인 경우(n-주소 명령어)도 있을 수 있음
명령어 주소 지정 방식
명령어에 값 자체를 안 넣고 주소를 넣는 이유??
명령어의 오퍼랜드로 데이터를 표현한다면 데이터의 크기가 한정되므로, 메모리 주소 또는 레지스터 주소를 저장함
Register Addressing Mode
유효 주소(effective address)
- 연산에 사용할 데이터가 저장된 위치
명령어 주소 지정 방식(addressing modes)
- 연산에 사용할 데이터가 저장된 위치를 찾는 방법 ( =유효 주소를 찾는 방법)
- 다양한 명령어 주소 지정 방식들
1. Immediate addressing mode 즉시 주소 지정 방식
-
연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시(the value of operand is explicitly mentioned)
-
가장 간단한 형태의 주소 지정 방식
-
연산에 사용할 데이터의 크기가 작아질 수는 있지만 빠름
Example
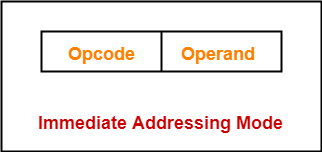
value 앞에 붙은 #은 immediate value를 의미함.
만약 #가 없으면 주소를 의미함
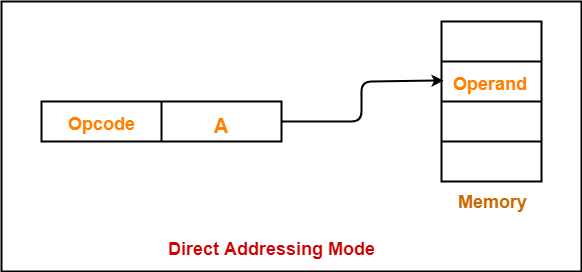
2. Direct addressing mode 직접 주소 지정 방식
-
오퍼랜드 필드에 유효 주소를 직접적으로 명시
-
유효 주소를 표현할 수 있는 크기가 연산 코드만큼 줄어듬
-
다른 말로는 Absolute Addressing Mode
Example
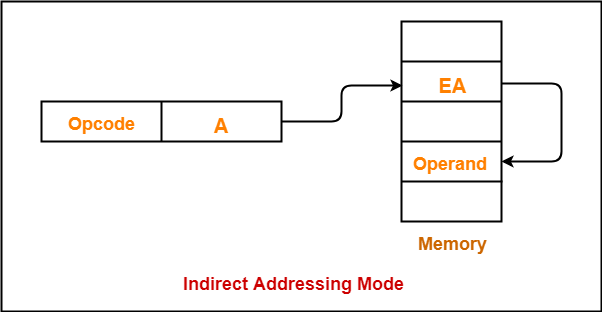
3. Indirect addressing mode 간접 주소 지정 방식
-
오퍼랜드 필드에 유효 주소의 주소를 명시
-
앞선 주소 지정 방식들에 비해 속도가 느림
-
CPU가 메모리를 탐색하면서 찾는 속도는 느리다
Example
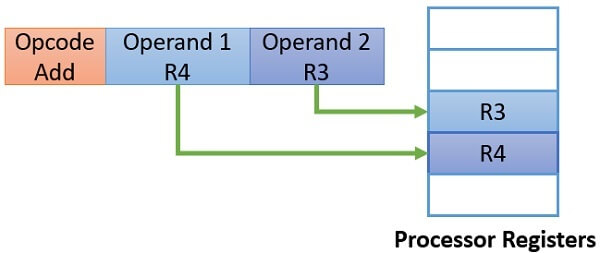
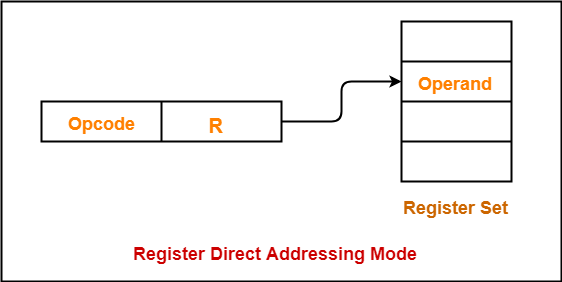
4. Register addressing mode 레지스터 주소 지정 방식
-
연산에 사용할 데이터가 저장된 레지스터 명시
-
메모리에 접근하는 속도보다 레지스터에 접근하는 것이 빠름
-
메모리는 CPU의 밖에 있고, 레지스터는 CPU 내부에 존재하기 때문
Example
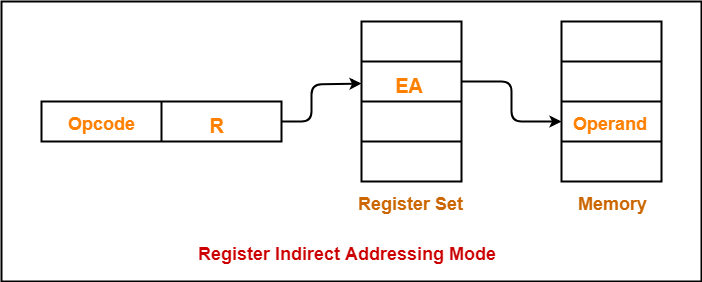
5. Register indirect addressing mode 레지스터 간접 주소 지정 방식
-
연산에 사용할 데이터를 메모리에 저장
-
그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
Example
03-3. C 언어의 컴파일 과정
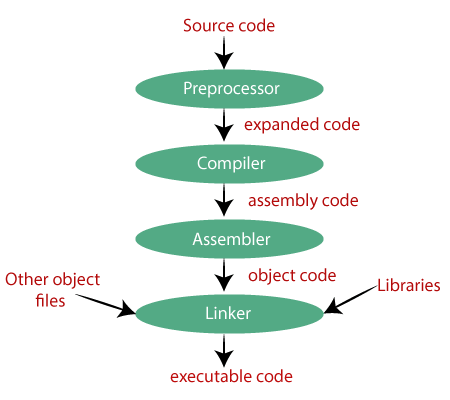
전처리기 -> 컴파일러 -> 어셈블러 -> 링커
Preprocessor
test.c test.i
-
본격적으로 컴파일하기 전에 처리할 준비작업들
-
외부에 선언된 다양한 소스코드, 라이브러리 포함 (e.g. #include)
-
프로그래밍의 편의를 위해 작성된 매크로 변환 (e.g. #define)
-
컴파일할 영역 명시 (e.g. #if, #ifdef, ...)
Compiler
test.i test.s
-
전처리가 완료 되어도 여전히 소스 코드
-
전처리가 완료된 소스 코드를 어셈블리어로 변환
Assembler
test.s test.o
-
어셈블리어를 기계어로 변환
-
목적 코드를 포함하는 목적 파일이 됨
Linker
test.o test.exe
- 서로 다른 목적 코드를 하나의 실행 코드로 엮어 주는 과정
03-3. Python의 컴파일 과정
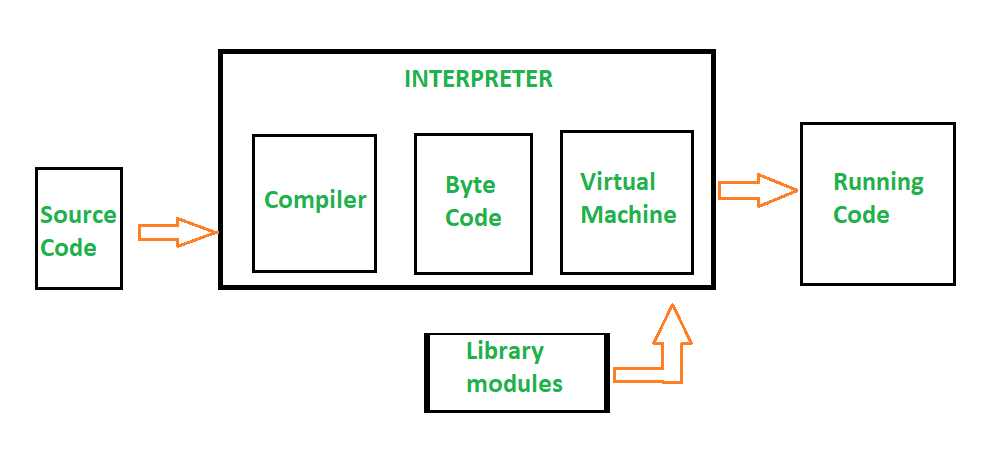
- 파이썬은 컴파일 과정없이 interpreter가 소스 코드를 한 줄씩 읽어서 바로 실행하는 언어.
Compiler
test.py test..pyc
- 소스 코드를 bytecode(저급 언어)로 컴파일
PVM (Python Virtual Machine)
-
.pyc파일에서 한 줄씩 읽어서 실행 -
이때 bytecode를 기계어로 바꾼 후에 CPU에서 연산을 수행함
