Telemetry
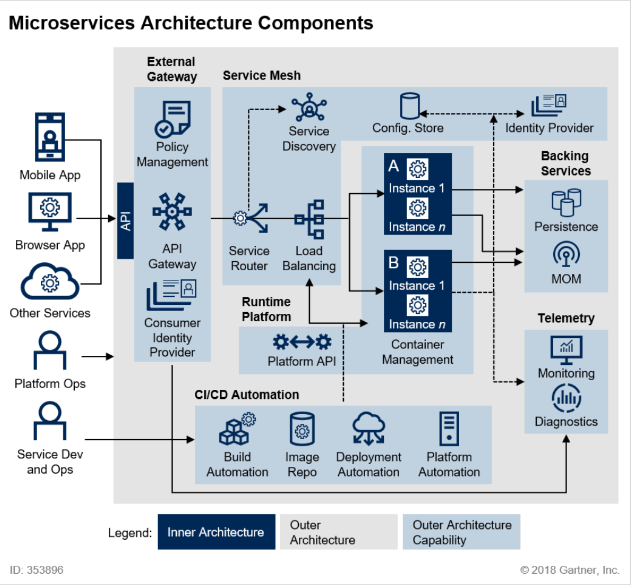
1. Telemetry의 역할
- 마이크로서비스는 분산 환경에서 운영되어 다수의 마이크로서비스가 동작
- 이러한 특징으로 인해 장애,운영 이관 등의 실행중인 프로세스에서 발생하는 이벤트의 흐름을 보고 원인을 파악하는데 오랜 시간 소모
서비스별로 발생하는 이슈들을 Tracing 하기 위하여 Monitoring,Logging,Tracer 도구를 활용하여 지속적이고 자동으로 이슈에 대응할 수 있도록 환경을 구성
2. Telemetry 주요 기능
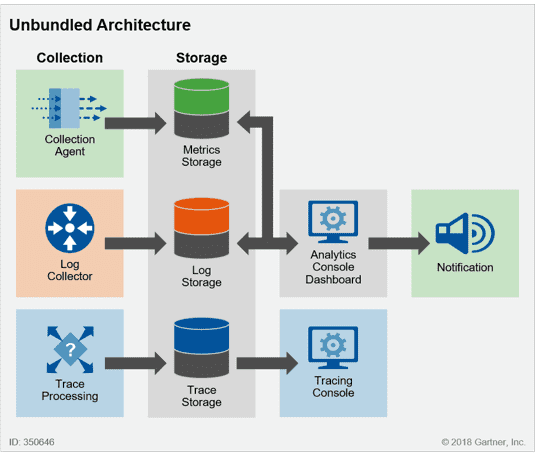
(1) Monitoring
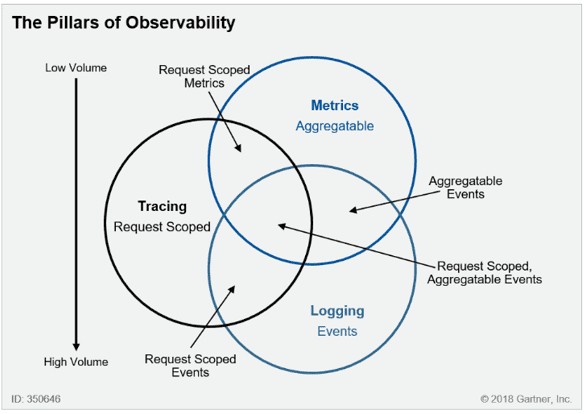
- 인프라 및 응용 프로그램 서비스 모니터링을 위해서는 매트릭 수집, 로깅 및 추적 이라는 세가지 도메인에서 데이터 수집, 저장 및 분석이 필요
-> Alert 기능은 세가지 도메인의 기능을 서포팅 하기 위해 반드시 필요한 성능 - Monitoring은 MSA의 성능이나 효율성을 확인
-> AWS에는 Amazon Cloudwatch가 있고 OSS로는 Prometheus 등이 있음 - Monitoring은 각 대상에서 수집한 Metric을 통해 대상 리소스의 사용률 등을 수치로 표현하는 기능을 수행
(2) Logging
- Logging은 MSA에서 발생하는 Log들을 수집해서 보여줌
- Log는 실행 중인 프로세스에서 발생하는 이벤트의 흐름을 의미하며 MSA에서는 컨테이너에서 실행중인 프로세스들의 수가 모놀리식 아키텍처에 비해 매우 많기에 장애와 같은 이벤트 발생 시 파악하기 힘들며 root cause를 찾기 어려움
(2)-1 Logging Pattern - 중앙 집중형 로깅
- 스크립트로 중앙 서버로 모든 로그를 복사하여 관리하는 로깅 방식으로 로그의 저장과 처리를 서비스 실행 환경에서 분리한 패턴
-> 각 서비스에서 발생한 로그들은 한 곳에 모아진 후 중앙의 데이터 저장소로 보내지고, 로깅 도구를 이용해 로그를 분석하고 처리
(2)-2 Logging 고려사항
- 저장소
마이크로 서비스에서 로그를 저장소에 저장할 경우 쌓여진 로그가 디스크를 가득 채우기에 어플리케이션 설계시 로그에 대하여 재활용 기법 사용해야함.
어플리케이션 내부에 로그를 저장할 경우 컨테이너가 종료되거나 재시작될 경우 사라질 수 있음 -> 로그를 어플리케이션 서버 외부 저장소에 저장해야함
- 약결합
모놀리식 아키텍처와 달리 MSA에서 가상머신과 컨테이너는 어플리케이션과 강한 결합을 안 맺음
배포에 사용되는 컨테이너는 배포 시마다 달라지며 짧은 수명을 가짐.
그래서 디스크의 저장 상태에 의존말고 별도의 도깅 도구를 활용하여 외부에 로그를 축적 및 관리 필수
- 보안
로그 스트림의 경우 개인 정보를 포함할 수 있기에 로그 파일이 ACL을 통하여 로그 관리자만 로그를 확인할 수 있도록 권한을 제어
로그 암복호화를 통하여 로그 자체를 보호하는 방법도 있으나 대량의 로그 바랭시 성능에 있어 영향을 초래
(3) Tracing
- Tracing은 MSA에서 발생한 Event를 발생 순서대로 나열해서 보여줌
- AWS에는 Amazon X-Ray가 있고, OSS(공개 소프트웨어)로는 Zipkin,Jaeger,Spring Cloud Sleuth가 존재
- 시간 순으로 요청을 보여주고 어떤 단계에서 성공 및 실패를 했는지 보여줘서 어떤 구간에서 이벤트가 발생했는지 파악 가능
3. Telemetry 유형별 도구 소개
1. Monitoring
(1) Stackdriver
- 각종 서비슬부터 측정된 성능 및 어플리케이션 메트릭을 취합 및 보관하고 통합 모니터링 콘솔과 정책 기반 알람을 제공
- AWS환경을 공식 지원하여 복수의 GCP 프로젝트와 AWS환경에 대한 통합 모니터링 환경 구성 가능
(2) AWS CloudWatch
- AWS CloudWatch는 AWS 클라우드 리소스 및 AWS에서 실행하는 어플리케이션을 모니터링 해주는 서비스
- CloudWatch를 사용하여 각 지표를 수집,추적하고 로그 파일을 수집하여 모니터링하며 Alert를 설정 가능
- CloudWatch를 이용해 AWS 환경 내 각종 리소스는 물론, 어플리케이션과 서비스에서 생성된 사용자 지정 지표와 어플리케이션에서 생성된 모든 로그파일을 모니터링 가능
(3) 프로메테우스(Prometheus)
- 프로메테우스는 각 서버에 클라이언트를 띄우고, 서버가 클라이언트를 주기적으로 접속해 데이터를 가져오는 Pull방식을 통해 매트릭을 수집
- 가져온 매트릭은 프로메테우스 자체 UI 혹은 Grafana등을 사용해 Visulalize 함
- 프로메테우스는 단순히 정보를 반복적으로 기록하는데 적합한 제품으로 고도의 다이나믹 서비스 지향 아키텍처 모니터링 뿐만 아니라 기계 중심 모니터링에도 적합2. Logging
(1) Stackdriver
- VM 인스턴스에서 발생된 로그는 Stackdriver 로깅 에이전트를 통해 Stackdriver로 전송
- AWS EC2인스턴스를 공식 지원하므로 GCP와 AWS에 대한 통합 로깅 환경의 구성 가능
(2) AWS ElasticSearch
- Amazon ElasticSearch(Amazon ES)는 로그 분석, 어플리케이션 모니터링을 위해 ElasticSearch를 손쉽게 배포,운영 및 확장해주는 완전 관리형 서비스
- ES는 오픈소스 ElasticSearch API,Kibana 관리 및 logstash와 기타 AWS Services와의 통합을 제공
- 사용자는 CloudWatch Logs 구독을 통해 빠르게 로그 항목을 Amazon ES로 스트리밍하도록 구성 가능, Kibana는 데이터를 시각화하여 검색할 수 있도록 함
(3) ELK, EFK
- EFK는 ElasticSearch(E),Fluentd(F),Kibana(K)로 이루어져 Logging의 목적으로 사용
- Fluentd가 배포된 호스트에서 로그를 필터링하고 모으는 aggregator 역할을 하고, ElasticSearch가 모인 로그를 저장하며 저장된 로그를 Kibana가 Visualize하는 역할을 수행
- Fluentd 대신 Logstach가 사용될 경우 ELK조합이 됨3. Tracing
(1) AWS X-Ray
- AWS X-Ray를 사용해 자신이 개발한 어플리케이션과 기본 서비스가 성능 문제와 오류의 근본 원인 식별 및 문제 해결을 올바르게 수행하는 지 파악 가능
- X-Ray는 요청에 대한 End-to-End 뷰를 제공하여 어플리케이션의 기본 구성 요소를 맵으로 보여줌
(2) Zipkin
- Zipkin은 마이크로서비스 기반 분산 시스템에서 Timing Data를 수집해 각각의 Latency를 분석해 문제해결을 할 수 있도록 해주는 분산 추적 시스템
- 어플리케이션이 Zipkin 서버로 Time Data를 전달하면 Zipkin UI는 각각의 어플리케이션의 Request Tracing Data,Dependency Diagram을 보여줌
- 만약 에러를 가질경우,Zipkin UI에서 어플리케이션 Trace의 Length,Annotation,Timestamp를 기준으로 Filtering하거나 Sort하는 기능 사용 가능
(3) Jaeger
- Jaeger는 Uber Technologies에서 오픈소스로 배포한 분산형 추적시스템으로 마이크로서비스 기반 분산 시스템 모니터링에 사용 가능
-> 마이크로서비스 기반 분산시스템(분산 컨텍스트 전파,분산 트랜잭션 모니터링,근본 원인 분석,서비스 의존성 분석,성능/대기 시간 최적화)
-Jaeger 백엔드는 단일 실패지점이 없고 비즈니스 요구사항에 맞게 확장 할 수 있도록 설계