1. Aggregation(데이터 집계)
특정 데이터를 특정 열의 값을 가진 데이터들로 묶는다.
집계 함수
| 함수명 | 설명 |
|---|---|
| count | Null이 아닌 레코드의 수 |
| sum | 필드명의 값들의 합계 |
| avg | 필드명의 값들의 평균 |
| min | 필드명의 값들 중 최소값 |
| max | 필드명의 값들의 최대값 |
1.1 aggregate()
쿼리셋에 대해 집계된 값을 딕셔너리로 반환한다. 필드 전체의 합이나 평균, 개수 등을 계산하는데 사용한다.
[ 예시 ]
>> a = object.aggregate(record_count = Count('record')) {'record_count' : 20 }
1.2 annotate()
필드를 새로 만들고, 그 안에 어떠한 내용을 채우게 하는 함수이다. 즉, 엑셀에서 컬럼 하나를 추가하는 것과 같다고 할 수 있다.
내용에는 다른 필듸의 값을 그대로 복사하거나 다른 필드의 값들을 조합(집계)한 값을 넣을 수 있다.
>> b = object.annotate(sum_total = Sum('record')) {'total_sum' : 12 }
1.3 aggregate()와 annotate()의 차이
- annotate() : 쿼리셋의 각 객체들에 적용
- aggregate() : 전체 쿼리셋에 대한 값을 계산
2. Join(데이터 참조)
2.1 select_related() : 정방향 참조
SQL 쿼리문에서 외래키(Foreign-key: 1:1, 1:n)를 사용해 정방향으로 데이터를 참조하는 함수이다. 쿼리가 복잡해지나 불러온 데이터들의 캐시(Cache)가 남아 매 쿼리마다 DB에 접근하지 않아도 된다. 즉, 자원 낭비를 예방할 수 있다.
>> book = Book.objects.select_related('title').get(id=1) <Book: Book object (1)>
2.2 prefetch_related() : 역방향 참조
select_related()와 반대로 1:n의 관계에서 1이 사용할 수 있으며, m:n 관계에서 사용할 수 있다. 마찬가지로 불러온 데이터들의 캐시가 남아있어 자원 낭비를 줄일 수 있다.
>> store = Store.objects.prefetch_related('book_title').get(id=1).book.values()
2.3 select_related()와 prefetch_related()의 차이
- select_related() : inner join을 통해 쿼리셋을 불러온다. 따라서 복잡하지만 적은 횟수로 쿼리를 실행한다.
- prefetch_related() : 모델별로 쿼리를 실행해 쿼리셋을 가져오기 때문에 1번 이상 쿼리가 실행된다.
둘 다 장점이 있고 단점이 있어서 적절히 사용하는 것이 좋다.
아직 완전히 사용법을 이해한 건 아니라서 다시 수정할 듯..
3. Order by(데이터 정렬)
3.1 order_by()
쿼리셋의 데이터를 정렬한다. asc()와 desc()로 오름차순, 내림차순 구현이 가능하다.
4. Search(데이터 조회)
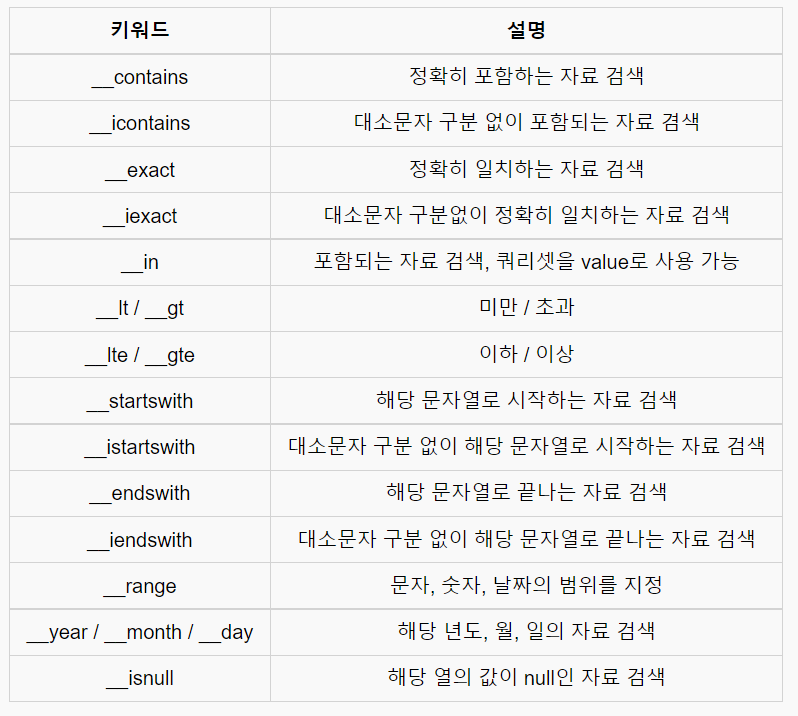
4.1 filter(필드명__키워드 = 조건)
filter 함수 내 조건에 해당하는 값을 전부 불러온다. 이때 django는 데이터에 식별을 위한 id를 자동으로 부여한다.
4.1.1 Q()
쿼리 자체를 객체로 다룰 수 있게 한 클래스로써, filter()나 get() 등 쿼리셋, 인스턴스를 반환하는 메서드 내의 옵션(쿼리 조건문)을 동일하게 받는다.
Q 객체는 연산자( | , &) 를 사용하여 and와 or 조건을 구분해 추가할 수 있으며, 이를 통해 원하는 형태의 조건 집합을 만들어 활용할 수 있다.
외래키를 통해 관계 테이블에서 조건을 거는 서브쿼리의 경우, '참조하고자 하는 테이블__필드명' 으로 조건을 걸 수 있다.
4.2 exclude()
주어진 조건에 맞지 않는 값을 조회한다.
4.3 get()
조건에 해당하는 하나의 객체를 반환한다. 속성을 불러옴으로써 원하는 값을 도출하는 것이 가능하고, 값이 없을 시 오류(DoesNotExist)를 띄운다.
[ 키워드 ]