
서론
외부 API를 사용할 때는 반드시 고려할 상황이 있습니다.
특정 API에 문제가 생겨, 오류가 발생하거나 응답이 지연되는 장애상황입니다.
크게 두가지 방법으로 해당 장애상황을 대처할 수 있습니다.
- Retry(재시도 요청)
- 서킷 브레이커
Retry는 서버의 일시적인 오류, 일시적인 네트워크 부하 등의 상황에서 사용합니다.
서킷 브레이커는 API 서버가 다운되어서 지속적으로 요청할 수 없을 때 사용합니다
서킷 브레이커는 운영환경의 장애 대응전략을 정리할 때 다룰 예정이며,
이번 글에서는 Retry내용을 중심으로 다루겠습니다
FCM API Retry 개발 과정
프로젝트에서 FCM 서버와 통신하기 위해 FCM API를 사용합니다.
구독 등록/삭제과정과 알림 메세지를 발송할 때, FCM API를 사용합니다
지난 3~4부에 걸쳐 해당 기능 개발을 완료했습니다.
정상적인 기능 동작과 응답시간 성능개선까지 이끌어냈습니다.
하지만 앞서 개발한 결과는 모두 정상적으로 동작했을 때의 결과입니다.
실제 운영을 목표로 하고 대량의 트래픽이 발생할 수 있기 때문에,
예외상황을 충분히 고려해야합니다
따라서 요청이 실패한다면 어떻게 대응할 수 있을지 고민했습니다.
네트워크 연결 재시도
과거 네트워크 과목을 학습했을 때가 떠올랐습니다.
네트워크 연결이 실패하면 네트워크 연결 재시도 요청을 합니다.
일시적인 네트워크 오류로 발생한 문제일 가능성도 존재하기 때문에,
네트워크 연결 과정에 네트워크 연결 재시도 같은 로직이 포함되어 있습니다.
지수 백오프
이때, 재시도 과정의 간격을 지수 백오프라는 전략으로 해결합니다
지수 백오프는 네트워크 상에서 일시적인 오류가 발생했을 때,
재시도 간격을 지수적으로 늘려가며 재시도 하는 알고리즘입니다.
지수 백오프가 필요한 이유
그렇다면 왜 지수 백오프 알고리즘을 재시도 간격으로 설정한 것일까요?
바로 동시에 많은 사용자들이 재시도 요청을 하면 서버 부하가 증가할 수 있기 때문입니다.
이를 대처하기 위해 지수 백오프 알고리즘이 필요합니다.
지수 백오프 알고리즘을 이용한다면?
앞서 네트워크 연결 재시도 요청과 지수 백오프 알고리즘에 대해 정리했습니다.
이 방법을 프로젝트에도 적용해서 외부 API에 재시도하는 방법으로 활용한다면,
외부 API 서버의 일시적인 오류에도 충분히 대처할 수 있을 것입니다!
FCM 공식문서에서도 언급한 지수 백오프 방법
FCM 공식문서에서도 서버가 과부하 되었거나 내부 오류가 발생했을 때,
추천하는 재시도 방법으로 지수 백오프 방법을 언급하고 있습니다

따라서 서버에서 특정 오류가 발생했을 때,
재시도 처리 방법으로 지수 백오프 알고리즘을 적용하기로 결정했습니다
Jitter 방법이란?
FCM 공식문서를 자세히 읽어보면 Jitter을 적용하는 것이 좋다고 언급합니다.
Jitter란 데이터 통신에서 사용하는 용어로
패킷 지연이 일정하지 않고, 수시로 변하고, 패킷 간의 간격이 일정하지 않는 현상입니다.
이 개념을 Retry와 지수 백오프 개념에 적용하면,
재시도 시간 간격에 무작위성을 추가해서 재시도 시간의 동시성을 분산시킬 수 있습니다
이해를 돕기 위해, AWS에서 작성한 글과 사진을 토대로 정리했습니다.
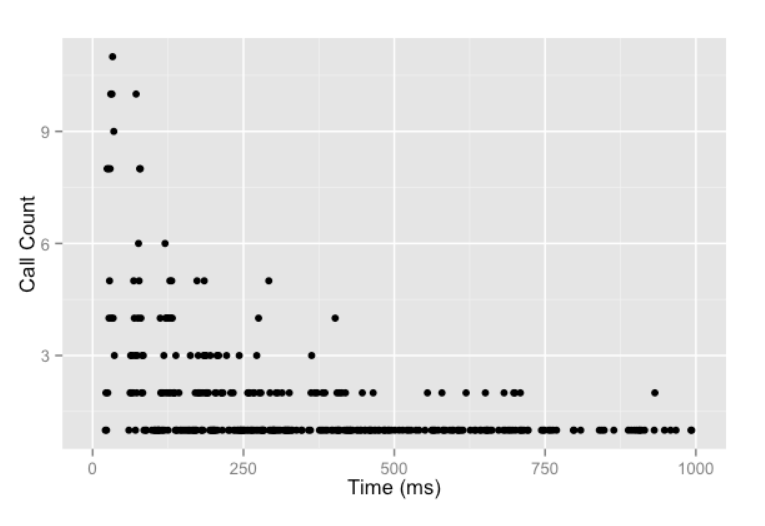
Jitter 적용 전
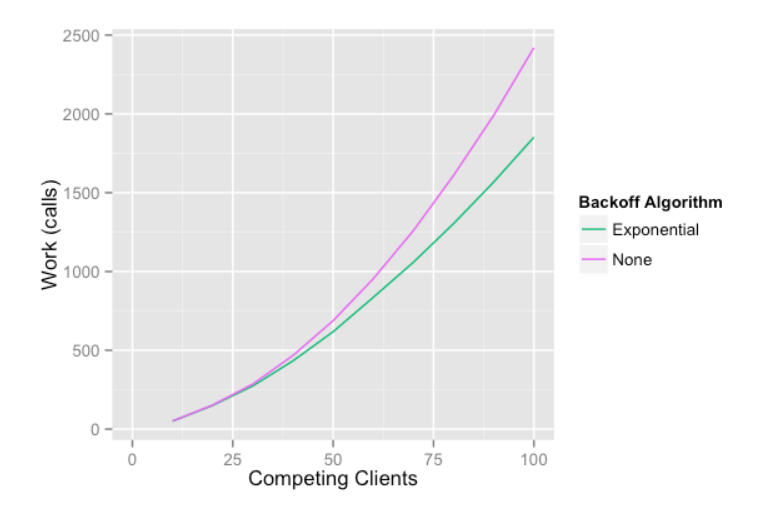
먼저 Jitter 적용 전의 모습입니다.
순차적인 간격으로 재시도 요청을 했을 때보다 동시성에서 이점을 갖지만
그래도 큰 성능 차이는 확인할 수 없습니다
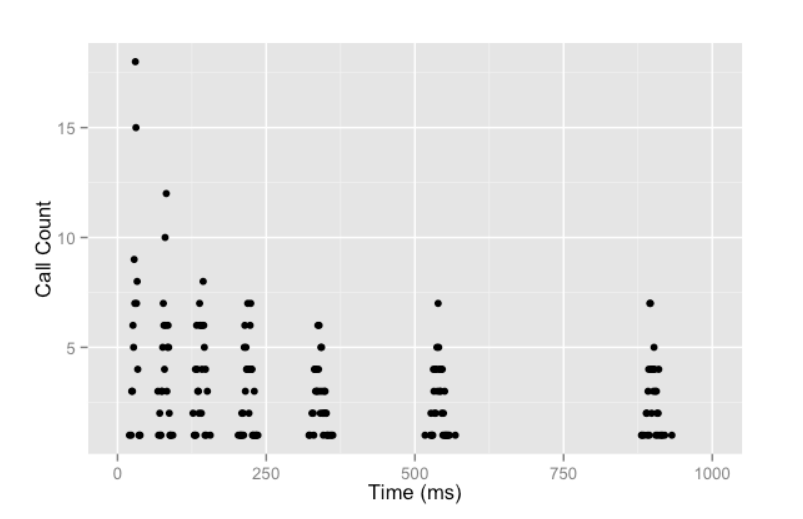
이유는 위 사진을 통해 알 수 있습니다.
1. 요청들간 경쟁에서 일부 사용자가 승리하고 작업을 진행합니다
2. 패배한 요청은 지수 백오프 간격으로 재시도 요청을 합니다.
3. 하지만 지수 백오프 간격이 일정하기 때문에, 다시 패배한 사용자 모두와 경쟁합니다
4. 이 과정이 반복됩니다.
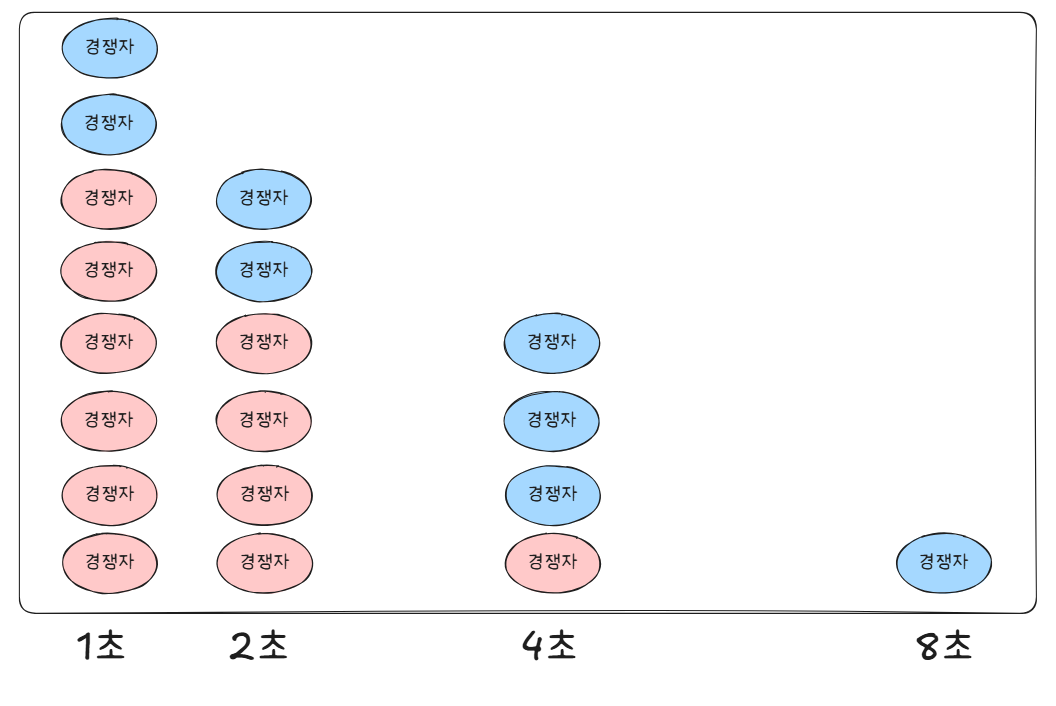
해당 과정을 위와 같이 정리했습니다.
즉 지수 백오프로 재시도 요청을 해도 이전에 자원을 선점하지 못한 경쟁자와
동일한 시간에 다시 경쟁하기 때문에, 성능상 큰 이점을 얻지 못하는 것입니다.
Jitter 적용 후
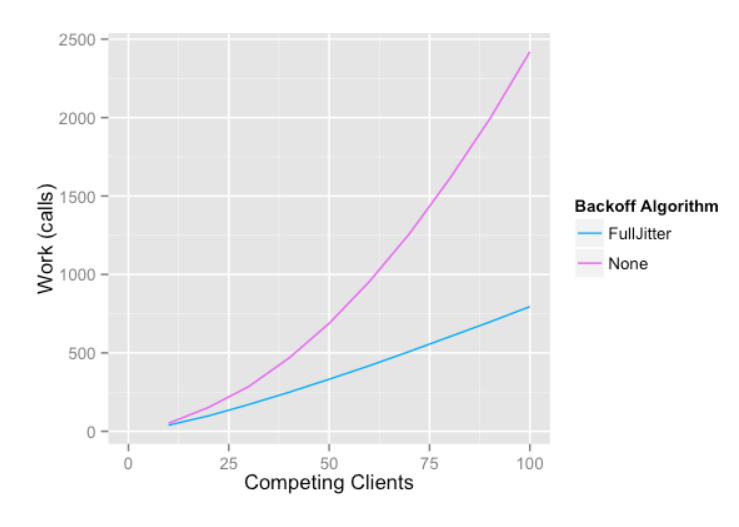
Jitter 적용 후의 모습입니다.
이전보다 경쟁자 수 대비, 처리율이 높은 것을 확인할 수 있습니다
이유는 위 사진을 통해 알 수 있습니다
지수 백오프 방식으로 재시도 요청을 하지만,
지정한 간격 내에서 요청별로 재시도 시점을 랜덤하게 적용합니다.
따라서 일정한 간격으로 재시도 요청을 하지 않고, 랜덤하게 재시도 요청을 하기 때문에
특정 시점에 재시도 요청이 몰리는 문제를 해결할 수 있습니다!
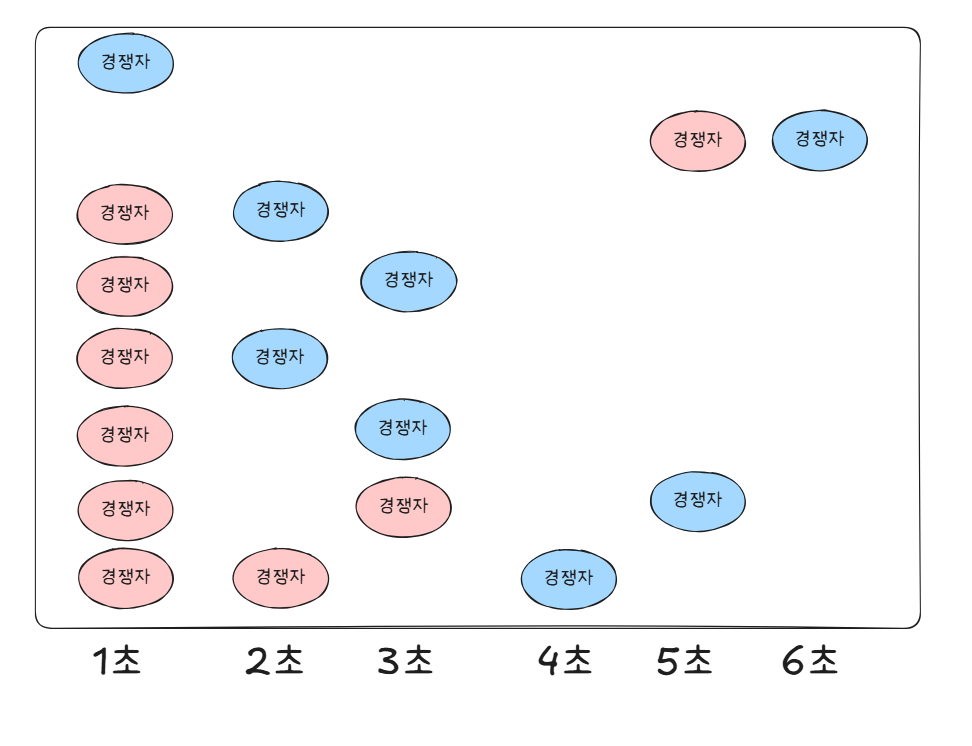
해당 과정을 위와 같이 정리했습니다.
이후 재시도 요청 시작 시점이 달라 시간별로 경쟁자 수가 적기 때문에
적은 시간동안 많은 사용자의 재시도 요청을 처리할 수 있습니다!
Spring boot에서 Retry 방법
Spring boot에서는 Jitter가 적용된 지수 백오프 Retry를
손쉽게 사용할 수 있도록 @Retryable 기능을 제공합니다.
@Retryable 사용 준비
먼저 해당 기능을 사용하기 위해 gradle에 다음 의존성을 추가해야합니다
implementation 'org.springframework.retry:spring-retry:2.0.11'이어서 main클래스에 @EnableRetry 애노테이션을 추가합니다
@EnableRetry
@EnableJpaAuditing
@SpringBootApplication
public class CheckingApplication {
public static void main(String[] args) {
SpringApplication.run(CheckingApplication.class, args);
}
}이제 @Retryable을 사용할 준비가 되었습니다!
@Retryable 설정
이제 재시도 요청을 하고 싶은 메소드에 @Retryable을 적용하면 됩니다!
@Retryable(
retryFor = {CustomFirebaseMessagingException.class},
exceptionExpression = "errorCode == ErrorCode.UNAVAILABLE || errorCode == ErrorCode.INTERNAL",
maxAttempts = 5,
backoff = @Backoff(
random = true,
delay = 10000,
multiplier = 3,
maxDelay = 600000
)
)
public String fcmSend(Message message) throws FirebaseMessagingException {
try{
return fcm.send(message);
}catch (FirebaseMessagingException e) {
log.error("예외 발생: {}", e.getErrorCode());
throw new CustomFirebaseMessagingException(e);
}
}저는 위와같이 FCM 서버로 알림 메세지를 전송하는 로직에
@Retryable을 적용했습니다
retryFor
해당 속성은 Retry가 발생할 조건을 의미합니다.
해당 코드에서는 CustomFirebaseMessagingException.class 예외가 발생할 경우
Retry 하도록 설정했습니다
exceptionExpression
발생한 예외 오류코드 중에서 일부 오류가 발생했을 때만
Retry 요청을 하고 싶습니다.
이때 해당 속성을 조건식과 같이 사용해서 원하는 오류가 발생했을 때만
Retry 요청을 할 수 있습니다.
FCM 공식 문서에서 500번 오류코드에 대해서만 Retry하도록 권장하고 있습니다.
따라서 다음 두가지 오류 코드만 Retry 하도록 설정했습니다
- UNAVAILBALE(503)
- INTERNAL(500)
maxAttempts
최대 Retry 횟수입니다.
default는 3회지만, 프로젝트의 목표는 최대한 요청을 성공하는 것이기 때문에
5회로 설정했습니다
backoff
앞서 정리한 지수 백오프와 Jitter 적용 여부를 결정할 수 있습니다
random
jitter 적용 여부를 결정할 수 있습니다. true로 설정해서 적용했습니다
delay
재시도 요청 간격입니다.
FCM 공식문서에서 전송 요청 시간 제한을 10초 이상으로 권장했기 때문에
10초로 설정했습니다
multiplier
재시도 요청 간격입니다. 최대 delay가 크기 때문에 3배씩 증가하도록 설정했습니다
maxDelay
최대 요청 간격입니다. 재시도 요청한지 10분이 지났는데도, 똑같은 예외가 발생하면
복구 불가능한 문제로 판단해서 더이상 재시도 요청을 하지 않도록 설정했습니다
FirebaseMessagingException 트러블 슈팅
ErrorCode 접근제한
처음 Retry 발생 조건으로 설정한 예외는 FirebaseMessagingException입니다.
하지만 해당 예외의 경우 ErrorCode를 확인할 수 없습니다.
라이브러리 내부를 확인한 결과 private로 되어있기 때문에 확인할 수 없습니다.
CustomFirebaseMessagingException 개발
이 문제를 해결하기 위해 CustomFirebaseMessagingException 클래스를 개발했습니다
@Getter
@Slf4j
public class CustomFirebaseMessagingException extends RuntimeException{
public final ErrorCode errorCode;
public CustomFirebaseMessagingException(FirebaseMessagingException e) {
this.errorCode = e.getErrorCode();
log.error("설정 에러코드: {}", errorCode);
}
public CustomFirebaseMessagingException(ErrorCode errorCode) {
this.errorCode = errorCode;
}
}ErrorCode를 public 필드로 선언하며, 생성자로 FirebaseMessagingException 예외를 받아
public ErrorCode 필드로 초기화했습니다.
이제 exceptionExpression에서 접근제한없이 ErrorCode를 확인할 수 있습니다!
테스트 진행
이어서 지정한 예외가 발생했을 때,
Retry요청이 정상적으로 동작하는지 테스트를 진행했습니다
정상적인 방법으로는 시도할 수 없기 때문에, Mock을 이용해서 테스트를 진행했습니다
UNAVIALBE 예외 발생 시, 5번 재시도하는가?
@Test
public void testFcmSendUnavailableErrorCode() throws FirebaseException {
CustomFirebaseMessagingException exception = new CustomFirebaseMessagingException(
ErrorCode.UNAVAILABLE
);
Message message = Message.builder().setTopic("test").build();
Mockito.when(fcm.send(any(Message.class)))
.thenThrow(exception);
String result = "";
try{
result = fcmService.fcmSend(message);
} catch (CustomFirebaseMessagingException e){
result = e.getErrorCode().toString();
log.error("예외 발생: {}", e.getErrorCode());
}
verify(fcm, times(5)).send(any(Message.class));
assertEquals("UNAVAILABLE", result);
}테스트 결과

테스트 결과 정상적으로 동작합니다!
5번의 재시도 요청 중, 정상응답이 포함되면 재시도하지 않는가?
@Test
public void testFcmSendWithRetry() throws FirebaseException {
CustomFirebaseMessagingException exception = new CustomFirebaseMessagingException(
ErrorCode.UNAVAILABLE
);
Message message = Message.builder().setTopic("test").build();
Mockito.when(fcm.send(message))
.thenThrow(exception)
.thenReturn("Success");
String result;
try{
result = fcmService.fcmSend(message);
} catch (CustomFirebaseMessagingException e){
result = e.getErrorCode().toString();
}
verify(fcm, times(2)).send(message);
assertEquals("Success", result);
}테스트 결과

두번째 요청에서는 정상적으로 응답하며, 이어서 재시도 요청도 하지 않는 것을 확인했습니다
INTERNAL 예외 발생 시, 5번 재시도 요청을 하는가?
@Test
public void testFcmSendWithRetryExceptionForInternal() throws FirebaseException {
CustomFirebaseMessagingException exception = new CustomFirebaseMessagingException(
ErrorCode.INTERNAL
);
Message message = Message.builder().setTopic("test").build();
Mockito.when(fcm.send(message))
.thenThrow(exception);
String result;
try{
result = fcmService.fcmSend(message);
} catch (CustomFirebaseMessagingException e){
result = e.getErrorCode().toString();
}
verify(fcm, times(5)).send(message);
assertEquals("INTERNAL", result);
}테스트 결과

정상적으로 5번 재시도하는 것을 확인했습니다
앞선 두 예외가 아닐 때, 재시도 요청을 하지 않는가?
@Test
public void testFcmSendWithRetryExceptionForUnknown() throws FirebaseException {
CustomFirebaseMessagingException exception = new CustomFirebaseMessagingException(
ErrorCode.UNKNOWN
);
Message message = Message.builder().setTopic("test").build();
Mockito.when(fcm.send(message))
.thenThrow(exception);
String result;
try{
result = fcmService.fcmSend(message);
} catch (CustomFirebaseMessagingException e){
result = e.getErrorCode().toString();
}
assertEquals("UNKNOWN", result);
verify(fcm, times(1)).send(message);
}테스트 결과
테스트 결과 재시도 요청없이 단순 예외처리하는 것을 확인했습니다
종합
테스트 결과 지정한 예외 발생 시, 정상적으로 Retry 요청을 확인하는 것을 확인했습니다
이제 Jitter가 적용된 지수 백오프 방식으로 외부 API에 Retry를 할 수 있습니다.
Retry를 통해 사용자와의 상호작용에서 발생할 수 있는 오류에 대처할 수 있습니다!
스레드 점유 관련 고민
Retry 방법을 사용하며 한가지 문제를 고민했습니다.
다음 Retry까지 대기하는동안 스레드를 점유하는것인지 궁금했습니다..
만약 대기하는 동안에도 요청받은 스레드를 점유하고 있다면,
트래픽이 발생했을 때 서버에 부하를 줄 수 있습니다.
스레드 점유 여부 확인
/*
* Copyright 2014 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.retry.backoff;
/**
* Simple {@link Sleeper} implementation that just blocks the current Thread with sleep
* period.
*
* @author Artem Bilan
* @since 1.1
*/
@SuppressWarnings("serial")
public class ThreadWaitSleeper implements Sleeper {
@Override
public void sleep(long backOffPeriod) throws InterruptedException {
Thread.sleep(backOffPeriod);
}
}@Retryable의 대기 시 Thread.sleep()을 사용합니다.
따라서 스레드를 점유합니다.
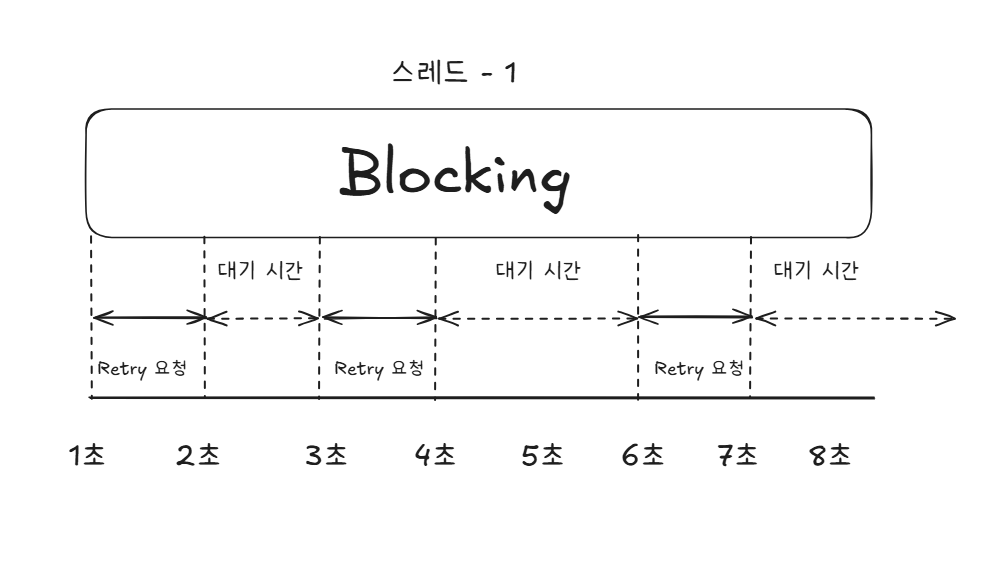
메인 스레드를 점유하기 때문에 요청의 응답도 길어질 수 있습니다.
구독 과정에서 Retry의 문제점
구독 과정은 이미 별도의 비동기 스레드를 이용하고 있습니다.
이렇게 설정한 이유는 사용자에게 빠르게 응답해서
즐겨찾기 추가/삭제 과정의 지연시간을 최소화하기 위함입니다.
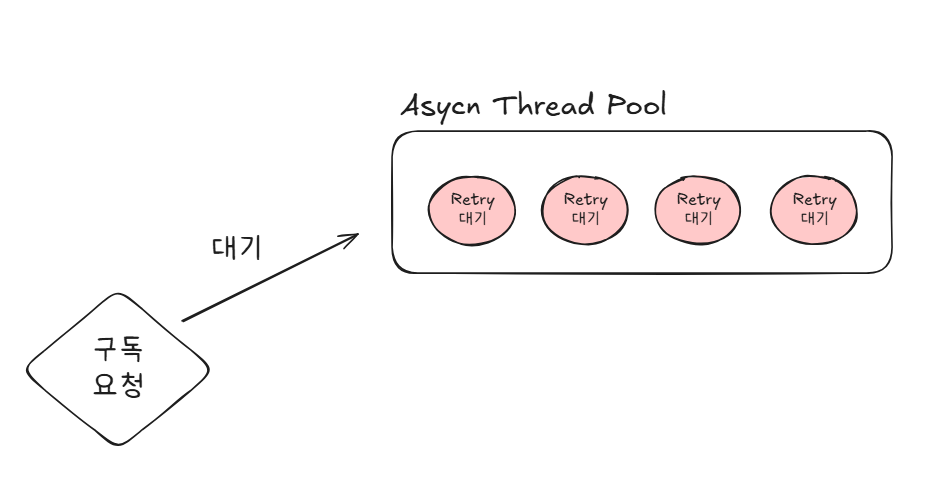
Retry때문에 각 비동기 스레드를 점유하고 있는 시간이 길어지면,
구독과정을 처리할 비동기 스레드가 부족해, 대기하는 시간이 증가할 것입니다.
이런 모습은 응답시간을 빠르게 하고, 구독과정의 트래픽을 유연하게 처리해서
서버 부하를 줄이기 위한 목적과 부합하지 않습니다
따라서 구독과정에서 Retry 로직을 적용하는 것은 제외하기로 결정했습니다.
알림 발송과정에서 Retry 적용
하지만 알림 발송 과정은 트래픽을 걱정할 필요가 없습니다.
다수의 사용자 요청이 아닌 서버 혼자서 FCM 서버에 요청하기 떄문입니다.
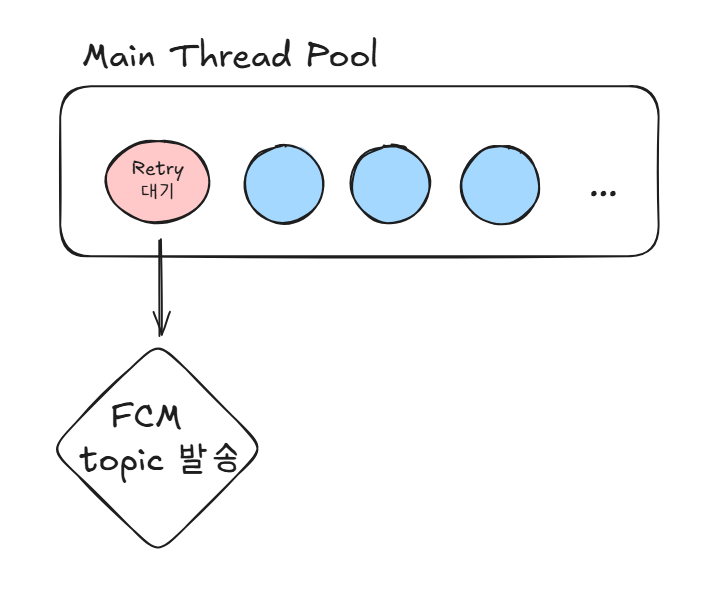
비록 동기 블로킹으로 동작해서 스레드를 하나 점유하겠지만,
이 리스크가 FCM 알림 발송을 실패했을 때의 리스크보다는 크지 않다고 판단해서
알림 발송 과정에서 Retry 적용은 유지하기로 결정했습니다.
Scheduler와 misfire
앞선 주제에서 외부 API와 통신하는 과정의 오류대처 방법을 정리했습니다.
이번에는 Scheduler에서 오류가 발생할 때, 어떻게 대처할 것인지를 정리했습니다
misfire이란?
Scheduler의 Job이 정해진 Trigger 시간에 동작하지 않는 경우 misfire(불발)되었다고 합니다.
misfireThreshold 설정
misfire를 판단하는 기준이 있어야합니다.
이 기준을 설정하는 방법이 바로 misfireThreshold값입니다.
일반적으로 5초 이내로 설정하나,
동일한 시간에 작업할 요청이 많아 스케줄링 작업이 지연될 가능성이 있기 때문에
10초로 설정했습니다
quartz:
job-store-type: memory
properties:
org:
quartz:
threadPool:
threadCount: 5
jobStore:
misfireThreshold: 10000설정한 시간 이내로 불발작업이 다시 실행되지 않을 경우,
misfire 정책에 따라 Quartz Scheduler에서 대처합니다.
Quartz에서 제공하는 misfire 정책
Quartz 스케줄러에서는 이런 상황을 쉽게 대처할 수 있도록
misfire 정책기능을 제공합니다
Scheduler 타입에 따라 다음과 같은 misfire 정책을 제공합니다
CronSchedule
- withMisfireHandlingInstructionIgnoreMisfires (불발 무시)
- withMisfireHandlingInstructionDoNothing (아무것도 하지 않음)
- withMisfireHandlingInstructionFireAndProceed (실행과 진행)
해당 정책 이해를 돕기 위해 직접 출력 테스트를 진행했습니다
테스트 코드는 아래 코드와 같습니다.
@Test
void testCronSchedulerMisfireTest() throws SchedulerException, InterruptedException {
String cronExpression = "0/1 * * * * ?";
JobDetail jobDetail = JobBuilder.newJob(testExecute.class)
.withIdentity("eventNotification", "dailyEventNotification")
.storeDurably()
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.forJob(jobDetail)
.withIdentity("testTrigger", "testGroup")
.withSchedule(CronScheduleBuilder.cronSchedule(cronExpression)
.withMisfireHandlingInstructionDoNothing())
.build();
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
scheduler.pauseJob(jobDetail.getKey());
Thread.sleep(3000);
scheduler.resumeAll();
Thread.sleep(3000);
}Cron 표현식을 사용해서 1초마다 count값을 증가시켜 출력하는 테스트입니다.
withMisfireHandlingInstructionIgnoreMisfires 테스트

위 테스트 결과, 작업이 정지된 이후 불발이 반복되지만
이 불발들을 기억해서 작업을 재개할 때, 한번에 실행 하는 것을 확인할 수 있습니다
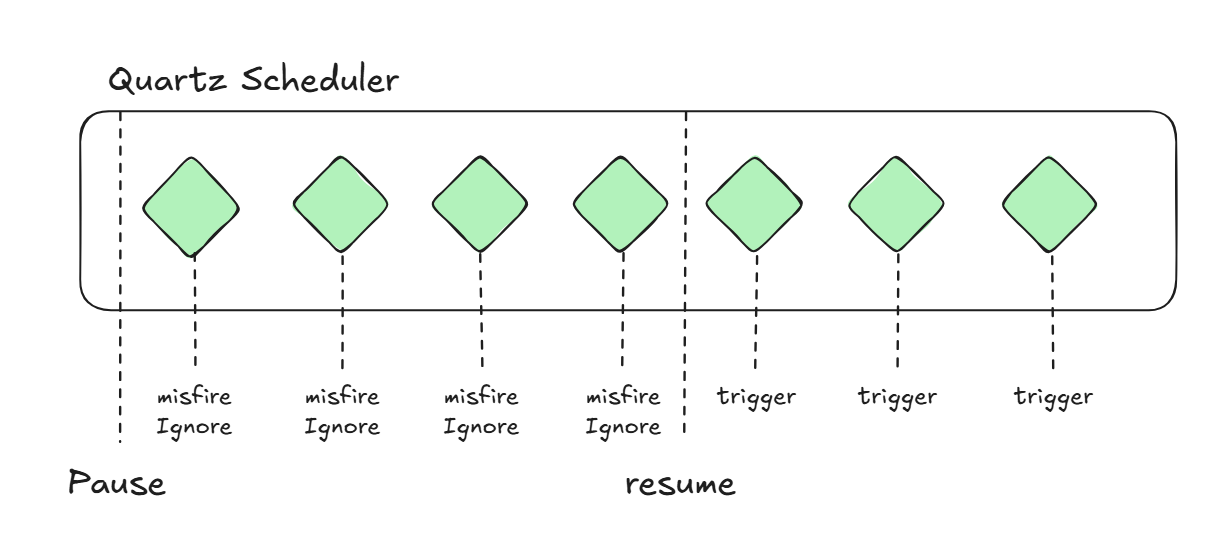
그림으로 정리하면 위와 같습니다.
실제로는 불발되지 않고 실행되었으며,
resume때 한번에 결과가 출력된 이유는 Thread를 정지해서 출력작업이 늦었기 때문입니다.
withMisfireHandlingInstructionDoNothing 테스트

위 테스트 결과를 확인하면 정지된 동안 아무것도 작업하지 않습니다.
불발되면 아무런 작업도 하지 않고, 작업이 시작되고 나서 다시 트리거가 발생합니다.
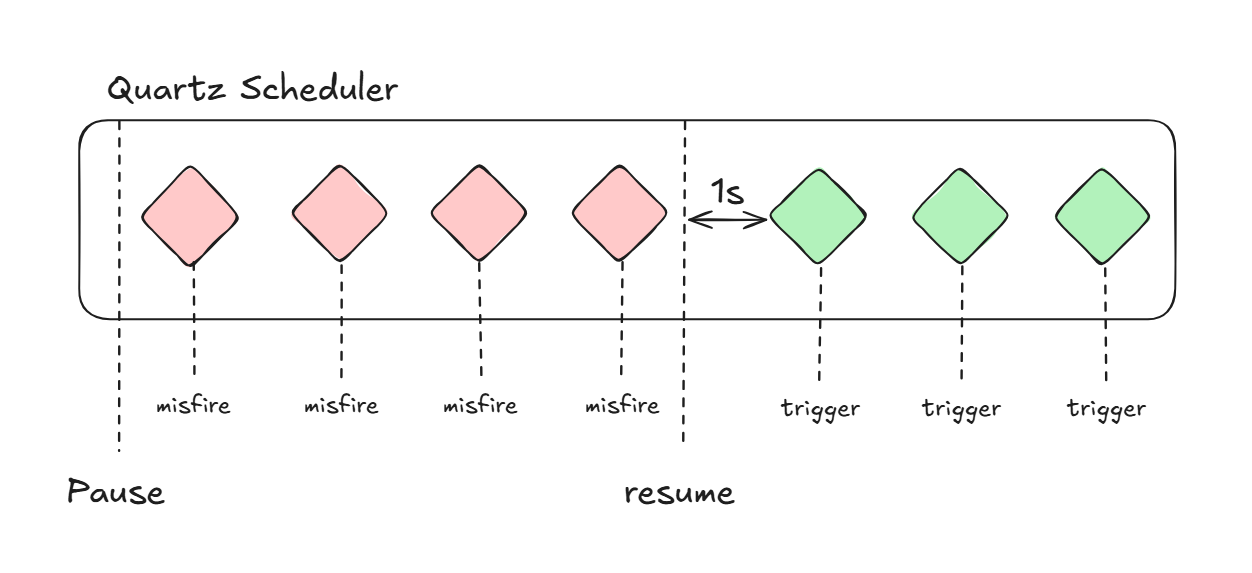
그림으로 정리하면 위와 같습니다.
Resume를 기준으로 다시 1초 트리거가 시작되어서 작업을 진행합니다.
withMisfireHandlingInstructionFireAndProceed 테스트

위 테스트 결과를 확인하면,
작업이 정지된 동안에 아무런 결과도 갱신되지 않는 것을 확인할 수 있습니다.
마치 withMisfireHandlingInstructionDoNothing작업과 동일하게 동작하는 것처럼 보입니다
하지만 자세히 살펴보면 결과가 다른 것을 확인할 수 있습니다.
해당 정책은 불발된 경우, 다시 현재시간을 기준으로 Cron Trigger를 실행합니다
테스트코드에서는 작업이 정지동안 불발이 발생할 때마다, 1초 단위로 Trigger가 동작합니다.
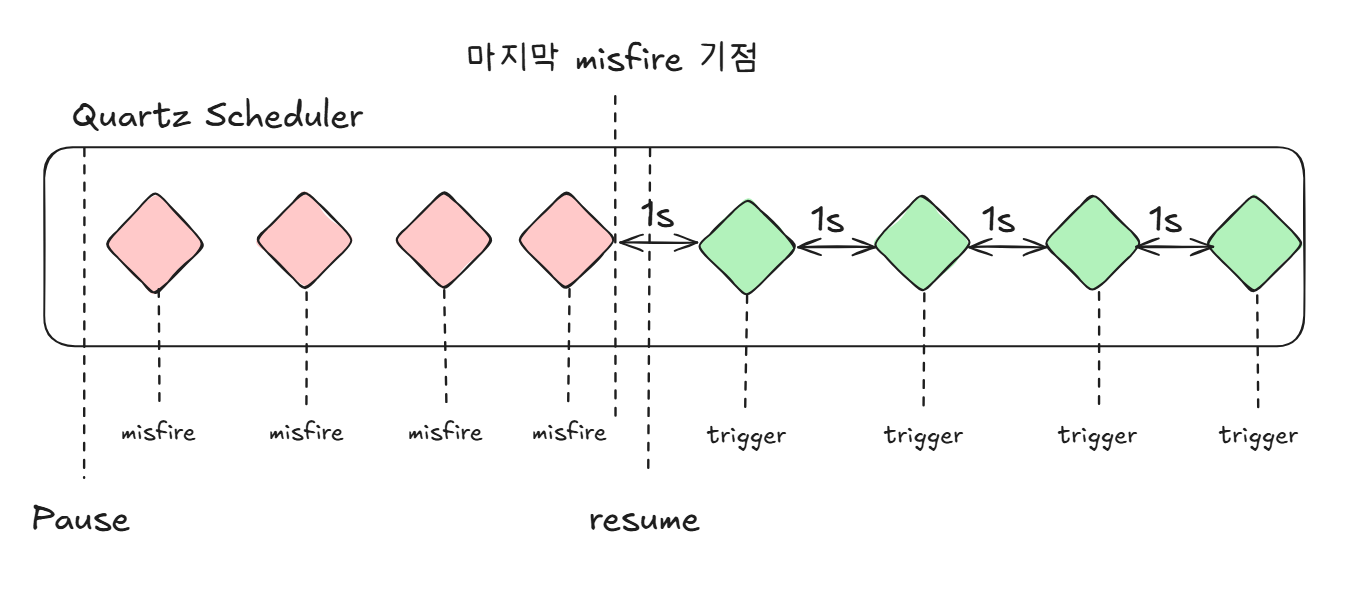
그림으로 정리하면 위와 같습니다.
매 misfire마다 현재 시간을 기준으로 재실행합니다.
그리고 resume가 아닌 마지막 misfire를 기점으로 1초 뒤에 trigger가 발생했기 때문에,
앞선 정책과는 다르게 4라는 결과를 추가로 얻은 것입니다
SimpleSchedule
- withMisfireHandlingInstructionIgnoreMisfires (불발 무시)
- withMisfireHandlingInstructionFireNow (즉시 실행)
- withMisfireHandlingInstructionNextWithExistingCount (횟수 유지, 다음 작업으로 실행)
- withMisfireHandlingInstructionNextWithRemainingCount (횟수 감소, 다음 작업으로 실행)
- withMisfireHandlingInstructionNowWithExistingCount (횟수 유지, 즉시 실행)
- withMisfireHandlingInstructionNowWithRemainingCount (횟수 감소, 즉시 실행)
다음 두 정책은 CronTrigger와 동일하게 동작합니다.
- withMisfireHandlingInstructionIgnoreMisfires
- withMisfireHandlingInstructionFireNow
이어지는 4가지 정책은 횟수와 실행시점을 기준으로 구분할 수 있습니다.
주로 해당 정책은 반복되는 작업에서 사용되는데,
현재 프로젝트에서는 다루지 않기 때문에 기준에 대해서만 간단하게 정리 했습니다
횟수
특정 작업에 대해 반복하는 Trigger가 있을 때, 그 반복 횟수를 의미합니다.
반복횟수가 0이 되면 더이상 Trigger가 동작하지 않습니다
실행 시점
즉시 재실행은 말그대로 바로 실행하는 것을 의미합니다
다음 일정의 경우, Calender를 기준으로 다음 일정이 되었을 때, 작업을 실행합니다.
프로젝트 misfire 발생 지점 정리
프로젝트에서 다음 두가지 경우에 대해 스케줄링 작업을 진행합니다.
- 0시 30분에 진행하는 스케줄링 작업
- 이벤트 시작시간 웹 푸시 알림 스케줄링 작업
모든 작업은 misfire가 발생할 경우 즉시 재실행되어야 합니다
따라서 모든 스케줄링 작업에 대해 즉시 재실행 misfire 정책을 설정했습니다
0시 30분에 진행하는 스케줄링 작업
해당 스케줄링 작업은 cronSchedule 방식입니다.
따라서 withMisfireHandlingInstructionFireAndProceed정책을 적용했습니다
@Bean
public Trigger eventScheduleTrigger() {
return TriggerBuilder.newTrigger()
.forJob(eventScheduleJob())
.withIdentity("eventNotificationTrigger", "dailyEventNotificationTrigger")
.withSchedule(CronScheduleBuilder.dailyAtHourAndMinute(0, 30)
.withMisfireHandlingInstructionFireAndProceed())
.startNow()
.build();
}이벤트 시작시간 웹 푸시 알림 스케줄링 작업
해당 스케줄링 작업은 CronSchedule도 아니고 SimpleSchedule도 아닙니다.
misfire 정책을 사용하기 위해서는 두 방법 중 한가지를 선택해야합니다
Trigger triggerStartEvent = TriggerBuilder.newTrigger()
.forJob(jobDetailStartEvent)
.withIdentity("Trigger_" + NotificationSchedule + "_StartEvent")
.startAt(Date.from(startTime
.atZone(ZoneId.systemDefault())
.toInstant()))
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withMisfireHandlingInstructionFireNow()
)
.build();해당 작업 특성 상, 이벤트 시작 시간을 기준으로 동작하는 작업이라
Cron 표현식을 사용하지 않기 때문에 SimpleScheudle로 설정한 뒤,
withMisfireHandlingInstructionFireNow 정책을 추가했습니다.
정리
이제 스케줄링 작업이 실패했을 때도,
즉시 재실행하도록 설정해서 오류에 대처할 수 있습니다!
마무리
웹 푸시알림과 관련된 정리가 끝났습니다.
외부 API 연결과 Scheduling 작업에 대해 깊이있게 학습한 좋은 시간이었습니다.
해당 주제에 대해 더 깊게 학습하고 싶은 부분이 있었으나,
웹 푸시알림의 주제와 벗어난다고 생각해서 관련 학습은 이후 따로 정리할 계획입니다.
이메일 서비스 이야기보다 더 길었던 웹 푸시알림 이야기를 읽어주셔서 감사합니다.
참고
