개요
LZ77 알고리즘은 대표적인 무손실 압축 알고리즘으로, ZIP, GZIP, PNG등
현대 압축기술에서 자주 사용되는 알고리즘 입니다
LZ77 알고리즘은 사전기반 부호화 방식으로 자료구조가 담고 있는 문자열과 압축된 텍스트사이에서 일치하는 항목을 찾아 동작하는 무손실 압축 알고리즘입니다
특징
- 슬라이딩 윈도우 방식을 사용합니다
- 무손실 압축 알고리즘입니다
동작방식
슬라이딩 윈도우 방식을 사용하는데, 이때 두가지 버퍼로 나눠집니다
- 검색버퍼(Search Buffer): 이미 지나온 데이터 과거의 데이터가 저장된 버퍼입니다
- 룩어헤드 버퍼(Look-Ahead Buffer): 앞으로 압축해야할 미래의 데이터가 저장된 버퍼입니다
압축과정은 룩어헤드 버퍼의 앞부분이 검색 버퍼에 있는지 확인하고,
존재하면 다음과 같은 형태의 토큰으로 변환합니다
토큰의 구조
토큰의 구조는 다음과 같이 (D, L ,C) 형태로 구성됩니다
- D(Distance/Offset): 현재 위치에서 얼마나 과거로 가야하는지
- L(Length): D에서 몇 글자를 복사해야 하는지?
- C(Next Character): 복사가 끝난 후 오는 다음 문자는 무엇인지
여기서 C는 매칭되는 문자열이 없을 때, 새로운 문자를 등록하거나 매칭 후의
흐름을 이어가기 위해 필요합니다
단계별 설명
1. 슬라이딩 윈도우 세팅
먼저 앞서 정리한 검색버퍼와 룩어헤드 버퍼를 세팅합니다
처음에는 검색버퍼가 비어있고, 룩어헤드 버퍼에 압축할 데이터로 가득차 있습니다
2. 첫 데이터 처리
압축을 시작하면서 룩어헤드 버퍼의 제일 앞 데이터를 검색 버퍼에서 찾습니다
맨 처음 데이터는 검색 버퍼가 반드시 비어있기 때문에 찾을 수 없습니다
이렇게 매칭되는 데이터가 없으면 (0, 0, 'A')와 같은 형태의 토큰을 생성합니다
토큰을 정리하면 다음과 같습니다
- D: 0 (찾지 못함)
- L: 0 (일치하는 길이 없음)
- C: 'A' (그대로 출력)
토큰을 생성 한 후에 윈도우가 한 칸 오른쪽으로 이동하고 'A'는 검색 버퍼로 들어갑니다
3. 중복 패턴 탐색 및 압축
윈도우가 계속 이동하다보면 검색 버퍼에 데이터가 쌓이게됩니다
이번에는 검색 버퍼에 있는 경우를 확인해보겠습니다
룩어헤드 버퍼의 시작이 A B인 경우, 검색 버퍼의 A B와 일치하다는 것을 발견하고
(3, 2, 'A')라는 토큰을 생성합니다
- D: 3(현재 위치에서 3칸 뒤로 가면 찾을 수 있음)
- L: 2 (A, B 두 글자가 일치)
- C: 'A' (일치하는 부분 다음에 오는 새로운 문자)
이렇게 데이터를 좌표로 대체하면서 데이터의 양을 줄일 수 이씁니다
4. 최종 결과
이러한 과정을 반복하면 원본 데이터가 토큰들로 변환됩니다
위와같이 (ABCABACD)가 압축되어 토큰 형태로 변환된 것을 확인할 수 있습니다
LZ77 알고리즘은 반복되는 패턴이 많을 수록, 그리고 패턴의 길이가 길수록
압축 효율이 높아집니다
Java로 구현
이번에는 Java 코드로 LZ77 알고리즘을 구현해보겠습니다
Token 구현
package org.utils.token;
public class Lz77Token {
private int distance;
private int length;
private char nextChar;
public Lz77Token(int distance, int length, char nextChar) {
this.distance = distance;
this.length = length;
this.nextChar = nextChar;
}
public int getDistance() {
return distance;
}
public void setDistance(int distance) {
this.distance = distance;
}
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
public char getNextChar() {
return nextChar;
}
public void setNextChar(char nextChar) {
this.nextChar = nextChar;
}
@Override
public String toString() {
return "Lz77Token{" +
"distance=" + distance +
", length=" + length +
", nextChar=" + nextChar +
'}';
}
}먼저 (D, L, C) 정보를 보관할 토큰 클래스를 하나 만들었습니다
압축 로직 메소드 구현
private static final int cursorValue = 0; // 슬라이딩 윈도우 커서 시작 위치
private static final int windowSizeValue = 20; // 검색 버퍼 크기
public static List<Lz77Token> compress(String input) {
List<Lz77Token> compress = new ArrayList<>();
int cursor = cursorValue;
while(cursor < input.length()){
int bestDistance = 0;
int bestLength = 0;
// 검색 버퍼 범위 설정(현재 커서 위치에서 뒤로 windowSize 만큼 이동)
int searchBufferStart = Math.max(0, cursor - windowSizeValue);
// 현재 커서 위치의 문자열과 일치하는 가장 긴 문자열을 검색 버퍼에서 찾는다
// 룩어헤드 버퍼의 길이만큼 반복한다
for (int i = searchBufferStart; i < cursor; i++) {
int len = 0;
// 범위 내에서 문자가 일치하는 동안 길이 증가
while (cursor + len < input.length()
&& input.charAt(i + len) == input.charAt(cursor + len)){
len++;
// 검색 버퍼를 벗어나거나 룩어헤드 버퍼 끝에 도달하면 중단
if(i + len >= cursor){
break;
}
}
if(len > bestLength){
bestLength = len;
bestDistance = cursor - i;
}
}
char nextChar;
if(cursor + bestLength < input.length()){
nextChar = input.charAt(cursor + bestLength);
}else{
nextChar = '\0'; // 끝
}
compress.add(new Lz77Token(bestDistance, bestLength, nextChar));
cursor += (bestLength + 1); // (일치한 길이 + 다음문자 1개)만큼 커서 이동
}
return compress;
}앞서 만든 토큰을 활용해서 LZ77 알고리즘 동작 방식대로 압축하는 메소드를 구현합니다
압축 해제 로직 메소드
public static String decompress(List<Lz77Token> tokens){
StringBuilder sb = new StringBuilder();
for (Lz77Token token : tokens) {
if(token.getLength() > 0){
int startIdx = sb.length() - token.getDistance();
for (int i = 0; i < token.getLength(); i++) {
if(startIdx + i < sb.length()){
sb.append(sb.charAt(startIdx + i));
}
}
}
if(token.getNextChar() != '\0'){
sb.append(token.getNextChar());
}
}
return sb.toString();
}이어서 압축해제하는 메소드 로직을 구현합니다
토큰의 정보를 순회하면서, sb의 전체 길이에서 distance만큼 빼준 위치에서 시작해서
그 위치부터 길이만큼 문자를 가져와 sb에 append합니다.
이 로직이 가능한 이유는 처음은 반드시 슬라이딩 윈도우 방식이라 없는 경우 (0,0, 다음문자),
앞서 있는 경우에는 정확한 위치가 명시되어 정상적으로 동작하기 떄문입니다
결과
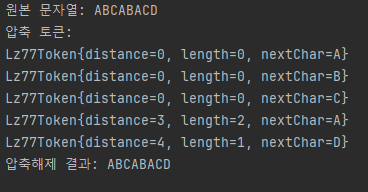
정상적으로 압축되고 압축해제도 되는 것을 확인할 수 있습니다
원본 문자열의 길이는 8이지만, 압축된 결과 길이는 5로 줄어든 것을 확인할 수 있습니다
고민해볼만한 점
하지만 다시 생각해보면 압축 토큰 형식의 오버헤드 때문에
오히려 실제 크기는 더 늘어났다고 할 수 있습니다
따라서 이렇게 압축할만한 문자열이 적은 경우에는 오버헤드 때문에 오히려 비효율적일 수 있지만
압축할만한 문자열이 많을 경우, 효율적으로 동작할 수 있습니다
따라서 LZ77 알고리즘을 활용한 압축방식이 반드시 좋다고는 할 수 없습니다
정리
LZ77알고리즘의 개념과 동작방식, 그리고 구현까지 정리했습니다
Deflate 압축 알고리즘에서 사용하는 알고리즘으로 현대 압축 알고리즘의 근간이 되는
무손실 압축 알고리즘이라고 할 수 있습니다
압축방식과 알고리즘이 무엇인지만 알고 있었지 그 개념과 세부 동작은 자세히 알 일이 없었는데
이번 기회로 그 내부 동작에 대해 깊게 이해할 수 있게 되었습니다
