서론
지난 1부에 이어서 RESTful한 API를 설계하겠습니다
이번 2부의 목표는 다음과 같습니다
- Versioning
- PATCH에서 PUT으로 전환
- 비동기 응답 개발
- Paging
Versioning
URI의 변경사항을 버전을 명시해서 관리하는 방법입니다.
REST API의 변경사항이 생긴다면, 이것을 사용하는 사람들에게 알려야합니다.
이때 버전을 갱신한다면, 사용자들은 해당 API가 변경되었다는 것을 인지할 수 있습니다
언제 Versioning을 해야할까?
Versioning의 적용여부는 팀의 요구사항에 따라 다를 수 있습니다.
다만, 일반적으로 팀의 협업 과정에 큰 영향을 미치는 변경 사항이 발생하면 Versioning이 필요합니다.
이 기준을 바탕으로, 다음과 같은 경우 Versioning을 적용하기로 결정했습니다
- API URI가 변경된 경우
- 응답 형식이 변경된 경우(Body 모두 포함)
- 응답 데이터 타입이 변경된 경우(문자열 -> 숫자, Enum 값/이름 변경)
다음과 같은 경우는 Versioining을 하지 않기로 결정했습니다
- 응답 Header가 변경된 경우
- API URI에 Parameter가 추가된 경우
- 응답 상태코드가 변경된 경우
Versioning을 하는 방법
Versioning의 방법은 다음과 같습니다.
1. URI경로를 이용하는 방법
2. Query Parameter를 이용하는 방법
3. Custom Header를 이용하는 방법
해당 프로젝트는 1번 방법을 선택했습니다
2번 방법은 URI가 너무 길어지고 Query Parameter에 대한 작업이 추가로 필요합니다
3번 방법은 헤더에 대한 이해와 헤더를 포함하고 추출하는 작업이 마찬가지로 필요합니다
1번 방법은 URI가 조금 길어진다는 단점이 있지만, 텍스트로 명시하기 때문에
복잡한 이해과정없이 직관적으로 판단할 수 있다고 생각했습니다
따라서 1번 방법을 Versioning의 방법으로 선택했습니다.
Versioning 적용
@PostMapping("/draw/v1")위와 같은 형태로 모든 URI에 Versioing을 적용했습니다!
웹앱 서버가 다수라면?
웹 앱 서버가 다수일 경우 각각의 URI에 Versioning을 명시했을 때, 관리가 복잡해집니다.
보통 MSA나 로드밸런싱을 제공하는 운영환경의 경우 위와같은 상황이 발생할 수 있습니다
따라서 보통 Proxy 서버에서 Versioinig을 담당합니다.
현재는 백엔드 개발에 집중하고 있기 때문에,
웹앱 서버에 명시했지만 이후 운영환경에서 로드밸런싱을 고려한다면
Proxy 서버에서 Versioning을 담당하도록 개선할 계획입니다.
PATCH -> PUT으로 전환한 과정
PUT이나 PATCH 요청을 통해 CREATE한 데이터를 수정할 수 있습니다
PUT은 모든 데이터 항목을 알아야 하고, 전체 데이터를 수정합니다
PATCH는 모든 데이터 항목을 몰라도 되며, 일부 데이터만 수정할 수도 있습니다.
처음 선택한 방법은 PATCH Method
처음 선택한 방법은 PATCH 방법이었습니다.
PATCH 방법을 선택한 이유는 다음과 같습니다
- 일부만 데이터만 수정할 수 있도록, 유연한 환경을 제공하고 싶었다.
기존의 PATCH 요청 처리 로직
public void updateEntry(EntryRequestDto entryRequestDto){
this.name = entryRequestDto.getName();
this.location = entryRequestDto.getLocation();
this.building = entryRequestDto.getBuilding();
this.teamNumber = entryRequestDto.getTeamNumber();
this.professorName = entryRequestDto.getProfessorName();
this.leaderName = entryRequestDto.getLeaderName();
this.entryType = entryRequestDto.getEntryType();
}서비스 로직에서 해당 메소드를 호출합니다.
그리고 요청받은 EntryRequestDto의 값으로 업데이트 한 후,
JPA의 변경감지를 통해 DB의 데이터를 업데이트 합니다
기능적인 문제점
하지만 위 방식의 경우 다음 문제가 발생할 수 있습니다.
- 일부 데이터만 입력하는 경우 null로 채워지며, DB 데이터도 null로 업데이트된다
- null Validation을 제공할 수 없기 때문에, Nullable하다는 위험성이 있다.
따라서 해당 문제를 해결하기 위해, 모든 메소드에서 null 체크를 진행해야합니다
설계를 고려했을 때, PATCH가 타당한가?
PATCH방식을 사용할 경우, 개발 비용이 추가로 발생합니다.
필드의 수가 많아진다면, 비용의 크기가 더욱 커질 것입니다
그렇다면 PATCH 방식을 유지해야할 정도로 효율적으로 사용하고 있을까요?
아래는 특정 도메인을 CREATE할때 요청 양식입니다
{
"name": "string",
"location": "string",
"building": "string",
"teamNumber": "string",
"professorName": "string",
"major": "string",
"leaderName": "string",
"entryType": "PRELIMINARY"
}그리고 아래는 PATCH요청할 때 양식입니다
{
"name": "string",
"location": "string",
"building": "string",
"teamNumber": "string",
"professorName": "string",
"major": "string",
"leaderName": "string",
"entryType": "PRELIMINARY"
}클라이언트의 CREATE와 PATCH 요청 양식에는 큰 차이가 없습니다.
저 필드 중 일부 데이터만 보내는 것도 클라이언트의 추가적인 작업이 필요하기 때문에
사실상 CREATE와 동일한 요청 양식으로 전달합니다
PUT으로 전환
PATCH 요청방식을 사용했을 때의 장점을 전혀 활용하지 못하고 있습니다.
또한 PATCH 요청방식을 제대로 사용하기 위해서는 추가적인 개발 비용이 발생합니다.
해당 문제를 바탕으로 고민한 결과
현재 프로젝트는 PATCH의 활용 가치가 적다고 판단했고 PUT 요청 방식으로 전환했습니다
@PutMapping("/entries/{entry}/v1")위와 같이 PUT 방식으로 교체했습니다.
클라이언트는 UPDATE할 도메인의 모든 필드를 함께 전달해야합니다
번외: PK가 빠졌는데 PUT의 원칙을 위배한거 아닌가?
전환과정 중에 소제목과 같은 의문을 가졌습니다.
모든 필드 데이터를 넘겨줘서 해당 데이터로 교체한다는 것이 PUT 방식인데,
사용자가 PK를 넘겨주지 않았을 때도 PUT 방식일까? 라는 의문을 가졌습니다.
사실 사용자는 PK를 넘겨주고 있습니다. 바로 파라미터에서 넘겨주고 있습니다!
@PutMapping("/entries/{entry}/v1")
public ResponseEntity<EntryResponseDto> updateEntry(
@PathVariable(name = "entry") Long entryId,
@RequestBody @Validated EntryRequestDto entryRequestDto
){바로 위와같이 PK를 넘겨주고 있기 때문에, PUT 원칙을 위배하는 것은 아니었습니다!
정리
PATCH 요청 방식을 PUT방식으로 바꾸면서, 개발 비용을 절약했습니다.
또한 입력 데이터에 대한 Null 검증을 적용하면서, 더 안전한 데이터를 유지하게 되었습니다!
비동기 작업 상태 API 개발 과정
현재 프로젝트는 외부 API를 사용할 때, 비동기 작업으로 진행하고 있습니다.
다음 두가지 상황에서 비동기로 작업합니다
- 인증 이메일 발송
- FCM TOPIC 구독 등록/취소
비동기 방식의 문제점
비동기 방식은 작업의 처리 결과를 요청한 클라이언트에게 응답할 수 없습니다.
비동기 작업이 정상적으로 처리되었는지 클라이언트가 확인하려면
작업 진행 상태를 확인할 수 있는 별도의 API를 이용해야합니다.
클라이언트가 모든 작업상태를 확인해야할까?
비동기 작업의 상태를 제공하기 전에 소제목과 같은 고민을 했습니다
클라이언트가 별도의 API를 통해 작업상태를 모두 확인해야할까요?
팀은 이 고민에 대해서 다음과 같이 결론을 내렸습니다
- 사용자가 작업의 상태를 외부 환경을 통해서 단시간에 확인가능하면 API를 확인하지 않는다 -> 인증 이메일 발송
- 만약 외부환경을 통해서 확인하지 못하거나 단시간에 확인하지 못하면 API를 확인하지 않는다 -> FCM TOPIC 구독 등록/취소
인증 이메일 발송 로직은 API로 확인하지 않는다
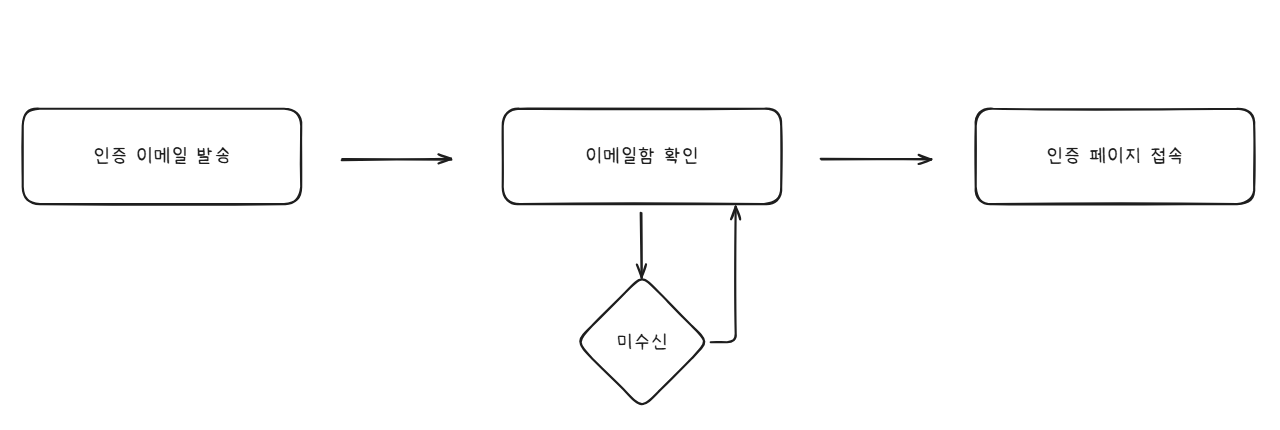
사용자는 학교 이메일 수신함에서 인증 이메일을 확인할 수 있습니다.
사용자는 발송 버튼을 누른 뒤 바로 확인하기 때문에,
작업의 진행 여부를 빠르게 확인할 수 있습니다.
따라서 별도의 API 확인 로직이 필요없다고 판단했습니다.
FCM TOPIC 구독 등록/취소 로직은 API로 확인한다
해당 로직의 목적은 웹 푸시알림을 받기 위함입니다.
작업의 성공/실패 여부는 이벤트 시작시간까지 확인할 수 없습니다.
또한 구독 작업은 한번 실패할 경우, 사용자가 다시 사용할 이유가 없습니다.
이미 끝난 이벤트의 시작시간을 알 필요는 없기 때문입니다
따라서 주기적으로 API에 요청해서 작업의 진행상황을 확인하기로 결정했습니다
구독작업 상태관리 기능 개발
구독작업 상태관리 기능을 개발했습니다.
주기적으로 많은 요청이 들어오기 때문에, 최대한 빠른 응답을 하는 것이 중요합니다.
또한 작업이 완료된 경우에는 더이상 해당 상태의 관리가 필요하지 않습니다.
즉, 영속성이 중요하지 않습니다!
따라서 Redis를 이용해서 관리하기로 결정했습니다
Redis의 빠른 응답 특징과 TTL로 효율적인 저장공간 관리 이점을 활용할 수 있기 때문입니다!
구독작업 상태유형
PENDING("작업 미완료", "PENDING"),
SUCCESS("작업 성공", "SUCCESS"),
FAILED("작업 실패", "FAILED")
;구독작업의 상태는 위와같이 정의했습니다.
아직 미완료 상태면 PENDING, 성공 실패 여부에 따라 SUCCESS와 FAILED로 관리합니다.
구독등록 작업
redisTemplate.opsForValue()
.set(favoriteId+"_subscribe", SubscribeStatus.PENDING.getStatus(), 300, TimeUnit.SECONDS);첫 데이터는 Redis에서 PENDING상태로 관리합니다.
ID는 즐겨찾기 PK와 구독 등록/취소를 구분하기 위한 문자열로 정의했습니다
또한 저장공간을 효율적으로 관리하기 위해 TTL을 설정해서 5분동안만 해당 데이터를 유지합니다
apiFuture.addListener(() ->{
try{
TopicManagementResponse response = apiFuture.get();
log.info("토픽 구독 성공: {}", response.getSuccessCount());
if(response.getFailureCount() > 0){
log.info("토픽 구독 실패: {}", response.getFailureCount());
redisTemplate.opsForValue()
.set(favoriteId+"_subscribe", SubscribeStatus.FAILED.getStatus(), 600, TimeUnit.SECONDS);
favoriteRepository.deleteById(Long.parseLong(favoriteId));
return; }
redisTemplate.opsForValue()
.set(favoriteId+"_subscribe", SubscribeStatus.SUCCESS.getStatus(), 600, TimeUnit.SECONDS);
} catch (ExecutionException | InterruptedException e) {
log.error("토픽 구독 관련 예외 발생: {}", e.getMessage());
redisTemplate.opsForValue()
.set(favoriteId+"_subscribe", SubscribeStatus.FAILED.getStatus(), 600, TimeUnit.SECONDS);
favoriteRepository.deleteById(Long.parseLong(favoriteId));
throw new RuntimeException();
}
}, asyncConfig.getSubscribeFcmExecutor());비동기작업 리스너에 상태관리 기능을 추가했습니다.
조건에 따라 성공과 실패로 구분해서 관리하며,
상태 확인 지연시간을 고려해서 해당 데이터는 10분동안 유지되도록 설정했습니다
구독취소 작업
redisTemplate.opsForValue()
.set(favorite.getId()+"_unsubscribe", SubscribeStatus.PENDING.getStatus(), 300, TimeUnit.SECONDS);구독 취소 작업도 ID를 제외하고 등록작업과 동일합니다.
ID만 구분짓기 위해 다른 문자열로 설정했습니다
apiFuture.addListener(()->{
try{
TopicManagementResponse response = apiFuture.get();
log.info("토픽 구독취소 성공: {}", response.getSuccessCount());
if(response.getFailureCount() > 0){
log.info("토픽 구독취소 실패: {}", response.getFailureCount());
redisTemplate.opsForValue()
.set(favorite.getId()+"_unsubscribe", SubscribeStatus.FAILED.getStatus(), 600, TimeUnit.SECONDS);
favoriteRepository.deleteById(Long.parseLong(favorite.getId()+"_unsubscribe"));
return; }
redisTemplate.opsForValue()
.set(favorite.getId()+"_unsubscribe", SubscribeStatus.SUCCESS.getStatus(), 600, TimeUnit.SECONDS);
favoriteRepository.deleteById(favorite.getId());
}catch (ExecutionException | InterruptedException e) {
log.error("토픽 구독취소 관련 예외 발생: {}", e.getMessage());
redisTemplate.opsForValue()
.set(favorite.getId()+"_unsubscribe", SubscribeStatus.FAILED.getStatus(), 600, TimeUnit.SECONDS);
throw new RuntimeException(e);
}
}, asyncConfig.getSubscribeFcmExecutor());이후 처리 작업은 동일합니다.
다만 구독 등록과는 다른점이 한가지 있는데, 취소를 비동기작업 완료시까지 유보합니다
만약 구독 등록이 실패할 경우, 해당 즐겨찾기 데이터를 유지하기 위해 다시 생성해야하는데 이 과정이 꽤 번거롭고 데이터 무결성도 위배하기 때문입니다
따라서 비동기 작업이 완료되고, 구독 취소 상태관리 작업까지 처리된 이후
즐겨찾기 데이터를 삭제하도록 설정했습니다.
비동기 작업 상태확인 API 개발
@GetMapping("/favorites/{favorite}/status/{statusType}/v1")
public ResponseEntity<SubScribeResponseDTO> favoriteStatusCheck(
@PathVariable(name = "favorite") Long id,
@PathVariable(name = "statusType") String type
){
SubScribeResponseDTO subScribeResponseDTO = favoriteCRUDService.getFavoriteStatus(id, type);
return ResponseEntity.ok(subScribeResponseDTO);
}이제 GET 요청을 통해 찾고자 하는 즐겨찾기 PK와 상태유형(구독 등록/취소 여부)을 전달하면, 비동기작업의 진행 상태를 확인할 수 있습니다.
이제 클라이언트는 Polling 방식과 같이 주기적으로 요청하는 방법을 통해 비동기 작업의 상태를 확인하고,
결과에 따라 적절한 후속 작업을 진행할 수 있습니다!
추가: HATEOAS 적용
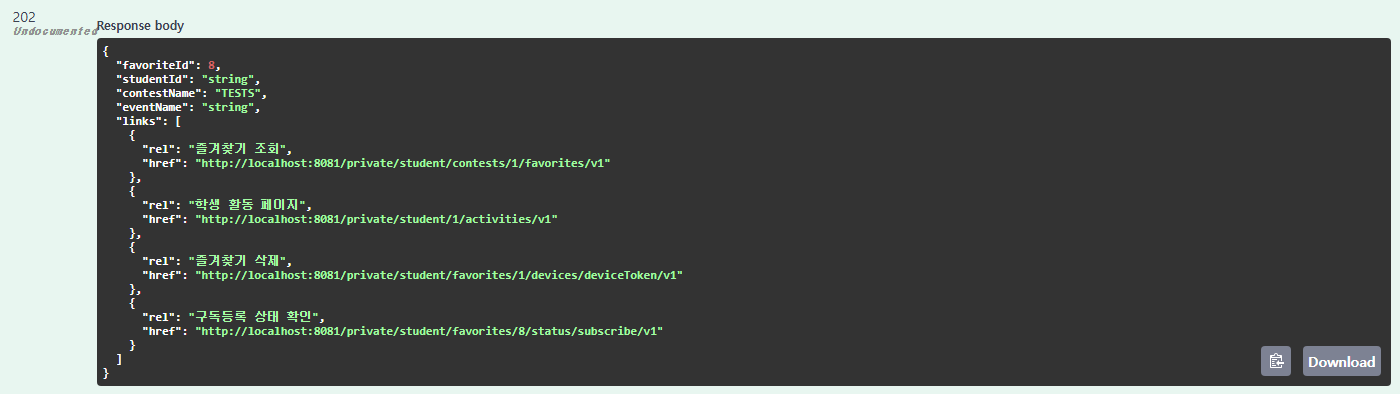
즐겨찾기 등록 로직에 HATEOAS를 적용했습니다.
이제 링크를 통해 구독 등록 상태를 확인할 수 있습니다!
Paging
특정 Collections을 조회할 때 데이터의 양이 많고, 이것을 여러 사용자가 요청한다면
서버의 OOM과 같은 치명적인 문제가 발생할 수 있습니다.
따라서 이런 문제를 해결하기 위해 데이터의 양이 많을 것으로 예상되는 조회에 대해서
모든 데이터를 한번에 조회하지 않고,
요청한 크기만큼만 데이터를 가져오는 Paging 방법을 사용할 수 있습니다
Paging을 활용하면 서버의 부하도 줄일 수 있고,
클라이언트에게 더 빠른 응답속도로 데이터를 제공할 수 있습니다!
Paging 기능 개발
Spring boot는 다양한 Paging기능을 제공하기 때문에, 쉽게 구현할 수 있습니다
@GetMapping("contests/v1")
public ResponseEntity<List<ContestInfoResponseDto>> readContestInfo(
@RequestParam(value = "offset", required = false)
Integer offset,
@RequestParam(value = "limit", required = false)
Integer limit
){
return ResponseEntity.ok(commonPageService.readContestInfo(PageRequest.of(offset-1, limit)));
}위와같이 offset과 limit을 쿼리스트링으로 지정해서 받는 방법과
Pageable로 받는 방법 중 한가지를 선택해서 Paging 기능을 구현할 수 있습니다.
Pageable을 사용할 경우, offset과 limit과 더불어 sort까지 지정해서 요청할 수 있습니다
하지만 프로젝트에서 Sorting은 FE가 담당하므로,
해당 기능을 제공하지 않기 위해 별도의 쿼리스트링으로 offset과 limit을 받습니다.
Spring Pagination의 offset은 0부터 시작하기 때문에, 사용자가 원하는 데이터를 얻지 못할 수 있습니다
따라서 사용자가 입력한 offset에 -1을 적용해서 서비스 로직으로 넘기도록 구현하였고,
만약 0이하의 offset이 들어올 경우, 400 예외가 발생하도록 설정했습니다
서비스 로직의 Paging
@Transactional(readOnly = true)
public List<ContestInfoResponseDto> readContestInfo(Pageable pageable){
List<Contest> contests = contestRepository.findAll(pageable).getContent();
return contests.stream()
.map(a -> ContestInfoResponseDto.builder()
.contestId(a.getId())
.contestName(a.getName())
.build())
.toList();
}서비스 로직은 Repository의 Page 데이터를 List 형식으로 받아오도록 개발했습니다
Repository의 Paging
public interface ContestRepository extends JpaRepository<Contest, Long>, ContestRepositoryCustom {
Page<Contest> findAll(Pageable pageable);
}JPA Repository에 Paging 기능을 적용하고 싶다면, 위와같이 설정하면 됩니다.
반환 타입은 Page, Slice중 선택할 수 있는데,
현재 Paging이 필요한 환경은 전체 데이터가 필요한 게시판과 같은 환경이기 때문에
Page 반환타입을 선택했습니다
QueryDsl의 Paging
@Override
public List<MemberInfoResponseDto> drawMemberInfoRead(Long contestId, Pageable pageable) {
List<Member> members = queryFactory
.select(participateContest.memberParticipateContestState)
.from(participateContest)
.where(participateContest.contestParticipateContestState.id.eq(contestId).and(
participateContest.eventsCount.goe(5)
))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
return members.stream()
.map(p -> MemberInfoResponseDto.builder()
.id(p.getId())
.name(p.getName())
.email(p.getUniversityEmail())
.major(p.getMajor())
.memberType(p.getMemberType())
.studentId(p.getStudentId())
.build())
.toList();
}QueryDsl의 경우 Pageable의 offset과 limit 데이터를 쿼리문에 포함하도록 개발했습니다.
테스트
아래와 같이 6개의 FAVORITE 데이터를 생성했습니다.

offset=1&limit=1
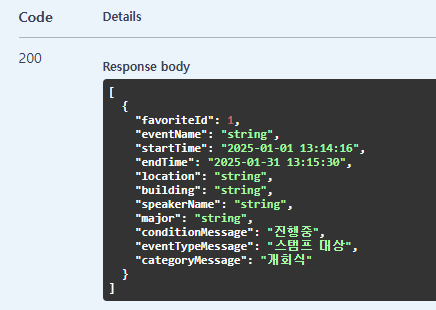
위와같은 설정일 때 첫번째 데이터와 한가지 데이터만 조회하는 것을 확인할 수 있습니다
offset=2&limit=2
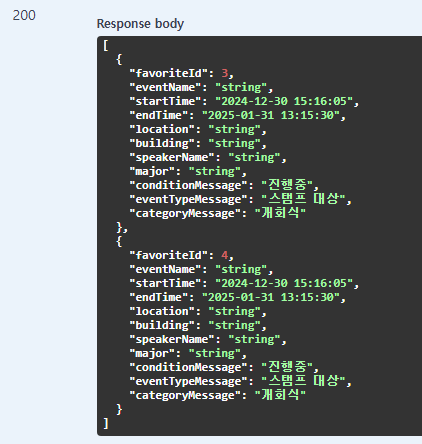
두개씩 제한했을 때, 두번째 페이지의 데이터를 조회합니다
마무리
REST API에 대한 정리가 끝났습니다
REST API에 대한 학습과 정리를 진행하면서,
설계방법을 잘못 이해하고 개발했음을 깨닫고 크게 반성했습니다.
개념을 바로 잡기 위해 학습과 프로젝트 개선을 병행하다보니 예상보다 많은 시간이 소요되었네요
그래도 REST API의 개념과 올바른 설계 방식에 대해 깊이 이해할 수 있어서 유익한 시간이었습니다.
이 경험을 바탕으로 앞으로 올바른 REST API를 설계하는 개발자로 성장하겠습니다
참고:
