
1. 정렬
정렬이란 데이터를 기준에 따라 순서대로 나열하는 것을 말한다.
(1) 선택 정렬
무작위의 수들이 주어질 때, 가장 작은 수를 찾아 첫번째 데이터와 바꾸고, 두번째로 작은 수를 찾아 두번째 데이터와 바꾸는 식으로 정렬을 하는 방식이 선택 정렬이다. 데이터의 수가 N이라고 할 때, 비교 연산을 (N-1)+(N-2)+...+2번 수행해야 하므로 시간 복잡도는 O(N^2)이다.
(2) 삽입 정렬
첫번째 데이터를 기준으로 이후 데이터들이 어느 위치에 들어갈지 판단하여 삽입하는 것이 삽입 정렬이다. 삽입 정렬의 시간 복잡도는 최악의 경우 선택 정렬과 마찬가지로 O(N^2)이지만 이미 정렬이 되어있는 경우 O(N)의 시간 복잡도를 가진다. 정렬이 거의 되어있는 상태라면 선택 정렬보다 삽입 정렬을 사용하는 것이 훨씬 효율적이다.
(3) 퀵 정렬
기준 데이터(pivot)를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방식이 퀵 정렬이다. 퀵 정렬은 평균 시간 복잡도가 O(NlogN)으로 속도가 빠르기 때문에 많이 사용된다.
(4) 계수 정렬
계수 정렬은 수행시간 O(N+K)를 보장하며, 가장 큰 데이터와 가장 작은 데이터의 차이가 백만을 넘지 않을 때 효과적이다.
(5) 정렬 라이브러리
sorted()와 .sort()를 사용해 자동으로 정렬을 할 수 있다. 일반적으로 퀵 정렬보다는 느리지만 최악의 경우에도 시간 복잡도 O(NlogN)을 보장한다. key나 lambda를 사용해 정렬 기준을 설정할 수 있다.
2. 예시문제
(1) 프로그래머스

def solution(numbers):
li = list(map(str, numbers))
li.sort(key=lambda x: x*3, reverse=True)
return str(int(''.join(li)))
def solution(citations):
citations.sort(reverse=True)
h = []
for i in citations:
if i >= len(h):
h.append(i)
else:
break
return min(len(h), h[-1])(2) Baekjoon Online Judge
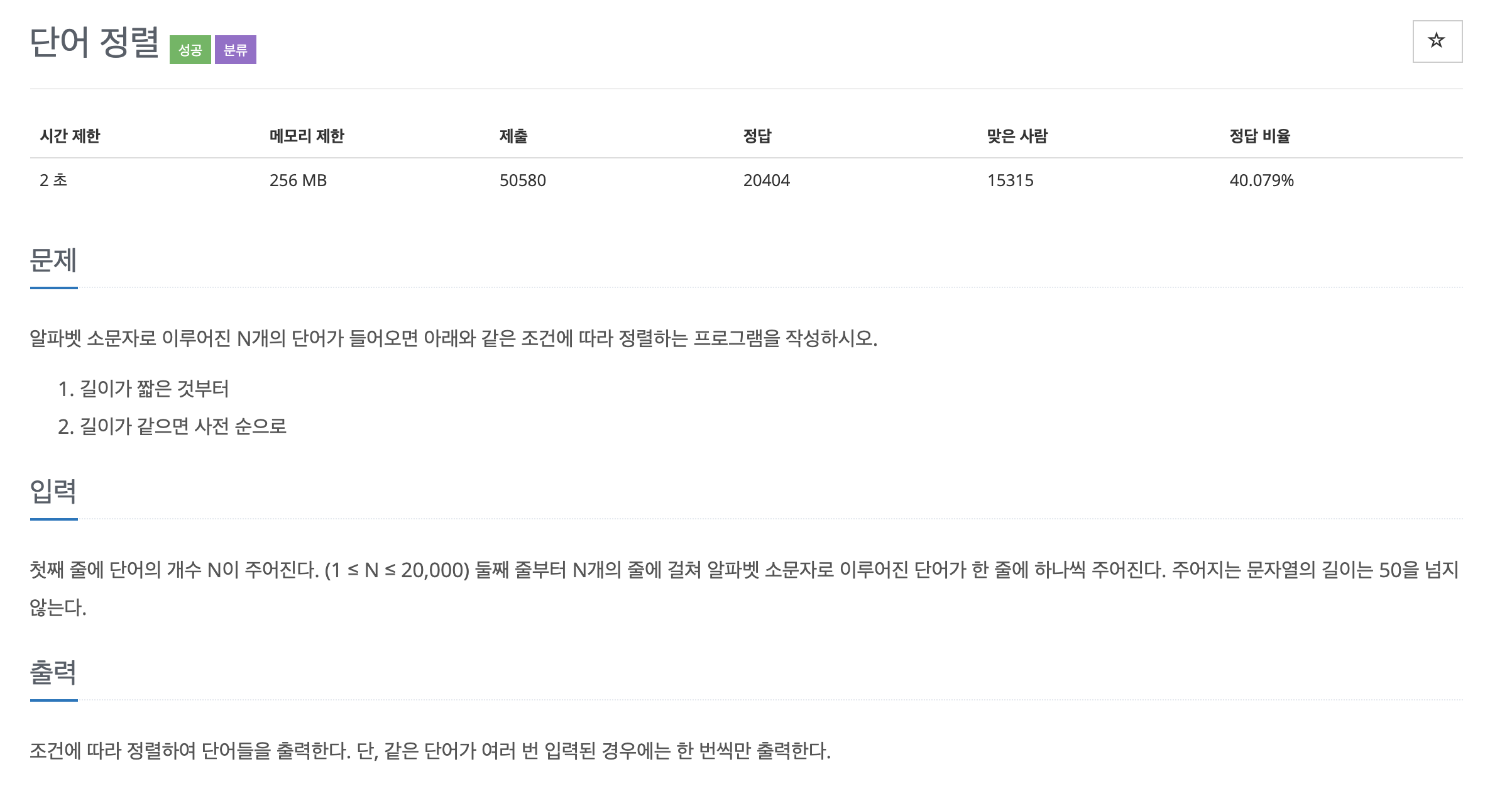
import sys
n = int(input())
li = list(set([sys.stdin.readline().rstrip() for x in range(n)]))
li.sort()
li.sort(key=lambda x:len(x))
for word in li:
print(word)
https://dev.to/ninahwang