최근 러닝 보조 SW를 개발하고 있습니다.
기존에는 로컬에서만 데이터를 받아와서 실행시켰지만,
이제는 조금 더 발전시켜서 APP으로 쓰고 싶어서
로직을 파이썬 서버에서 실행시키는 API로 불러오는 과제가 생겼습니다.
이 장에서는 그 과제를 해결하는 과정에 대해 정리하겠습니다.
Task 요구 사항 정리
Notion의 데이터를 가공 후 전처리하고 fastAPI로 데이터를 보낸다.
Task 해결 과정
notion의 openAPI 명세서 확인
먼저 데이터를 받아오고, 전처리하고 데이터를 보내는 구조이므로
스프링의 4계층과 유사하게 컨트롤러-서비스-모델로 설계하는 방향을 선택했습니다.
openAPI를 통해 응답 데이터를 받아오므로
우선 모델 계층에서 응답 데이터를 가공해서 원하는 데이터만을 뽑아보는 과정을 가졌습니다.
응답 데이터는 notion의 API 명세서를 봐서 확인했습니다.
https://developers.notion.com/docs/working-with-databases
응답데이터는 이런 식으로 구성됐습니다.
{
"object": "list",
"results": [
{
"object": "page",
/* details omitted */
}
],
"has_more": false,
"next_cursor": null
}results에 찾는 데이터가 있고, has_more로 종료 여부를 판단할 수 있고, next_cursor로 다음 데이터로 이동할 수 있는 것을 확인했습니다.
그래서 데이터 받아오는 알고리즘은 아래와 같이 설계했습니다.
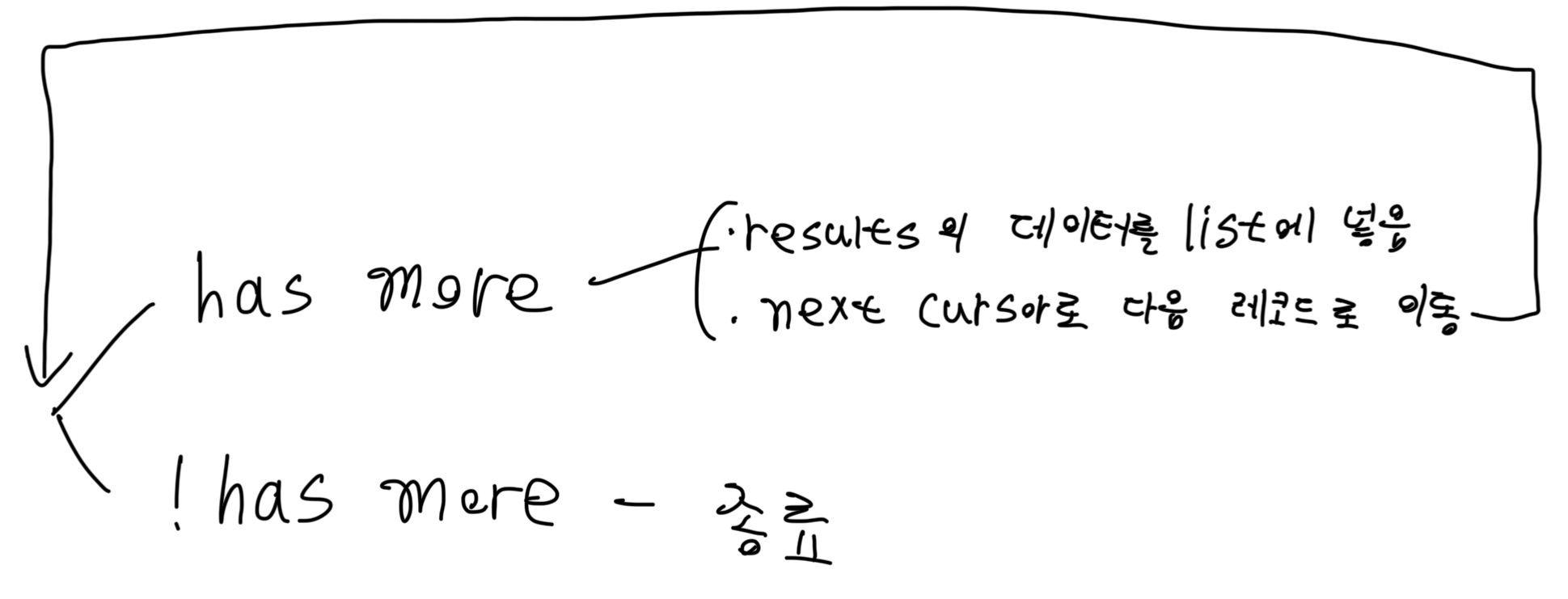
파이썬 코드로는 아래와 같이 구현할 수 있습니다.
def fetch_all_rows(self):
results = []
payload = {}
while True:
r = requests.post(self.api_url, headers=self.headers, json=payload, timeout=10)
r.raise_for_status()
data = r.json()
results.extend(data.get("results", []))
if data.get("has_more"):
payload = {"start_cursor": data.get("next_cursor")}
else:
break
return results데이터 모델 설계
전체 데이터를 가져오는 알고리즘을 실행시키면,
데이터 자체를 가져왔을 뿐 불필요한 데이터 또한 포함되서 가공할 필요가 있었습니다.
요약하면, 레코드 별로 properties라는 필드에 칼럼이 또 자식으로 필드로 있고, 여기에 plain_text라는 필드에 원하는 데이터가 있었습니다.
그래서 우선 레코드 별로 properties를 뽑아내고,
여기서 칼럼 별로 데이터를 뽑아내는 알고리즘이 필요했습니다.
이를 구조로 아래와 같이 설계했습니다.
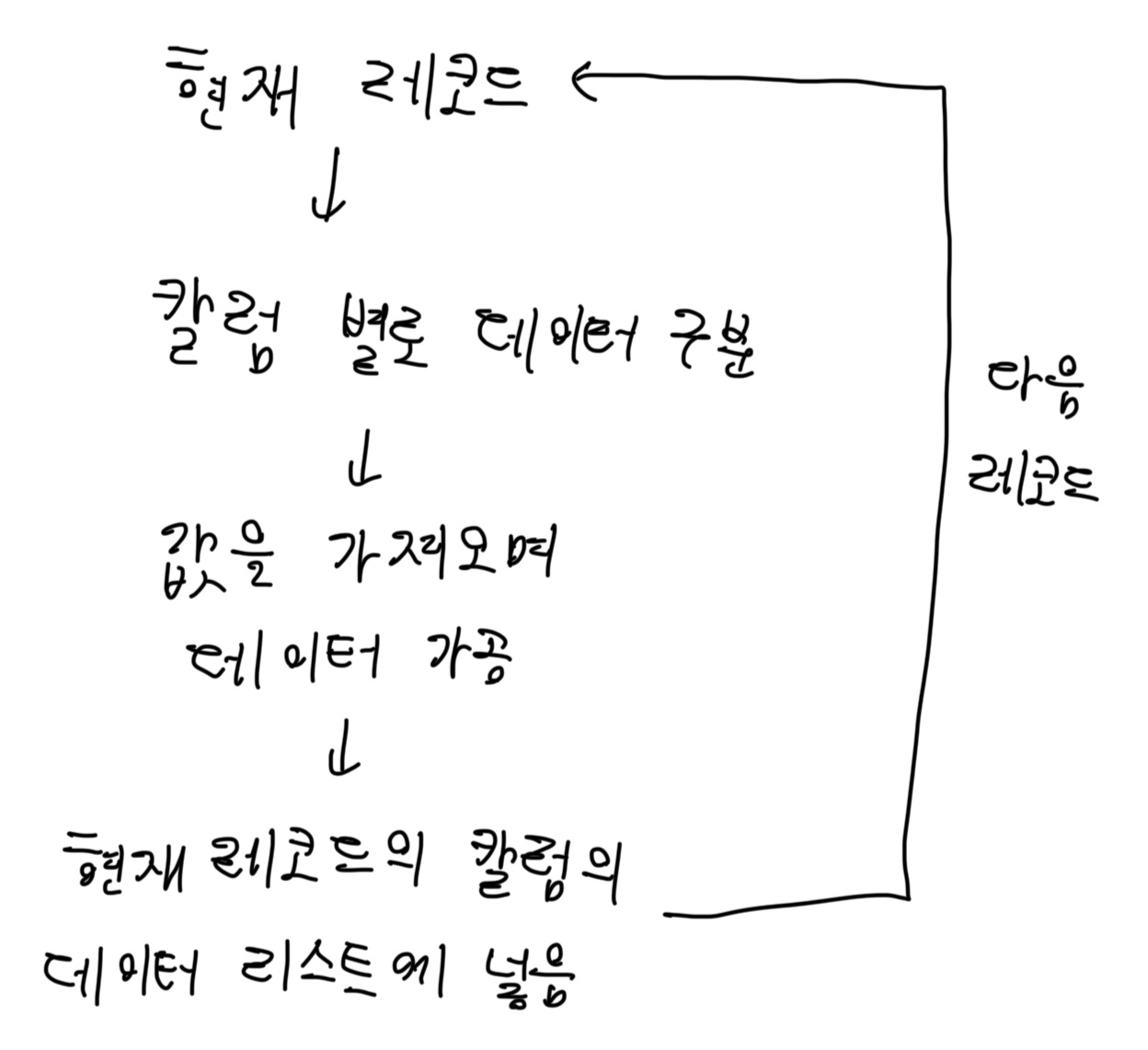
파이썬 코드로는 아래와 같이 구현했습니다.
먼저, 현재 칼럼에서 원하는 데이터 값을 뽑아내는 코드입니다.
def extract_text(self, prop: dict):
if not prop:
return None
t = prop["type"]
arr = prop.get(t, [])
if arr:
return "".join([x.get("plain_text", "") for x in arr])
return None다음은 레코드를 순회하며 원하는 데이터를 가공하는 코드입니다.
def create_model(self):
data = []
rows = self.fetch_all_rows()
for row in rows:
props = row["properties"]
date = self.extract_text(props.get("date"))
time = self.extract_text(props.get("time"))
distance = self.extract_text(props.get("distance"))
kcal = self.extract_text(props.get("kcal"))
first = [date, time, distance, kcal]
data.append(first)
return list(reversed(data))레코드 별로 리스트를 이루며 이 리스트를 리스트에 넣는 식으로 구현했습니다.
reversed를 한 이유는 데이터가 stack처럼 최근 것이 맨 앞에 있어서 순서를 위해 사용했습니다.
데이터 전처리
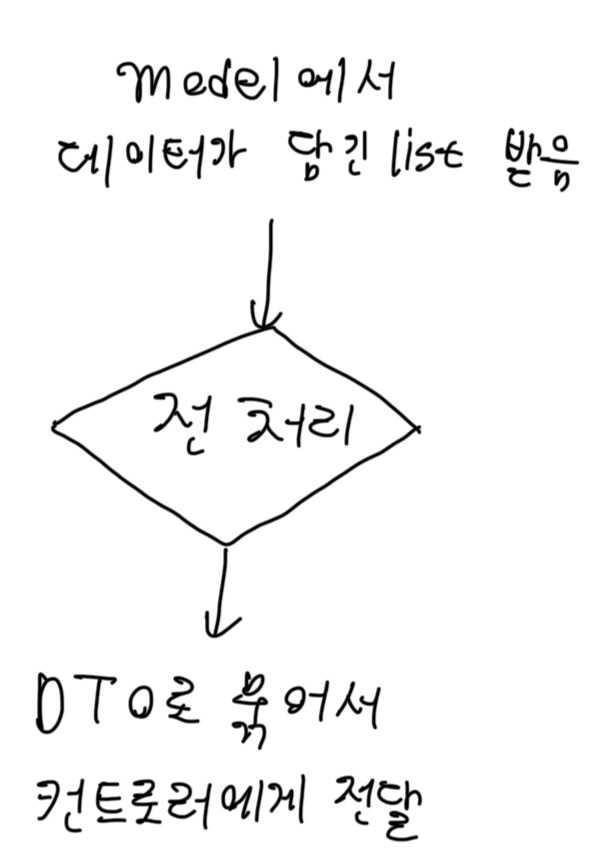
필요한 데이터만을 찾는 가공을 했으면 이제 서비스 레이어에서 데이터 전처리를 거쳐야 합니다.
하지만, 현재 시점에서는 딱히 할 전처리가 없어서 일단은 데이터를 DTO로 묶는 과정을 가졌습니다.
(그래도 나중에 전처리가 필요할 수 있어서 서비스 레이어로 분리하는 편이 더 좋을거 같았습니다.)
과정은 아래처럼 설계했습니다.
전처리는 알고리즘 구현해서 그 사이에 넣으면 되니 지금은 생략했습니다.
API 테스트
다음은 컨트롤러에서 API를 할당하고,
postman으로 API test를 해봤습니다.
main 함수에서 fastAPI에 컨트롤러를 라우팅하고
shell에서 uvicorn (파일 이름):app --reload을 실행하면 됩니다.
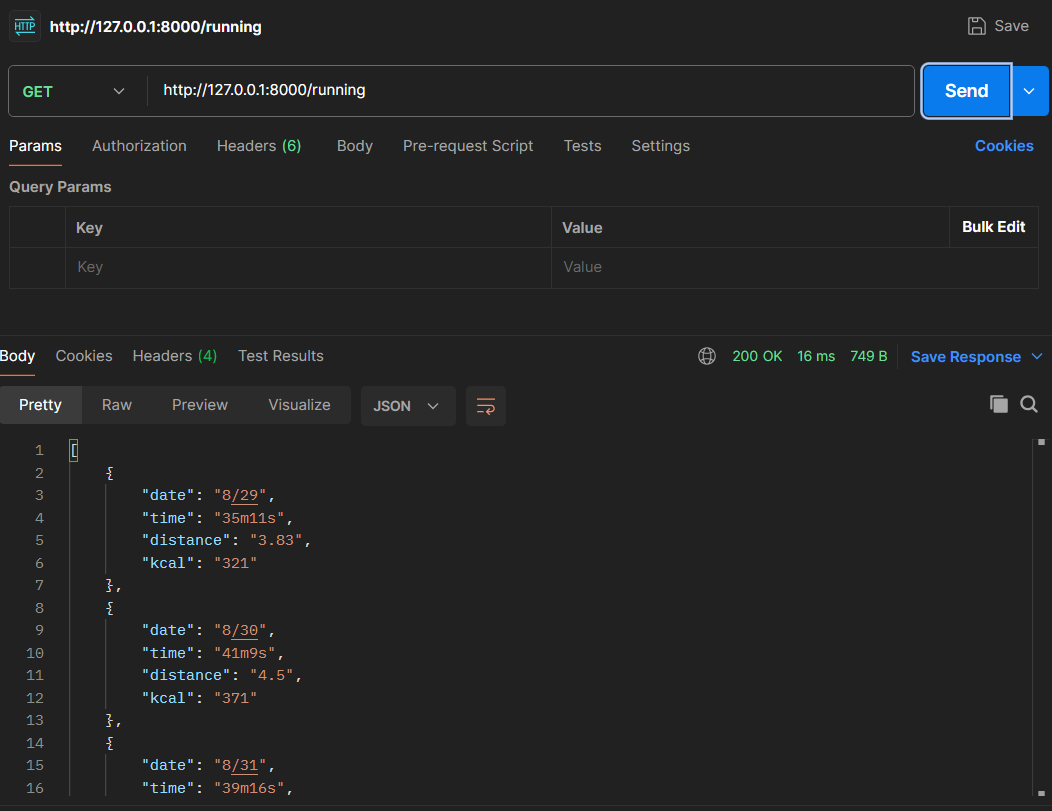
데이터가 잘 전송된 것을 볼 수 있습니다.
후기
java가 아닌 다른 언어에서 프레임워크 없이
4계층 식으로 API를 구현하니 spring에서 왜 4계층을 사용했는지 이해가 됐습니다.
각 클래스의 역할을 분리해 놔야 추후 코드를 수정할 상황이 됐을 때 큰 번거로움 없이 수정할 수 있다는 것을 깨달았습니다.
또 openAPI를 사용할때 API 명세서를 어떻게 확인해야할지 배웠습니다.
무엇을 요청하면 어떻게 응답하고, 여기서 원하는 데이터를 어떻게 가공할지.
1단계 더 성장할 수 있는 과제였습니다.
구현된 코드는 아래 링크에서 볼 수 있습니다.
https://github.com/HwangRock/RunnerAndLearner
