[논문리뷰] A Hybrid Search Method of A* and Dijkstra Algorithms to Find Minimal Path Lengths for Navigation Route Planning (IEIE 2014)
논문리뷰
이 논문의 주요 내용은 내비게이션 경로 설정에서 최단거리 탐색을 위한 A⁕ 와 Dijkstra 알고리즘의 하이브리드 검색법에 대한 연구이다. 논문에서는 A⁕ 와 Dijkstra 알고리즘을 결합해 최적의 경로를 빠르고 효율적으로 찾는 방법을 제안한다.
Introduction
해당 논문에서는 차량용 내비게이션에서 사용되는 경로탐색 알고리즘에 대해 다루고 있다. 차량용 내비게이션은 GPS를 활용해 차량의 위치를 파악하고 경로를 탐색하는데 사용된다. 연구 당시 내비게이션에서는 운전자용 Database에 180만개의 링크를 이용해 경로를 탐색하였다. 하지만 이런 식으로 링크 간 경로를 탐색함에 있어 시작지점에서 목적지점까지 거리가 멀어질수록 연산비용은 급격히 증가하게 된다.
경로탐색 알고리즘에 있어 기본적인 알고리즘인 다익스트라 알고리즘은 항상 최단 경로를 찾을 수 있지만 탐색가능한 모든 경로를 검색하기 때문에 연산량이 많은 알고리즘이다.
A⁕ 알고리즘에서 탐색시간은 탐색할 노드를 저장하는 open list 크기에 따라 비례하는데 시작지점과 목적지점 간 거리가 멀수록 open list의 크기가 증가하여 연산량이 증가하게 된다. 따라서 open list의 크기를 줄이는 것이 관건이지만 잘못된 휴리스틱을 적용한다면 탐색 효율이 저하되는 결과를 가져오기도 한다. 또한 A⁕ 알고리즘은 휴리스틱에 근거해 탐색공간을 줄일 수 있지만 최단 경로를 보장하지는 못한다는 한계점을 갖는다.
Related work
경로탐색 과정에서 시작지점과 목적지점 간 거리가 멀어질수록 연산량에 따라 늘어나는 탐색 시간을 단축시키기 위해 다음과 같은 연구들이 진행되었다.
1) Bi-directional search
Bi-directional 검색 방식은 경로탐색 과정에서 시작지점과 목적지점을 동시에 탐색하는 방식이다. 일반적인 경로탐색 알고리즘에서 단방향 탐색은 시작지점에서 목적지점까지 한 방향으로 탐색만 진행한다. 반면 양방향 탐색 방식은 두 개의 탐색 그래프를 사용한다.
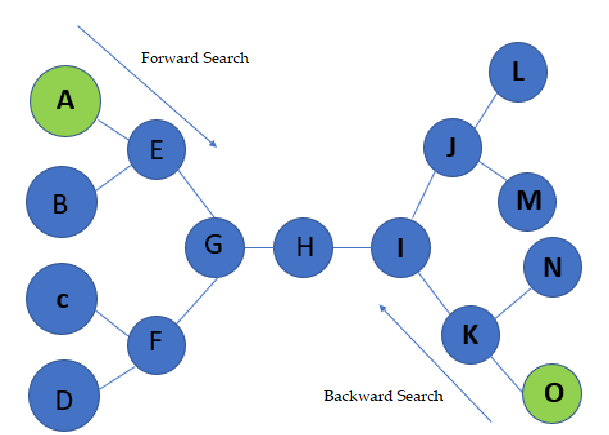
시작지점에서 목적지점으로 이동하는 Forward Search와 목적지점에서 시작지점으로 이동하는 Backward Search 두 개의 탐색 그래프를 통해 동시에 탐색하면서 시작지점과 목적지점 중간에서 만나는 지점을 찾게 된다.
이런 식으로 단방향 탐색에 비해 탐색 과정에서 필요한 연산량을 줄여주며 탐색 거리가 멀어질수록 탐색 시간을 줄여줄 수 있다.
2) LRTA⁕
LRTA⁕(Learning Real Time A⁕) 알고리즘은 실시간 경로탐색 문제에 사용되는 학습 기반 알고리즘이다. A⁕ 알고리즘을 기반으로 실시간으로 환경을 학습하며 탐색 과정을 지속적으로 최적화하므로 긴 거리의 경로 탐색에 있어 효율성을 개선한다.

LRTA⁕는 탐색을 진행하며 환경에 대한 정보를 학습하는데 이 때 탐색 경로를 결정할 때 현재까지 학습된 정보를 사용해 더 효율적인 결정을 내릴 수 있도록 한다. 탐색 과정 중 휴리스틱 값을 실시간으로 업데이트하며 초기에 부정확할 수 있는 휴리스틱 추정치를 점차 개선함으로써 점진적 학습 과정을 통해 탐색 시간을 절약할 수 있다.
탐색 중에 얻은 새로운 정보를 기반으로 탐색 경로를 동적으로 조정하는데, LRTA⁕의 성공적인 적용은 적절한 휴리스틱 함수의 선택과 초기 설정에 크게 의존하므로 이를 고려해 신중한 휴리스틱 함수 설계가 필요하다.
3) IDA⁕
IDA⁕ 알고리즘은 A⁕ 알고리즘의 변형으로 시작지점과 목적지점 간의 예상 비용을 휴리스틱 함수를 통해 계산하고 총 비용을 최소화하는 경로를 탐색한다는 점에서 동일하지만, IDA⁕ 알고리즘은 모든 노드를 메모리에 저장하지 않고 현재 경로의 비용과 예상 비용의 합이 특정 임계값을 초과할 경우에는 해당 경로를 버리고 다른 경로를 탐색하여 탐색 시간을 줄일 수 있다.
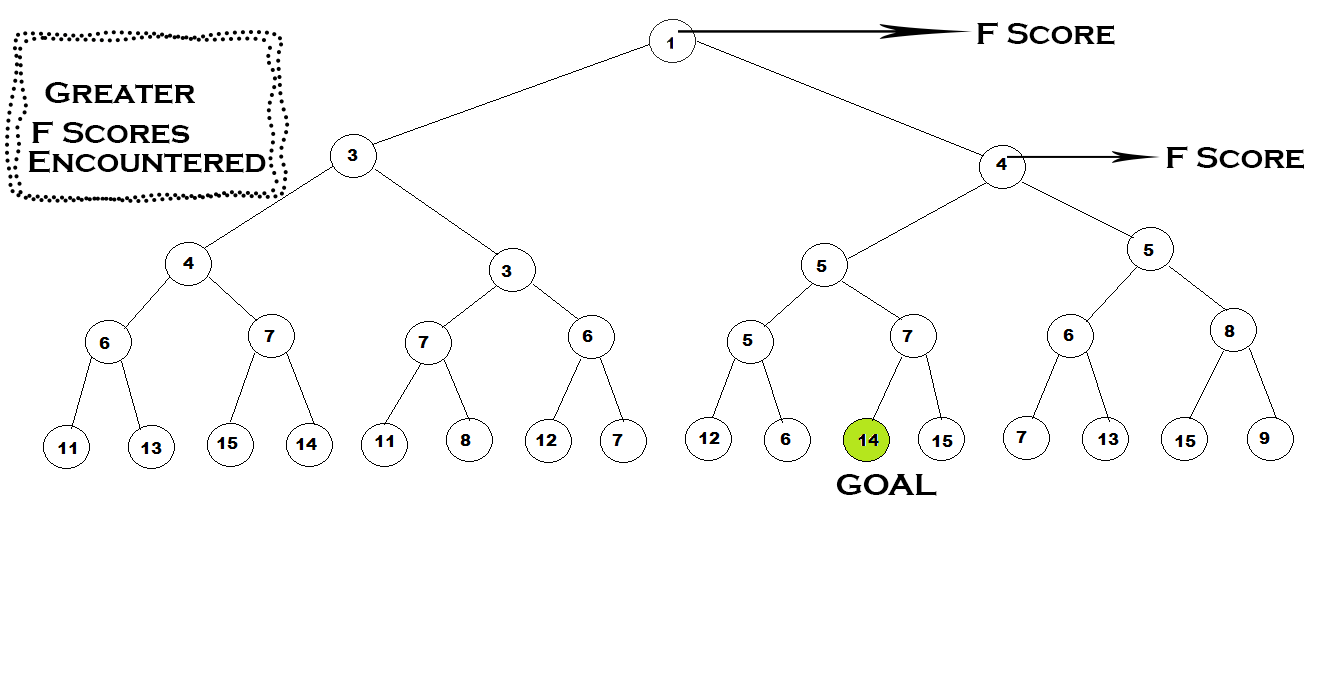
최적 경로를 찾을 때까지 반복적으로 경로를 탐색하며 현재 경로 비용과 예상 경로 비용이 임계값인 '바운드'를 초과하지 않도록 탐색한다. 이 바운드 값은 각 반복마다 업데이트된다.
IDA⁕ 알고리즘은 DFS를 기반으로 휴리스틱 함수를 사용하며 최적 경로를 탐색한다.
하이브리드 경로탐색 알고리즘
논문에서는 최단 거리 경로탐색 알고리즘인 다익스트라 알고리즘과 A⁕ 알고리즘을 결합한 탐색 알고리즘을 제시한다. 두 알고리즘을 결합하여 사용하기 위해 논문에서는 Level이라는 새로운 파라미터를 정의한다. Level은 검색 시작지점으로부터 얼마나 떨어진 노드인지를 나타낸다
(시작지점 노드에 가장 이웃한 노드는 Level-1(이하 L1), 다음은 L2 ...)
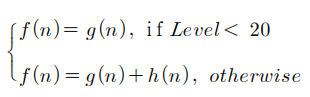
해당 level에 따라 알고리즘의 적합도 f(n)을 위와 같이 나타낸다. 최대 Level을 만족하기 전까지는 다익스트라 알고리즘을 이용해 최단거리 경로를 탐색하다가 최대 level이 되는 경우에만 A⁕ 알고리즘으로 전환하는 방식으로 진행된다. 위 적합도 식에서 임계값이 되는 Level 값은 사용자 설정에 따라 변경 가능하다.
즉, level 값이 증가할수록 다익스트라 알고리즘에서 open list의 크기가 증가할 때 A⁕ 알고리즘을 적용해 이를 억제시킨다는 것이다. 이 때 다익스트라 알고리즘의 open list는 A⁕ 알고리즘의 open list와는 서로 다른 리스트이다. 알고리즘 동작에 대해 자세히 살펴보자.
동작 과정
[초기화 과정]
1. 다익스트라와 A⁕ 알고리즘을 위한 각각의 open list D0, A0을 생성한다. 두 알고리즘 공용의 close list CLOSE도 생성한다. D0는 A0보다 level 값을 더 저장할 수 있다.
2. 시작지점 노드를 P라고 할 때, P를 D0에 추가한다. (초기 D0에는 P만 존재하며 level=0인 상태)
[다익스트라 탐색 과정]
1. P 노드에 이웃한 노드 n을 찾아 n이 D0 or CLOSE에 존재하지 않을 경우 D0에 n을 추가하고 n.level += 1로 갱신한다.
2. D0에서 최소 평가도 값을 갖는 노드 m을 CLOSE에 추가한다.
3. m이 목적지점 노드라면 성공종료, D0가 empty list라면 실패종료한다.
4. m.level이 설정된 임계 Level보다 작으면 [다익스트라 탐색 과정]으로, 크다면 다음 [A* 탐색 과정]으로
[A⁕ 탐색 과정]
1. A0를 (A0 Union D0) 으로 통합한 뒤 A0의 모든 평가도를 다음과 같이 갱신한다.
2. A0에서 최소 평가도 값을 갖는 노드 K라고 할 때, K.level = 0으로 설정, K를 CLOSE에 추가한다.
3. D0을 empty list로 초기화하고 [다익스트라 탐색 과정]으로
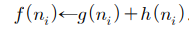
다익스트라 알고리즘과 A⁕ 알고리즘 각각 시작 노드로부터 최단 경로를 탐색하기 위해 자체적인 open list를 유지하며, 최소 평가도를 갖는 노드를 선택해 공용의 close list에 추가하며 탐색을 진행한다. 마지막 과정에서 A0 리스트와 D0 리스트를 합쳐 평가도를 갱신함으로써 다음 노드를 효율적으로 선택할 수 있게 된다.
Results
논문에서 제시한 하이브리드 알고리즘의 최단경로 탐색에 대해 1. 인공지도와 2. 실제 지도 데이터를 기반으로 컴퓨터 시뮬레이션한 결과를 통해 level값에 따른 연산비용과 측정 결과를 나타내었다.
1. 인공지도
인공지도를 이용한 시뮬레이션은 40 by 40로 최대 1600개의 노드를 표기할 수 있는 지도를 기반으로 한다. 각 노드 간 거리는 모두 1로 가정한다. Level에 따른 적합도 결과를 비교하기 위해 L1, L4, L10으로 나누어 비교하며 노드 S에서 시작해 노드 E에 도달하는 것을 목적으로 한다. 이 때 최단거리 경로는 분홍색 경로, 경로탐색을 위해 방문한 경로는 검은색 경로로 표시하였다.
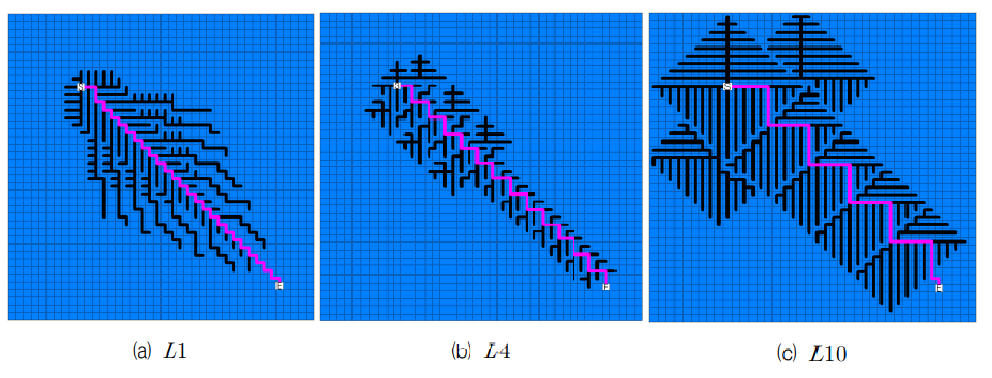
L1에서는 다익스트라 알고리즘을 적용하지 않고 A⁕ 알고리즘만으로 경로 탐색을 수행하였다. 따라서 탐색 공간은 기존 A⁕ 알고리즘과 동일한 결과를 보인다.
L4의 경로탐색 결과와 탐색공간을 보면 S에서 3번째 이웃노드까지만 다익스트라 알고리즘으로 탐색한 후 A⁕ 알고리즘으로 전환하였다. 이후 A⁕ 알고리즘에서 노드들의 적합도를 평가하여 다시 다익스트라 알고리즘으로 경로를 탐색한 것을 확인할 수 있다.
L10의 경우 S에서 9번째 이웃 노드가 찾아질 때까지 다익스트라 알고리즘을 적용한 뒤 A⁕로 전환되었다.
결과를 종합해보면 Level 값에 따라 탐색공간의 차이가 있었다. L1보다 L10의 경우 더 많은 경로를 탐색하였으며 이에 따라 최단 경로를 찾을 수 있는 가능성이 높아진다고 볼 수 있다.
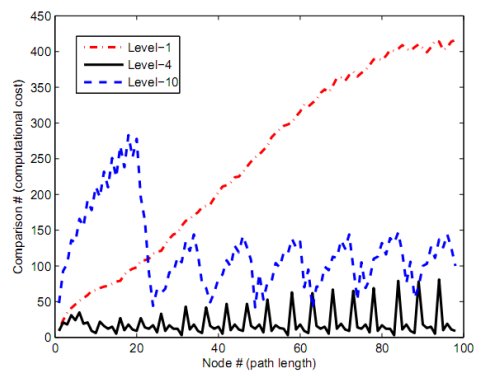
위는 L1, L4, L10 탐색별 open list에서 경로 길이에 따른 최적 적합도에 해당하는 노드를 선정하기 위해 수행한 비교 횟수를 나타낸다. 탐색 경로길이가 길어질수록 L10보다 L1에서 더많은 비용을 확인할 수 있다. 경로길이>20 부분에서 경로길이가 증가함에 따라 연산비용은 큰 폭으로 차이가 나게 된다.
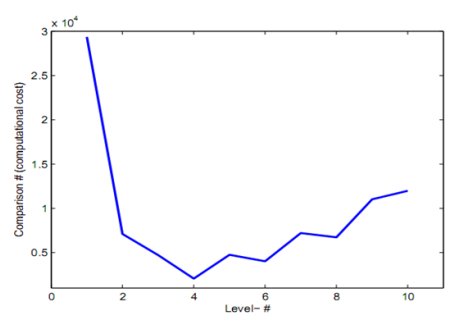
Level 값에 따른 누적 연산비용 비교 그래프이다. 연산비용 관점에서 차이가 크기 때문에 경로탐색하려는 시작지점과 목적지점 간에 따른 적합한 level을 설정하는 것이 중요하다.
2. 실제 지도
ITS의 전자도로망 지도 데이터를 이용해 실제 지도를 기반한 시뮬레이션을 진행한 결과로, level을 L16, L32, L64로 나누어 실험하였다. 또한 알고리즘 간 차이를 비교하기 위해 다익스트라, A⁕, LRTA⁕, 하이브리드 알고리즘을 함께 비교하였다.
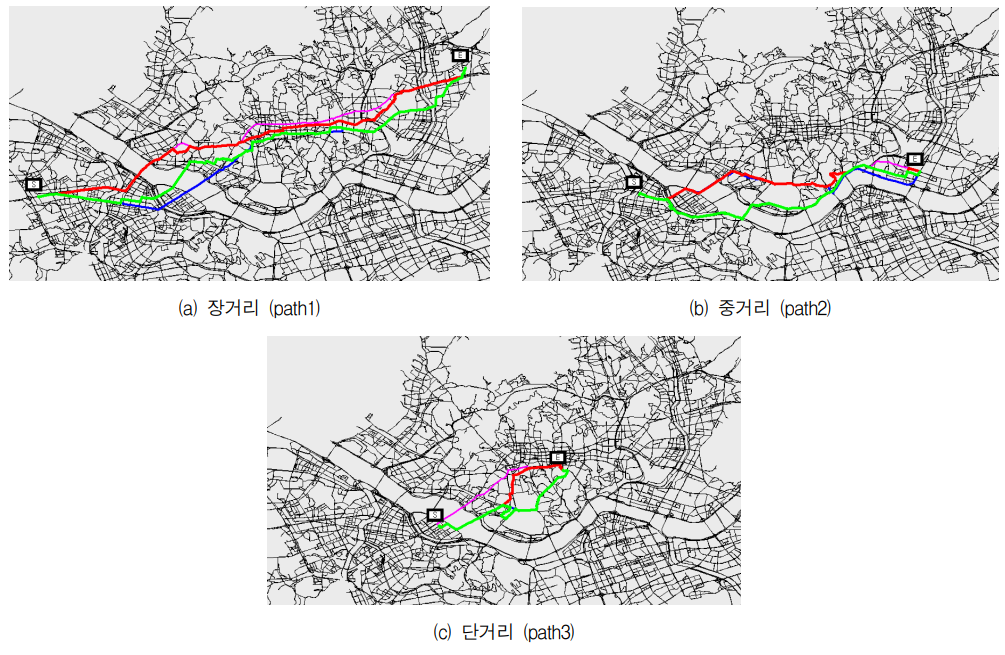
서울 지도를 기반으로 장거리, 중거리, 단거리 경로탐색에 있어 다익스트라, A⁕, LRTA⁕ 알고리즘을 적용한 경로 결과이다. 분홍색 경로가 다익스트라, 파란색은 A⁕, 초록색은 LRTA⁕, 빨간색은 제안하는 하이브리드 알고리즘이다.
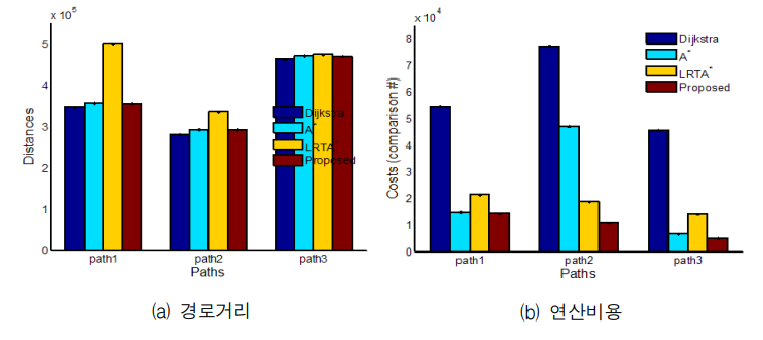
알고리즘별 탐색경로에 대한 경로거리와 연산비용을 비교한 결과는 다음과 같다. path1, path2 경우 LRTA⁕의 경로거리가 다른 알고리즘보다 다소 길지만 path3의 경우 모든 알고리즘의 경로거리가 비슷하였다. 하지만 경로탐색에 수행된 연산비용은 path1, path2, path3 모든 경우에 대해 제안된 하이브리드 알고리즘이 다른 알고리즘에 비교해 낮음을 확인할 수 있었다.
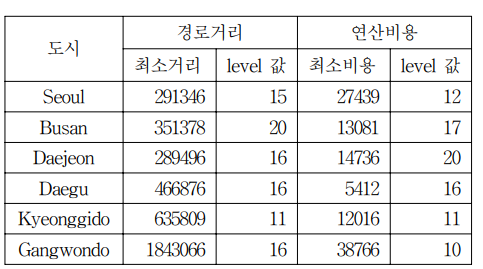
각 실제도시 맵에 대한 경로거리 및 연산비용을 고려해 선정된 최적의 level을 정리한 표로, 실험 결과 하이브리드 알고리즘의 성능이 Level 값에 민감함을 보였다. 따라서 주어진 도로환경의 최적의 Level 값을 선정하는 것이 관건이기 때문에 별도 학습과 같은 과정을 통해 최적 Level을 찾아내는 것이 중요하다.
Conclusion
최단경로 탐색을 위해 다양한 환경에서 작동하는 많은 알고리즘이 존재한다. 하지만 탐색하려는 거리가 긴 경우, 경로탐색을 위한 비교연산의 횟수가 급격히 증가한다는 문제가 생긴다. 이를 해결하기 위해 완전탐색 알고리즘인 다익스트라 알고리즘을 기본 탐색방식으로 채택하며, 선택적 알고리즘인 A⁕ 알고리즘의 기법을 활용하는 하이브리드 알고리즘을 제안하였다.
다익스트라 알고리즘과 A⁕ 알고리즘이 각각 별도의 open list를 사용하며 open list의 급격한 증가를 방지하여 연산비용을 줄일 수 있다. 또한 다익스트라 알고리즘으로 최단 경로를 탐색하기 때문에 A⁕ 알고리즘만으로 찾을 수 없었던 경로도 고려할 수 있도록 하였다.
본 하이브리드 알고리즘을 검증하기 위해 인공지도와 실제지도를 통해 각 알고리즘별 경로거리와 연산비용을 비교분석하였고 그 결과 연산비용에 있어 이점을 갖는다는 것을 확인하였다. 하지만 하이브리드 알고리즘은 Level이 증가할수록 다익스트라 알고리즘에 근접하고, 작아질수록 A⁕ 알고리즘에 근접하게 되는 특징을 갖기 때문에 목적으로 하는 경로탐색의 지역 특성에 따른 최적의 Level을 결정할 수 있는 추가적인 학습 및 알고리즘 연구가 필요하다.
