Redis란 캐시 저장소로만 알고 있었지만 더 다양한 기능을 많이 지원하는 NoSQL 이라는 것을
알게 되었고 프로젝트에 적용하려고하니 한 번 정리를 하고 적용하기 위해 정리를 하기로 했다.
Redis를 알기전에 NoSQL에 대해서 먼저 알고가야한다.
NoSQL이란?
- Not Only SQL 또는 Non-Relational Operational DataBase의 약자로 비관계형 데이터베이스이다.
- 관계형 데이터베이스와 달리 테이블 스키마가 없으며, key-value, 문서, 열 패밀리, 그래프 등 다양한 데이터 모델을 지원한다.
- 대규모 데이터를 처리할 때 높은 성능을 제공하며, 캐시, 세션 저장소, 로그 저장소 등에서 자주 사용된다.
- 대표적인 NoSQL은 MongoDB, Redis, Cassandra, Elasticsearch 등이 있다.
Redis란?
Redis(Remote Dictionary Server)는 오픈 소스 인메모리 데이터 구조 저장소로, 키-값(key-value) 데이터베이스입니다. Redis는 다양한 데이터 구조를 지원하며, 주로 캐시, 메시지 브로커, 세션 저장소 등으로 사용됩니다.
- 인메모리 데이터 저장소 : 모든 데이터를 메모리에 저장하고 처리하여 매우 빠른 읽기 및 쓰기 속도를 제공, 이는 디스크 기반 데이터베이스에 비해 훨씬 빠른 접근 속도를 의미한다.
- 다양한 데이터 구조 지원 : 문자열, 리스트, 셋, 해시, 비트맵, 하이퍼로그로그, 지리 공간 인덱스 등 여러 데이터 타입을 지원
- 영속성 : Redis는 메모리 내 데이터 외에도 RDB(Redis DataBase) 스냅샷과 AOF(Append-Only File) 방식을 통해 디스크에 데이터를 저장할 수 있어 영속성을 보장한다.
다양한 데이터 타입
String
- 가장 기본적인 타입으로 제일 많이 사용한다.
- 최대 크기는 512MB, 바이트 배열로 저장
- 바이너리로 변환할 수 있는 모든 데이터를 저장 가능하다. (JPG)
바이너리 : 정보를 이진 형태로 저장, 모든 문자를 표현 가능, 주로 캐시 같은 것들을 많이 표현한다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| SET | 특정 키에 문자열 값을 저장. | SET name kim |
| GET | 특정 키의 문자열 값을 얻는다. | GET name |
| INCR | 특정 키의 값을 Integer 취급해 1 증가. | INCR mycount |
| DECR | 특정 키의 값을 Integer 취급해 1 감소. | DECR mycount |
| MSET | 여러 키의 값을 한번에 저장. | MSET pizza domino chicken bbq |
| MGET | 여러 키의 값을 한번에 얻는다. | MGET pizza chicken |
Lists
Linked-list 형태의 자료구조로 인덱스 접근은 느리지만, 데이터 추가/삭제가 빠르다.
데이터들이 포인터로 연결되어있고, Queue와 Stack으로 사용할 수 있다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| LPUSH | 리스트의 왼쪽 head에 새 값 추가 | LPUSH fruit apple |
| RPUSH | 리스트의 오른쪽 tail에 새 값 추가 | RPUSH fruit banana |
| LLEN | 리스트에 들어있는 아이템 개수 반환 | LLEN fruit |
| LRANGE | 리스트 특정 범위 반환 | LRANGE 0-1 |
| LPOP | 리스트의 왼쪽 head에 값 삭제하고 반환 | LPOP fruit |
| RPOP | 리스트의 오른쪽 tail에 값 삭제하고 반환 | RPOP fruit |
Sets
순서가 없는 유니크한 값의 집합으로 검색이 빠르다. 인덱스가 존재하지 않고, 집합 연산(합집합, 교집합)이 가능하다.
대표적인 사용 예시로 웹 페이지에서 유효한 쿠폰 발급이다. 그 쿠폰을 발급받았는지 알아야 할 때, SET으로 그걸 확인 가능하다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| SADD | SET에 데이터 추가 | SADD fruit apple |
| SREM | SET에 데이터 삭제 | SREM fruit apple |
| SCARD | SET에 저장된 아이템 개수 반환 | SCARD fruit |
| SMEMBERS | SET에 저장된 아이템들을 반환 | SMEMBERS fruit |
| SISMEMBER | 특정 값이 SET에 포함되어 있는지 반환 | SISMEMBER fruit apple |
Hashes
하나의 key 하위에 여러 개의 field-value 쌍을 저장하는 구조, 여러 필드를 가진 오브젝트를 저장하는 것으로 볼 수 있다.
대표적인 예시로 HINCRBY 명령어로 카운터로써 활용이 가능하다. 방문수, 클릭수, 유저에 관한 측정 숫자 등에 활용된다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| HSET | 한 개 또는 다수의 필드 값 저장 | HSET user name jung age 30 |
| HGET | 특정 필드의 값을 반환 | HGET user name |
| HMGET | 한 개 이상의 필드 값 반환 | HMGET user name age |
| HINCRBY | 특정 필드 값을 Integer로 취급해 지정 숫자 증가 | HINCRBY user viewcount 1 |
| HDEL | 한 개 이상의 필드를 삭제 | HDEL user name age |
Sorted sets
Set과 유사하게 유티크한 값의 집합이다. 각 값은 연관된 score를 가지고 정렬한다.
정렬된 상태기 때문에 빠르게 최소/최대 값을 구하는게 가능하다.
보통 순위 계산이나 리더보드에 사용된다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| ZADD | 한 개 또는 다수의 값을 추가 및 업데이트. | ZADD ranking 10 apple 20 banana |
| ZRANGE | 특정 범위 값을 반환. (오름차순 기준) | ZRANGE ranking 0 1 |
| ZRANK | 특정 값의 위치를 반환. (오름차순 기준) | ZRANK myrank apple |
| ZREVRANK | 특정 값의 위치를 반환. (내림차순 기준) | ZREVRANK ranking apple |
| ZREM | 한 개 이상의 값을 삭제. | ZREM ranking apple |
Bitmaps
0과 1로 이루어진 긴 벡터로 공간 효율적으로 저장, 비트 벡터를 사용해 N개의 Set을 공간 효율적으로 저장한다.
비트 연산이 가능하고, 오프셋을 사용, 방문현황을 쓸 때 사용한다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| SETBIT | 비트맵의 특정 오프셋에 값을 변경. | SETBIT visit 10 1 |
| GETBIT | 비트맵의 특정 오프셋에 값을 반환. | GETBIT visit 10 |
| BITCOUNT | 비트맵에서 set(1) 상태인 비트의 개수를 반환. | BITCOUNT visit |
| BITOP | 비트맵들간의 비트 연산을 수행하고, 결과 비트맵 저장. | BITOP AND result today yesterday |
HyperLogLog
유니크한 값의 개수를 효율적으로 얻을 수 있다. 확률적 자료구조라서 오차가 있고, 매우 큰 데이터를 다룰 때 사용한다.
HyperLogLog는 내부에 데이터를 저장하지 않는다.
| 명령어 | 기능 | 예제 |
|---|---|---|
| PEADD | HyperLogLog에 값들을 추가한다. | PEADD visit Kim Park Son |
| PFCOUNT | HyperLogLog에 입력된 값들의 유일한 수를 반환 | PFCOUNT visit |
| PFMERGE | 다수의 HyperLogLog를 병합 | PFMERGE result visit1 visit2 |
캐시 전략
- cache hit : 캐시 스토어(redis)에 데이터가 있을 경우 바로 가져옴 (빠름)
- cache miss : 캐시 스토어(redis)에 데이터가 없을 경우 DB에서 가져옴 (상대적으로 느림)
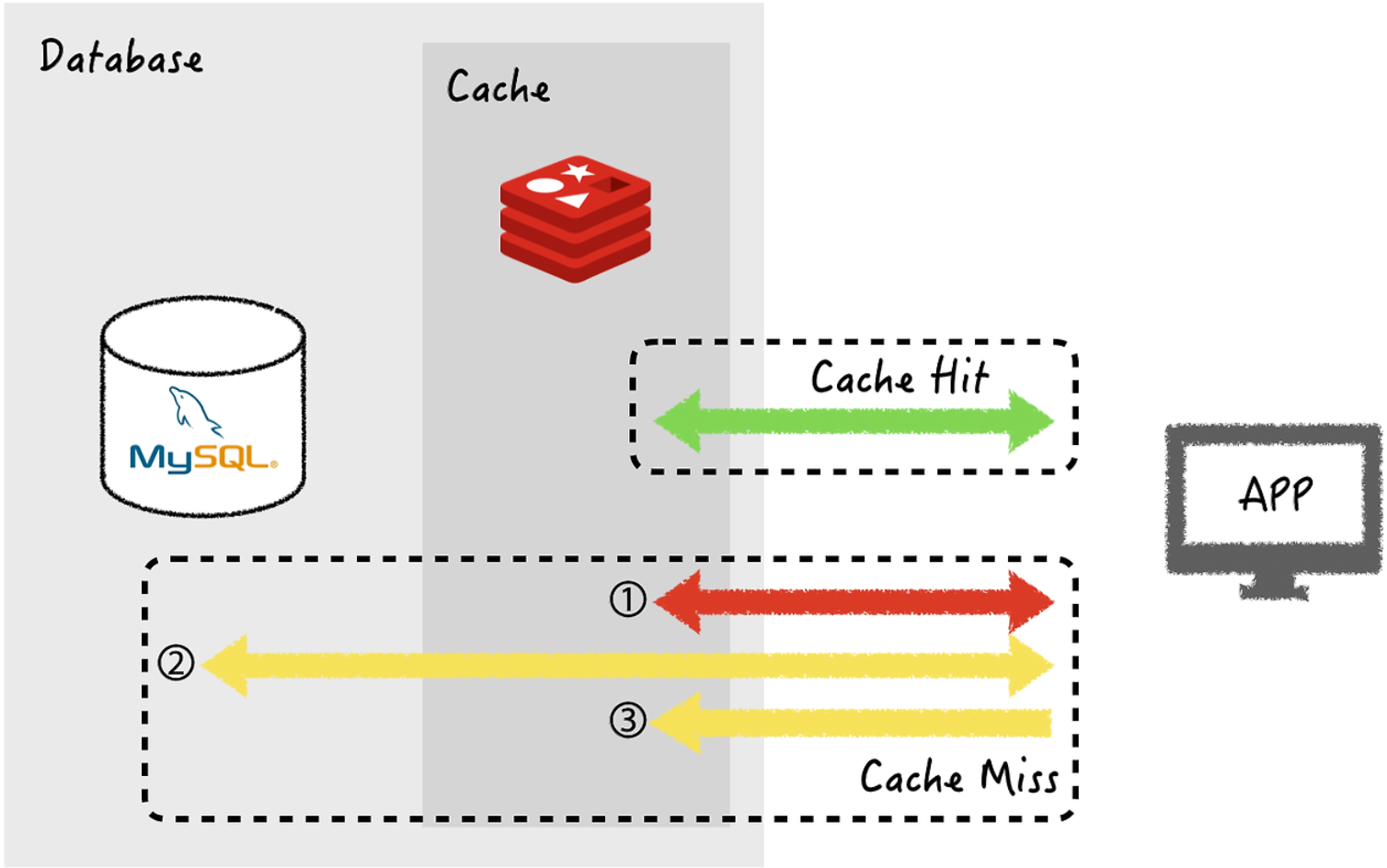
캐시 전략 패턴 종류
캐시를 이용하게 되면 반드시 닥쳐오는 문제점이 있는데 바로 데이터 정합성 문제이다.
데이터 정합성이란, 어느 한 데이터가 캐시(Cache Store)와 데이터베이스(Data Store)이
두 곳에서 같은 데이터임에도 불구하고 데이터 정보값이 서로 다른 현상을 말한다.
쉽게 말하면, 캐시에는 어떤 게시글의 좋아요 갯수가 10개로 저장되어 있는데
데이터베이스에는 7개로 저장되어있을 경우 정보 불일치가 발생하게 된다.
이전에는 그냥 DB에서 데이터 조회와 작성을 처리하였기 때문에 데이터 정합성 문제가 나타나지 않았지만,
캐시라는 또다른 데이터 저장소를 이용하기 때문에,
결국 같은 종류의 데이터라도 두 저장소에서 저장된 값이 서로 다를수 있는 현상이 일어날수 밖에 없는 것이다.
따라서 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Strategy)을 통해,
캐시와 DB간의 데이터 불일치 문제를 극복하면서도 빠른 성능을 잃지 않게 하기 위해 고심히 연구를 할 필요가 있다.
읽기 전략 (Read Strategies)
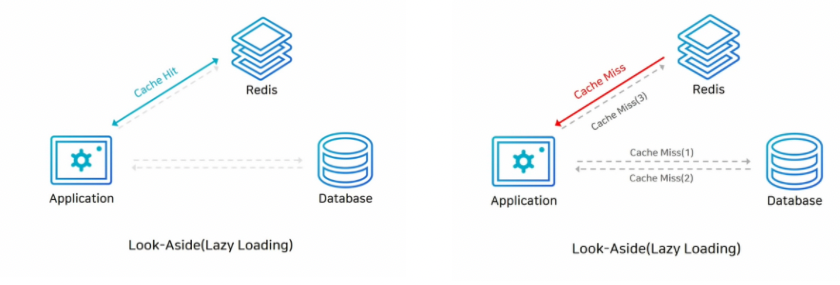
Look-aside (Lazy Loading) 전략 : 데이터를 읽는 작업이 많을 때 사용하는 전략이며, Redis를 캐시로 쓸 때 가장 많이 사용하는 전략이다.
먼저 애플리케이션이 데이터를 읽을때, 캐시를 확인하여 캐시에 데이터가 존재하면 캐시에서 데이터를 읽어온다.
만약 레디스에 찾는 데이터가 없다면 DB에 접근해서 데이터를 직접 가져와 레디스에 저장한다.
따라서, 캐시에는 찾는 데이터가 없을 때만 데이터가 캐싱되기 때문에 이를 지연로딩(Lazy Loading)이라고도 부른다.
이 구조는 레디스 장애 발생 시 시스템이 다운되지 않고, DB에서 데이터를 가지고 올 수 있다.
대신 캐시로 붙어있던 커넥션이 많이 있었다면 그 커넥션이 모두 데이터베이스로 붙기 때문에 DB에 많은 트래픽이 한꺼번에 몰릴 수 있다.
그래서 이런 경우에 캐시를 새로 투입하거나, DB에만 새로운 데이터를 저장했다면 캐시에 데이터가 없기 때문에 처음에 Cache miss가 지속적으로 발생해서 DB에 성능에 저하가 올 수 있다.
이럴 때에는 미리 DB에서 캐시로 데이터를 밀어 넣어주는 작업을 할 수 있는데. 이를 cache warming이라고 한다.
쓰기 전략 (Writing Strategies)
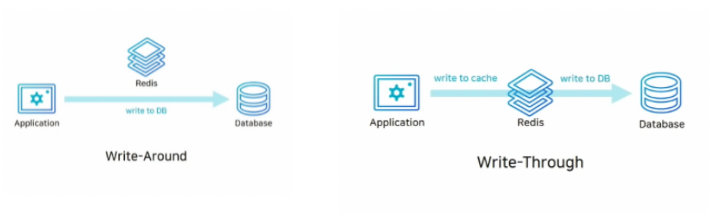
Write-around : DB에 데이터를 저장하고 Cache miss가 발생할 경우 DB에서 데이터를 캐싱한다.
이 경우엔 cache 내의 데이터와 DB 내의 데이터가 다를 수 있다.
왜냐하면, 캐싱된 데이터가 있을 경우 데이터를 수정할때 캐싱된 데이터를 수정하지 않고,
캐시에 데이터는 있기 때문에 새로 캐싱을 하지 않는다.
Write-through : DB에 데이터를 저장할 때 cache에도 함께 저장하는 방법이다.
cache는 항상 최신 정보를 가지고 있다는 장점이 있지만 저장할 때마다 두 단계(DB에 저장, 캐시에 저장) 거쳐야 하기 때문에 상대적으로 느리다.
그리고 재사용되지 않는 데이터도 무조건 캐시에 넣어버리기 때문에 일종의 리소스 낭비를 초래 할 수 있다.
이 경우 데이터를 저장할 때는 Expire time을 설정해주는 것이 좋다고 한다.
