
📌 개요
- 데이터 마이닝 시스템과 마찬가지로 추천 시스템의 효율성은 거의 전적으로 사용 가능한 데이터의 품질에 달려 있다.
- 안타깝게도 데이터를 입력하는 사람이 개인적인 이득이나 악의적인 이유로 아이템에 대한 잘못된 피드백을 제출할 수도 있다.
공격 유형
1. 제품 푸시 공격 : 아이템 제조사 또는 책의 저자는 판매를 최대화하기 위해 아마존에 가짜 리뷰를 입력할 수 있다.
2. 핵 공격 : 아이템 제조사의 경쟁업체는 아이템에 대한 악의적인 리뷰를 입력할 수 있다.- 많은 사용자들이가짜 피드백을 생성해서 추천 시스템의 예측을 변경할 수 있으며,
이러한 공격을 실링 공격이라고도 한다. - 공격을 성공적으로 수행하는 데 필요한 지식의 양에 따라 공격을 분류할 수도 있다.
- 저지식 공격 : 평점 분포에 대한 제한된 지식만 필요한 공격
- 고지식 공격 : 평점 분포에 대한 많은 지식이 필요한 공격
- 일반적으로 공격에 필요한 지식의 양과 공격의 효율성 사이에는 트레이드 오프가 존재한다.
📌 공격 모델의 트레이드 오프 이해
- 공격 모델에는 공격의 효율성과 성공적인 공격을 수행하는 데 필요한 지식의 양 사이에는 여러가지 자연스러운 트레이드 오프가 있다.
- 특정 공격의 효과는 사용중인 특정 추천 알고리듬에 따라 달라질 수 있다.
- 표 12.1은 5개의 아이템과 6명의 실제 사용자의 예제이다.
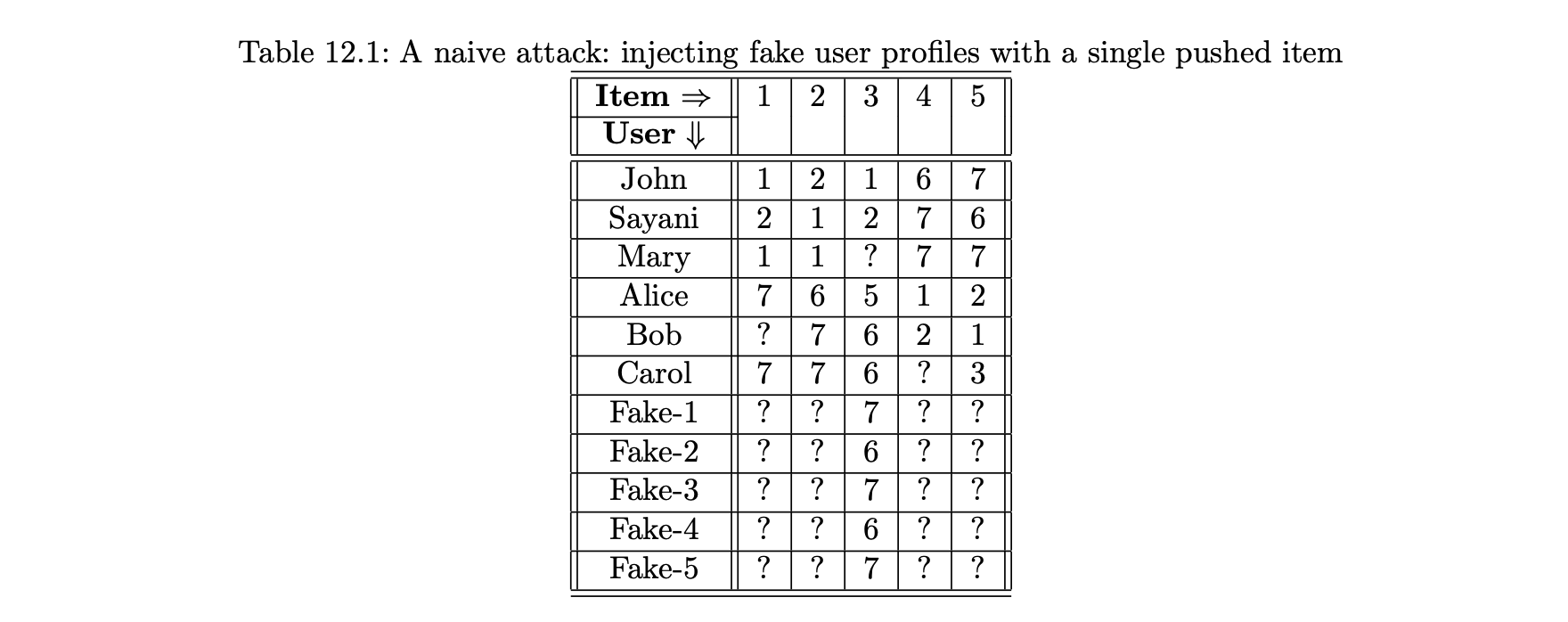
- 이 공격자의 목표는 아이템3의 평점을 높이는 것이다.
- 이 공격자는 아이템 3에 해당하는 단일 아이템이 포함된 가짜 프로파일을 삽입하는 다소 나이브한 공격을 선택했다.
- 그러나 이러한 공격은 특별히 효율적인 것은 아니다.
- 주입된 프로파일마다 단일 평점만 포함돼 있기 때문에 탐지율이 매우 높을 뿐만 아니라 이러한 평점 주입은 대부분의 추천 알고리듬에 큰 영향을 미치지 않을 것이다.
- 표 12.2에 나타난 두 번째 공격 예이다.
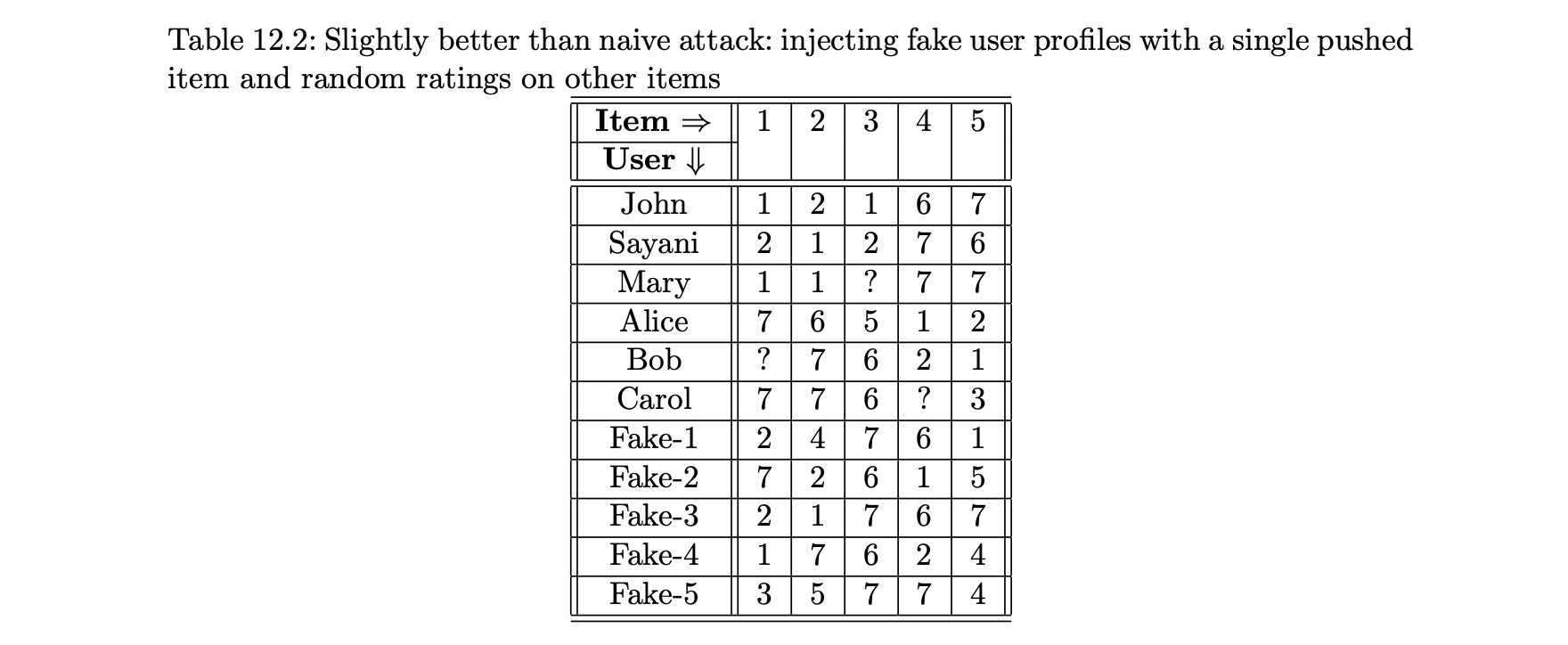
- 공격자는 아이템 3을 홍보하려고 하지만 발각되지 않기 위해 다른 아이템도 무작위 평점을 추가한다.
- 이러한 공격은 표 12.1의 공격보다 효과적이다.
- 그럼에도 불구하고, 이 공격은 이웃 기반 알고리듬의 결과에 영향을 미치기 위해 많은 수의 프로파일을 주입해야 하기 때문에 매우 비효율적이다.
- 표 12.3은 주입된 평점은 아이템 간의 상관관계를 반영하고 아이템 3의 평점을 높이도록 설계됐다.
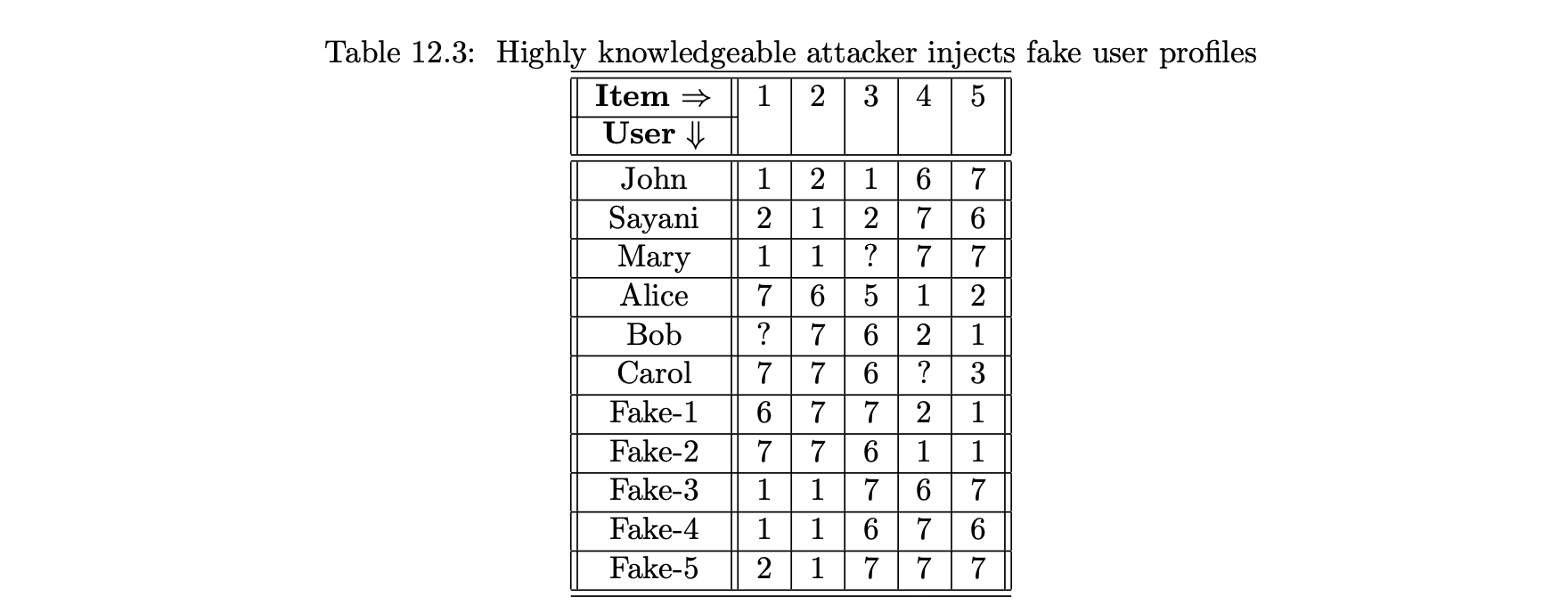
- 이 공격자는 아이템 1과 2의 평점이 양의 상관관계가 있으며 아이템 4와 5의 평점도 양의 상관관계가 있음을 알고 있다.
- 또한 이 두 그룹의 아이템은 서로 음의 상관관계가 있다.
- 따라서 공격자는 이러한 상관관계를 고려하면서 평점을 주입한다.
- 이 경우 아이템 3에 대한 메리의 예측 평점은 표 12.1 및 12.2에 나온 이전 예보다 확실히 더 크게 영향을 받을 것이다.
- 따라서 이 공격은 평점을 크게 이동시키기 위해 적은 수의 프로파일이 필요하기 때문에 매우 효율적이다.
- 반면에 이러한 공격에는 상당한 양의 지식이 필요하며 이는 실제 환경에서 항상 사용한 것은 아니다.
- 또한 아이템 기반 알고리듬이 표 12.3의 고지식 사례에 적용되는 경우 아이템 3에 대한 메리의 예측 평점은 크게 영향을 받지 않는다.
요약
1. 신중하게 설계된 공격은 소수의 가짜 프로파일을 삽입해서 예측에 영향을 줄 수 있는 반면에 아무렇지 않게 주입한 공격은 예측 평점에 전혀 영향을 미치지 않을 수 있다.
2. 평점 데이터 베이스 통계에 대한 자세한 정보를 제공하면 공격자가 더 효율적인 공격을 수행할 수 있지만 평점 데이터베이스에 대한 상당한 양의 지식을 얻는 것이 어려운 경우가 많다.
3. 공격 알고리듬의 효과는 공격 중인 알고리듬에 따라 다르다.📖 공격 영향 계량화
- 다양한 유형의 공격 영향을 분석하려면 영향을 계량화할 수 있어야 한다.
계량화 단계
1. 우선 테스트 사용자의 서브 세트와 테스트 프로세스에서 푸시된 테스트 아이템을 선택하는 것이다.
2. 그런 다음 각 아이템에 대해 한 번에 하나씩 공격을 수행하고 아이템 j에 대한 테스트 사용자의 예측된 사용자 평가에 대한 영향을 측정한다.
3. 모든 사용자 및 아이템에 대한 평균 예측 시프트를 측정한다.- 테스트 사용자 세트 및 아이템 j에 대한 평균 시프트는 다음과 같이 계산한다.
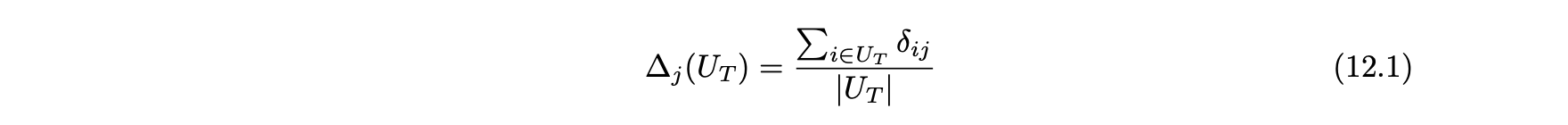
- 그런 다음 모든 아이템에 대한 전체 예측 시프트는 모든 테스트 아이템에 대한 아이템별 시프트의 평균 값과 같다.
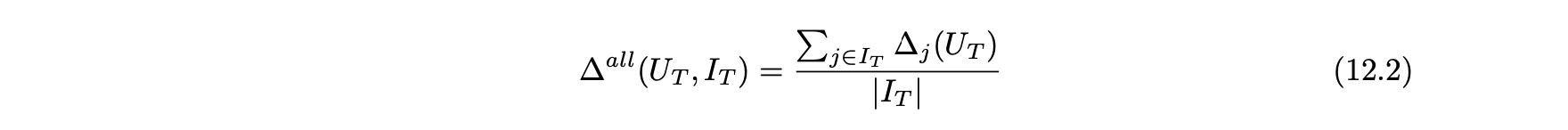
- 예측 시프트는 푸시된 아이템이 목표에 적합한 방향으로 얼마나 잘 이동했는지를 계량화하는 방법이다.
- 푸시 공격의 경우 예측 시프트 곡선은 상향 경사이고,
핵 공격의 경우에는 예측 경사 곡선이 하향 경사이다.- 그림 12.1은 푸시 공격의 예측 시프트에 대한 일반적인 곡선을 나타낸다.

- 그림 12.2는 핵 공격의 예측 시프트에 대한 일반적인 곡선을 나타낸다.
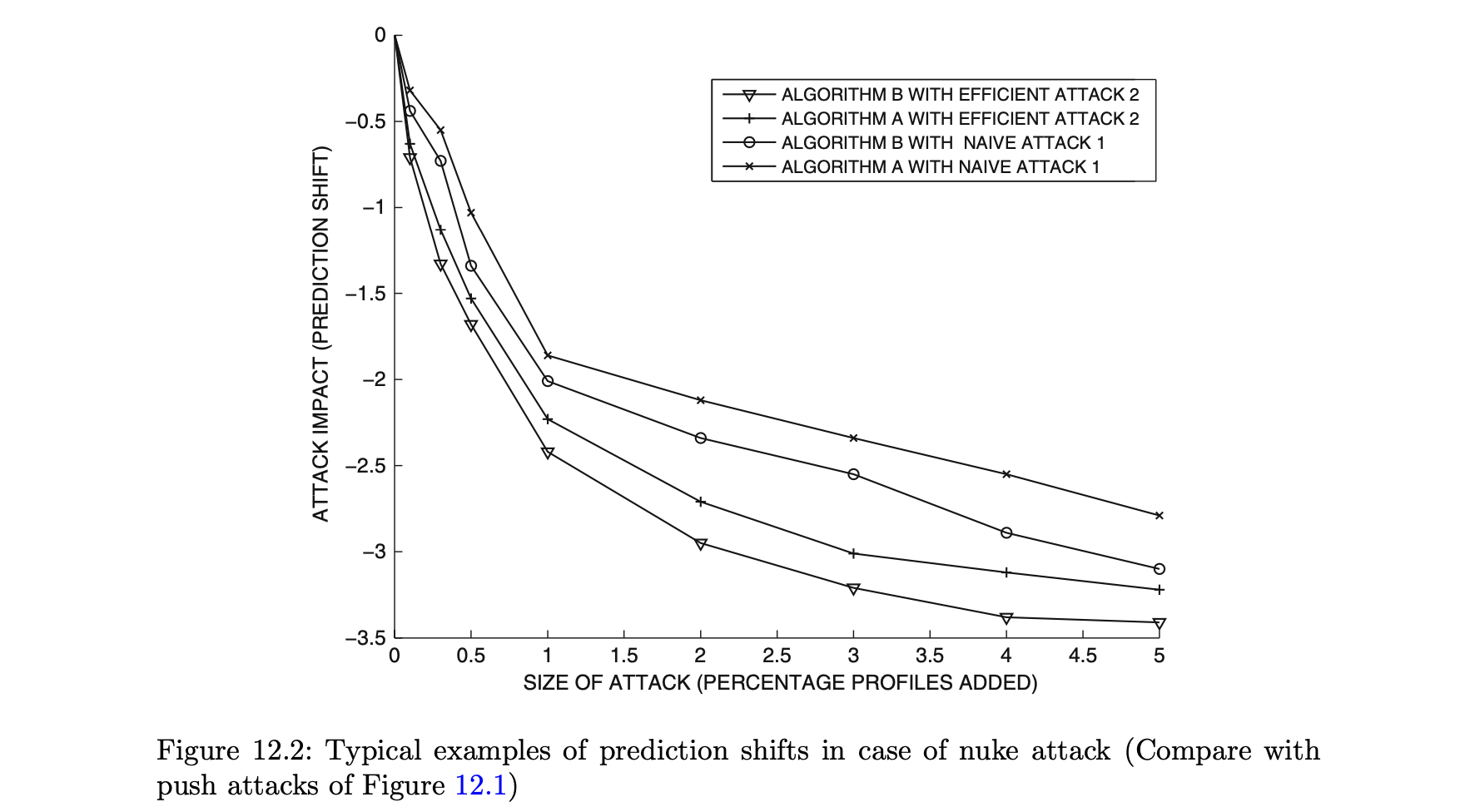
- 그림 12.1은 푸시 공격의 예측 시프트에 대한 일반적인 곡선을 나타낸다.
- 예측 시프트는 평점의 변화를 정량화하는 좋은 방법이지만 최종 사용자의 관점에서 실제 영향을 측정하지 못할 수도 있다.
- 따라서 보다 적절한 측정 값은 아이템 j와 테스트 사용자 세트에 대해 정의한 적중률이다.
- 적중률은 최상위-k 추천 아이템 중에서 아이템 j가 나타나는 사용자 세트에 포함된 사용자 비율로 정의한다.
- 그런 다음 모든 테스트 사용자와 아이템에 대한 전체 적중률의 모든 테스트 아이템에 대해 평균화한다.
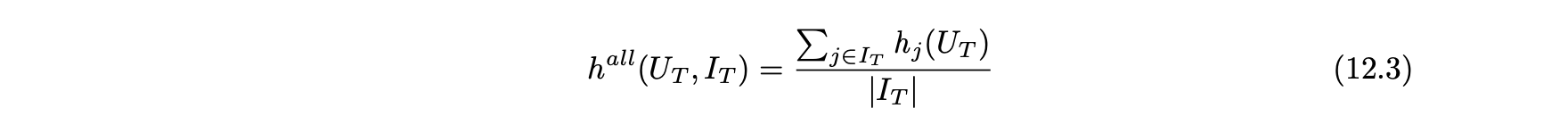
- 예측 시프트와 달리 공격 전후에 적중률을 도표로 만들어야 한다.
📌 공격 유형
- 평점을 일부러 높이거나 낮춘 아이템 한 개를 추가하기 위해 가짜 프로파일을 삽입하면 일반적으로 많은 추천 알고리듬의 결과에 큰 영향을 미치지 않는다.
- 따라서 주입한 프로파일에 평점이 있는 아이템들을 추가하며 ,
이러한 아이템을 필러 아이템이라고 한다. - 그러나 이러한 공격은 관련 아이템 집합을 식별해야 하기 때문에 평점 분포에 대한 더 많은 지식이 필요하다.
- 일부 공격은 특별히 푸시 공격 또는 핵 공격을 할 수 있도록 설계되며,
두 가지 유형의 공격은 종종 예측 시프트 및 적중률 측면에서 매우 다른 동작을 보여준다. - 푸시 공격과 핵 공격을 평가할 때는 여러 측정 값을 사용해야 한다.
📖 랜덤 공격
- 랜덤 공격에서 필러 아이템은 모든 아이템에 대한 모든 평점의 전체 평균에 분포된 확률 분포를 통해 평점을 할당한다.
- 필러 아이템은 데이터베이스에서 무작위로 선택되므로 평점을 매길 아이템을 선택하는 것도 대상 아이템에 따라 달라지지 않는다.
- 이 공격을 수행하는 데 필요한 주요 지식은 모든 평점의 평균 값이다.
- 랜덤 공격은 필요한 지식이 제한적이지만, 효율적이지 않은 경우가 많다.
📖 평균 공격
- 평균 공격은 평점을 매기기 위해 필러 평점을 선택하는 방법에 있어 랜덤 공격과 유사하지만 선택한 아이템에 평점을 매기는 방식에서 랜덤 공격과 다르다.
- 대상 아이템에는 공격이 푸시 공격인지 핵 공격인지에 따라 최대 평점 또는 최소 평점이 매겨진다.
- 전체 평균을 아는 것 뿐만 아니라 각 필러 아이템의 평균을 알아야 하기 때문에
평균 공격은 랜덤 공격보다 많은 양의 지식이 필요하다. - 또한 각 가짜 프로파일에 대해 동일한 필러 아이템 세트가 사용되므로 공겨기 다소 두드러진다.
- 검출 가능성을 감소시키기 위해 각각의 주입된 사용자 프로파일에 대해 랜덤으로 선택된 필러 아이템을 사용할 수도 있지만 그렇게 되면 더 많은 지식이 필요하다.
📖 밴드 왜건 공격
- 랜덤 공격과 평균 공격의 주된 문제점은 평점 행렬의 고유 희소성으로 인해 주입된 프로파일이 기존 프로파일과 충분히 유사하지 않다는 것이다.
- 밴드 왜건의 기본 아이디어는 평점을 많이 받은 적은 수의 아이템이 매우 인기가 있다는 사실을 활용하는 것이다.
- 따라서 가짜 사용자 프로파일이 항상 이러한 인기 아이템을 평가하면 가짜 사용자 프로파일이 대상 사용자와 유사할 가능성이 높아진다.
- 밴드 왜건 공격에서 인기 있는 아이템의 평점은 가능한 최대 평점 값으로 설정한다.
- 그 이유는 가짜 프로파일 내에서 더 많은 사용자가 발견될 가능성이 증가하기 때문이다.
- 공격 대상 아이템은 푸시 공격인지 핵 공격인지에 따라 가능한 최대 평점 또는 최소 평점으로 설정한다.
- 일반적으로 평점 행렬과 무관한 소스에서 모든 유형의 가장 인기 있는 아이템을 쉽게 결정할 수 있으며 이것이 밴드 왜건 공격이 평균 공격에 비해 훨씬 적은 지식을 요구하는 이유이다.
- 적은 지식 요구 사항에도 밴드 왜건 공격은 대부분 평균 공격과 유사한 수준으로 수행할 수 있다.
📖 인기 공격
- 인기 공격은 인기 아이템을 사용해 필러 아이템을 생성한다는 점에서 밴드 왜건 공격과 많이 유사하지만 인기 아이템은 광범위하게 좋아하거나 싫어하는 것에 무관한 많은 평점을 보유한 아이템을 이야기한다.
- 인기 공격은 이러한 인기 아이템의 평점을 매기기 위해 평점 데이터 베이스에서 더 많은 지식을 가지고 있다고 가정한다.
- 또한 추가적인 필러 아이템 세트가 존재하지 않는다고 가정한다.
- 인기 공격은 인기 아이템의 평점의 평균 값을 안다고 가정한다.
- 푸시 공격에 성공하기 위해 가짜 사용자 프로필에서 다양한 필러 아이템의 평점을 다음과 같이 설정한다.
- 평점 행렬에서 필러 아이템의 평균 평점이 모든 아이템에 대한 전체 평점 평균보다 낮은 경우, 해당 아이템의 평점을 가능한 최솟값으로 설정한다.
- 필러 아이템의 평점이 모든 아이템의 전체 평균 평점보다 높으면 아이템의 평점을 최솟값 + 1로 설정한다.
- 가짜 사용자프로파일에서 대상 아이템의 평정믈 항상 최댓값으로 설정한다.
- 다음과 같이 평점을 설정하는 이유
- 필러 아이템에 대해 최솟값 및 최솟값 + 1의 차등 평점을 선택해 가짜 프로파일 내에서 대상 사용자와 유사한 프로파일을 찾을 가능성을 높이기 위함이다.
- 아이템을 좀 더 효과적으로 밀어넣기 위해 타깃 아이템과 필러 아이템 사이의 평점 격차를 증가시키는 것이다.
- 이 공격을 약간 수정하면 핵 공격에도 사용할 수 있다.
📖 사랑/증오 공격
- 사랑/증오 공격은 핵 공격을 위해 특별히 설계됐으며, 이 공격을 수행하는 데 지식이 거의 필요하지 않다는 것이 주요 장점이다.
- 핵 공격 아이템은 최소 평점 값으로 설정하고, 다른 아이템은 최대 평점 값으로 설정한다.
- 핵 공격은 일반적으로 푸시 공격보다 끼워 넣기가 더 쉽기 때문에 저지식 공격은 종종 푸시 공격과 비교할 때 핵 공격의 경우 성공할 가능성이 더 높다.
- 사랑/증오 공격은 사용자 기반 협업 필터링 알고리듬에 매우 적합하며 아이템 기반 협업 필터링 알고리듬에는 거의 완전히 영향을 주지 못한다.
📖 역밴드 왜건 공격
- 역밴드 왜건 공격은 아이템을 핵 공격하기 위해 특별히 고안됐다.
- 역밴드 왜건 공격은 밴드 왜건 공격의 변형으로, 광범이하게 싫어하는 아이템을 필러 아이템으로 사용해 공격한다.
- 필러 아이템에는 핵 공격당한 아이템과 함께 낮은 평점이 매겨진다.
- 이 공격은 아이템 기반 협업 필터링 알고리듬을 사용해 추천할 때 핵 공격을 하기에 매우 효과적이다.
📖 탐지 공격
- 탐지 공격은 직접적으로 사용자 기반 추천 시스템에서 현실적인 평점으로 공격에 사용하기 위해 좀 더 현실적인 평점을 얻으려고 한다.
- 즉 공격하기 위해 추천 시스템의 작동을 조사한다.
- 탐지 공격에서는 공격자가 시드 프로파일을 작성하고 추천 시스템이 생성한 예측을 사용해 관련 아이템 및 해당 평점을 학습한다.
- 이러한 추천은 이 시드 프로파일의 사용자-이웃에 의해 생성했으므로 시드 프오파일과 상관관계가 있을 가능성이 높다.
- 추천 아이템과 예상 평점을 사용해 시드 프로파일을 현실적으로 향상시킬 수 있다.
- 대상 아이템의 평점은 각각 푸시 공격 또는 핵 공격 여부에 따라 최댓값 또는 최솟값으로 설정된다.
- 탐지 방식에서 학습한 다른 필터 아이템의 평점은 추천 시스템에서 예측한 평균 값으로 설정된다.
📖 세그먼트 공격
- 일반적으로 아이템 기반 협업 필터링 알고리듬을 공격하는 것이 더 어렵다.
- 그 이유 중 하나는 아이템 기반 알고리듬을 공격하기 위해서는 대상 사용자 자신의 평점을 활용해야 하기 때문이다.
- 가짜 사용자를 주입해 실제 사용자의 지정된 평점을 조작할 수는 없다.
- 그러나 가짜 프로파일을 사용해 피어 아이템을 변경할 수 있으며,
피어 아이템을 변경하면 예상 평점 품질에 영향을 준다. - 공격자의 첫 번째 단계는 특정 아이템에 최근접 아이템을 결정하는 것이다.
- 이러한 아이템은 푸시된 아이템과 함께 가능한 최대 평점을 지정한다.
- 샘플링 된 추가 필러 아이템 세트에는 최소 평점을 지정한다.
- 이것은 같은 장르 아이템에 대한 아이템 유사도의 변화를 최대화한다.
- 기본 아이디어는 공격자가 아이템 추천 프로세스에서 매우 유사한 아이템만 사용하도록 하는 것이다.
- 대부분 푸시 공격이 효과적이다.
📖 기본 추천 알고리듬 효과
- 공격 대상 추천 알고리듬에 따라 공격 방법이 달라진다.
- 일반적으로 사용자 기반 추천 알고리듬은 아이템 기반 알고리듬에 비해 공격에 더 취약하다.
📌 추천 시스템에서 공격 탐지
- 강력한 추천 시스템을 유지한다는 관점에서 공격을 맏는 가장 좋은 방법은 공격을 탐지하는 것이다.
- 위조 프로파일을 제거하는 것은 실수하기 쉬운 프로세스이므로 실제 프로파일을 제거할 수 있다.
탐지 알고디름 성과 측정 방법
1. 탐지 알고리듬을 정밀도 및 재현율 측면에서 측정할 수 있다.
2. 추천 시스템 정확도에 대한 프로파일 제거의 영향을 측정할 수 있다.탐지 알고리듬 유형
- 비지도 공격 탐지 알고리듬 : 애드혹 규칙을 사용해 가짜 프로파일을 탐지한다.
- 이 알고리듬 클래스의 기본 아이디어는 실제 프로파일과 유사하지 않은 공격 프로파일의 주요 특성을 식별하는 것이다.
- 지도 공격 탐지 알고리듬 : 지도 공격 탐지 알고리듬은 분류 모델을 사용해 공격을 탐지한다.
- 알려진 공격 프로파일은 +1로 표시하고 나머지 프로파일은 -1로 표시하는 이진 분류를 학습할 수 있다.
- 학습된 분류 모델은 주어진 프로파일이 진짜일 가능성을 예측하는 데 사용한다.
- 지도 공격 탐지 알고리듬은 기본 데이터에서 학습할 수 있는 능력 때문에 일반적으로 비지도 방법보다 효과적이다.
- 반면 공격 프로파일의 예를 얻는 것은 어려운 경우가 많다.
📖 개인 공격 프로파일 탐지
- 개별 공격 프로파일 탐지는 단일 공격 프로파일 탐지라고도 한다.
- 피처의 세트는 각 사용자 프로파일로부터 추출한다.
- 피처는 현재 피처에 따라 비정상적으로 높거나 비정상적으로 낮은 값이 공격을 나타낸다.
- 비정상적인 값을 취하는 피처의 일부를 공격 탐지 수단으로 사용할 수 있다.
- 다른 휴리스틱 함수도 이러한 피처와 함께 사용할 수 있다.
- 예측 차이의 수(NPD) : 주어진 사용자에 대해 NPD는 시스템에서 해당 사용자를 제거한 후 변경된 예측수라고 정의한다.
- 다른 사용자와의 의견 차이(DDI) : 이 값은 사용자 i의 불일치 정도인 DD(i)를 얻기 위해 관찰된 모든 사용자 수의 평점에 대한 평균을 낸다.
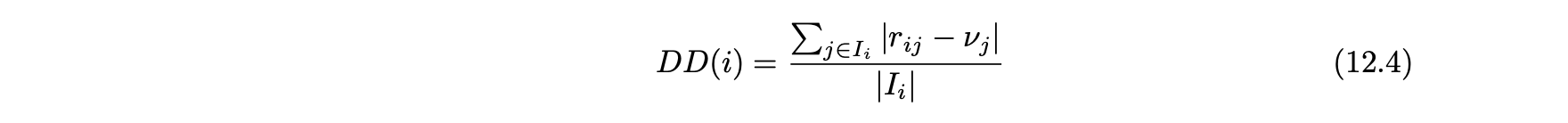
- 다른 사용자와의 의견 차이가 큰 사용자는 공격 프로파일일 가능성이 높다.
- 동의 평균의 평점편차(RDMA) : 동의 평균의 평점편차는 아이템의 평균 평점과 차이의 절댓값으로 정의한다.
- 평균을 계산하는 동안 각 아이템 j의 역빈도로 평균 평점이 바이어스 된다.
사용자 i의 값 RDMA(i)는 다음과 같이 정의된다.
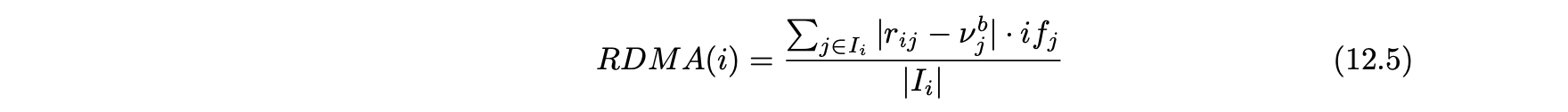
- 이 측정 항목의 값이 클수록 사용자 프로파일이 공격을 나타낼 가능성이 있음을 나타낸다.
- 평균을 계산하는 동안 각 아이템 j의 역빈도로 평균 평점이 바이어스 된다.
- 사용자 평점의 표준편차 : 특정 사용자 평점의 표준편차다.
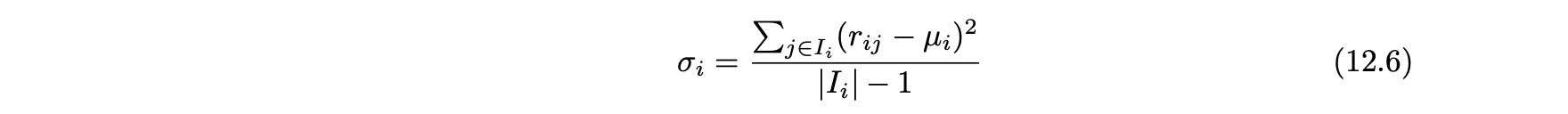
- 가짜 프로파일의 평점이 다른 사용자들과 크게 다르지만 필러 아이템이 평점 값으로 설정돼 있는 경우가 많기 때문에 상당히 자기-유사도가 높은 경우가 많다.
- 결과적으로 표준편차는 가짜 프로파일의 경우 작은 경향이 있다.
- 상위-k 이웃과의 유사도(SN) : 공격 프로파일을 조정 방식으로 삽입하는 경우가 많은데, 그 결과 최근접 이웃과 사용자의 유사도가 높아진다.
따라서 유사도 SN(i)를 다음과 같이 정의한다.
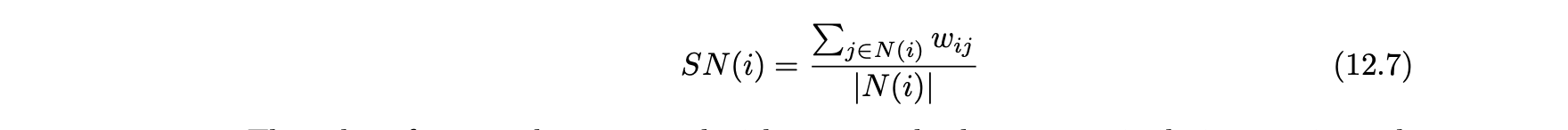
- wij의 값은 피어슨 상관계수와 같은 표준 사용자-사용자 유사도를 계산할 수 있다.
- 이러한 피처 외에도 다수의 일반 및 모델별 피처를 도입했으면 이는 평균 공격 또는 세그먼트 공격과 같은 특정 유형의 공격을 탐지하도록 설계했다.
- 평균 동의 가중 편차(VDMA) : WDMA 측정 항목은 RDMA 측정 항목과 유사하지만 드물게 나타나는 아이템의 평점에 더 큰 가중치를 준다.
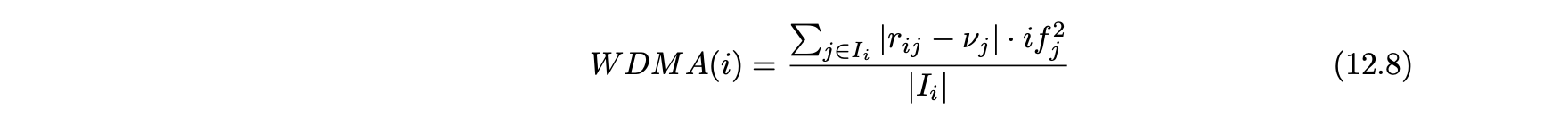
- 동의 가중도(WDA) : RDMA 측정 항목의 두 번째 변형은 수식 12.5의 오른쪽에 정의된 RDMA 측정 항목의 분자만 사용한다.
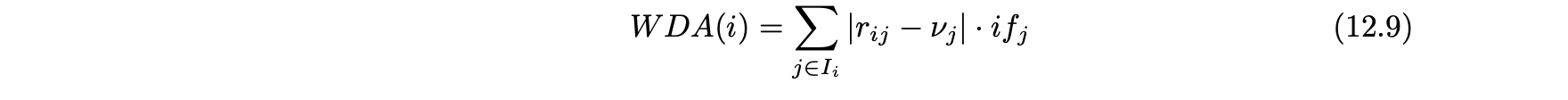
- 수정된 유사도(MDS) : 수정된 유사도는 수식 12.7에 의해 정의된 유사도와 유사한 방식이지만 주된 차이점은 수식 12.7의 유사도 값 wij가 아이템 i와 j를 모두 평가하는 사용자 수에 의해 비례적으로 할인된다는 것이다.
- 이 할인은 사용자 i와 j 사이의 공통 아이템 수가 적을 때 계산된 유사도가 덜 신뢰할 수 있다는 직관을 기반으로 한다.
📖 그룹 공격 프로파일 탐지
- 이 경우 개인이 아닌 그룹으로 공격 프로파일을 탐지한다.
- 여기서 기본 원칙은 공격이 종종 관련 프로파일 그룹을 기반으로 한다는 것이다.
- 따라서 이러한 많은 방법은 클러스터링 전략을 사용해 공격을 탐지한다.
1. 전처리 방법
- 가장 일반적인 방법은 클러스터링을 사용해 가짜 프로파일을 제거하는 것이다.
- 공격 프로파일을 설계하는 방식 때문에 진짜 프로파일과 가짜 프로파일은 별도의 클러스터를 생성한다.
- 이는 가짜 프로파일의 많은 평점이 동일하기 때문에 밀집된 클러스터를 생성할 가능성이 높다.
- PLSA를 사용해 사용자 프로파일을 클러스터링 할 수 있다.
- 하드 클러스터를 식별한 후에는 각 클러스터의 평균 마할라노비스 반지름을 계산한다.
- 이 방벙븐 가짜 프로파일을 포함하는 클러스터의 상대적 조밀성을 전제로 한다.
- 이러한 접근 방식은 비교적 명백한 공격에는 효과적이지만 감지하기 힘든 공격에는 적합하지 않다.
- 보다 간단한 접근법은 주성분 분석만 사용하는 것이다.
- 기본 아이디어는 가짜 사용자 간의 공분산이 크다는 것이다.
- 반면, 가짜 사용자는 사용자를 차원으로 취급할 때 다른 사용자와의 공분산이 매우 낮은 경우가 많다.
- 평점 행렬은 먼저 0과 당뉘 표준편차로 정규화된 다음 전치 공분산 행렬을 계산한다.
- 이 행렬의 최소 고유 벡터를 계산한다.
- 고유 벡터에 기여도가 작은 차원을 선택한다.
- 그룹 프로파일을 탐지하는 또 다른 알고리듬은 UnRAP 알고리듬이다.
- UnRAP 알고리듬에서는 Hv-score라는 측정 값을 사용한다.
- 유전자 클러스터의 biclustering의 맥락에서 사용한다.
- 사용자 i의 Hv-score는 다음과 같이 정의한다.
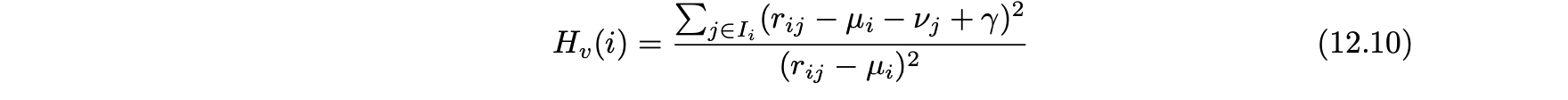
- Hv-score 값이 클수록 공격 프로파일을 더 잘 나타낸다.
- 기본 아이디어는 가짜 프로파일은 평점 값이 자기-유사도를 갖는 경향이 있지만 다른 사용자와는 다른 경향을 보인다.
- 알고리듬은 먼저 Hv-score가 가장 큰 상위 10명의 사용자를 결정한다.
- 그런 다음 대상 아이템을 식별하면 다음 단계의 알고리듬에 대한 단계가 설정된다.
- 그런 다음 사용자를 가짜 후보로 간주하는 기준이 완화되고 10명 이상의 사용자 프로파일이 가짜 후부로 간주된다.
- 그러나 이러한 후보는 많은 거짓 양성을 포함할 것이다.
2. 온라인 방법
- 이 방벙베서 추천을 하는 시간 동안 가짜 프로파일을 감지한다.
- 기본 아이디어는 활성 사용자 근처에 두 개의 클러스터를 만드는 것이다.
- 공격자의 주요 목표는 특정 아이템을 푸시하거나 핵 공격을 하는 것이기 때문에 두 군집에 있는 활성 아이템의 평균 평점에 충분히 큰 차이가 있는 경우 공격이 발생한 것으로 가정한다.
- 활성 아이템의 평점 분산이 더 작은 클러스터는 공격 클러스터로 가정하고 이 공격 클러스터의 모든 프로파일을 제거한다.
- 이 탐지 방법은 이웃 형성 과정에서 공격 방지 추천 알고리듬에 직접 통합할 수 있다는 장점이 있다.
📌 강력한 추천 디자인을 위한 전략
- 추천 시스템을 좀 더 강력한 방식으로 구축하기 위한 다양한 전략을 사용할 수 있다.
📖 CAPTCHA를 사용한 자동 공격 방지
- 예측한 평점이 크게 변하기 위해서는 많은 수의 가짜 프로파일이 필요하다.
- 공격자가 공격을 시작하기 위해 실제 프로필 수의 3%에서 5%의 가짜 프로파일이 필요한 것은 흔한 컨텍스트다.
- 따라서 공격자는 종종 자동 시스템을 사용해 평가 시스템의 웹 인터페이스와 상호작용해서 가짜 프로파일을 삽입한다.
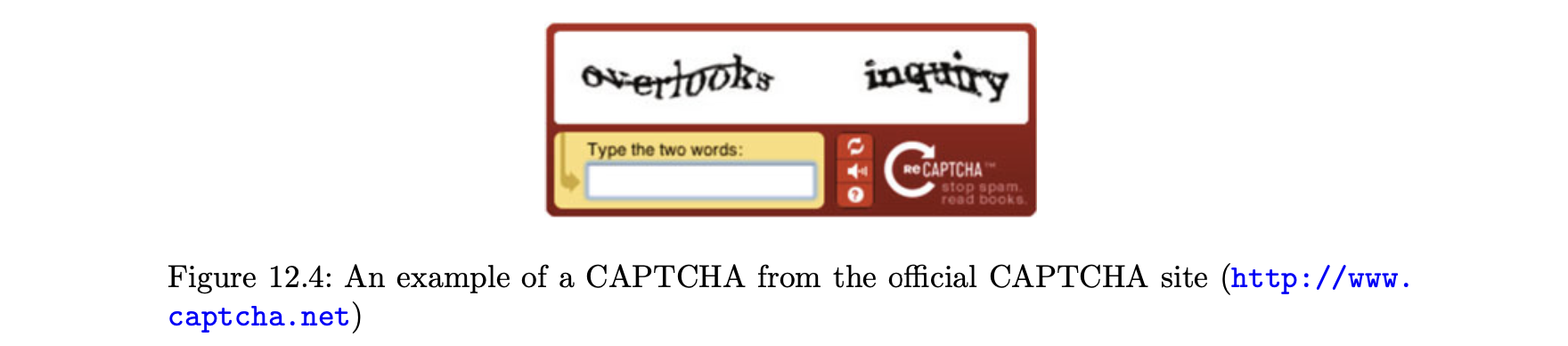
- CAPTCHA는 웹 상호작용하는 컨텍스트에서 인간과 기계의 차이를 알려주기 위해 고안됐다.
- 기본 개념은 왜곡된 텍스트가 사용자에게 제공되면 추가 상호작용을 위해 웹 인터페이스에 입력해야하는 도전 텍스트 또는 단어의 역할을 한다.
- CAPTCHA의 예는 그림 12.4에 나와 있다.
📖 사회적 신뢰 사용
- 사용자는 다른 사용자의 평가 경험에 따라 신뢰 관계를 지정할 수 있다.
- 그런 다음 이러한 신뢰 관계를 사용해 보다 강력한 추천을 만든다.
- 이러한 방법을 사용하면 공격의 효과를 줄일 수 있다.
- 사용자들이 조작된 가짜 프로파일과 신뢰 관계를 맺지 않을 가능성이 높기 때문에 이러한 방법은 공격의 효과를 줄일 수 있다.
📖 강력한 추천 알고리듬 설계
- 공격에 대한 저항을 염두에 두고 여러 알고리듬이 특별히 설계됐다.
1. 클러스터링을 이웃 방법에 통합
- 이 작업은 PLSA 및 k-평균 기법을 사용해 사용자 프로파일을 클러스터링한다.
- 각 클러스터에서 집계 프로파일을 생성한다.
- 집계 프로파일은 세그먼트에 있는 각 아이템의 평균 평점을 기반으로 한다.
- 그런 다음 개별 프로파일 대신 집계 프로파일을 사용하는 것을 제외하면 사용자 기반 협업 필터링에 대한 유사한 접근 방식을 사용한다.
- 각 예측에 대해 대상 사용자와 최근접 집계된 프로파일을 사용해 추천을 만든다.
- 클러스터링 기반 접근 방식은 평점한 최근접 이웃 방법보다 훨씬 더 강력한 결과를 제공한다.
- 이유는 클러스터링 프로세스가 일반적으로 모든 프로파일을 단일 클러스터에 매핑하므로 대체 클러스터를 사용할 수 있을 때 예측에 미치는 영향을 제한하기 때문이다.
2. 추천 시간 동안 가짜 프로파일 탐지
- 이 방법은 활성 사용자의 이웃을 두명의 사용자로 분할한다.
- 활성 아이템이 두 군집에서 매우 다른 평균 값을 갖는 경우 공격이라고 의심한다.
- 자기와 가장 유사한 클러스터를 공격 클러스터로 간주한다.
- 그런 다음 이 클러스터에 있는 프로파일을 제거한다.
- 그런 다음 나머지 클러스터의 프로파일을 사용해 추천한다.
- 이 방법은 공격-탐지 방법과 강력한 추천 알고리듬이라는 두 가지 목적을 가지고 잉ㅆ다.
3. 연관 기반 알고리듬
- 최대 공격 크기가 15% 미만일 때 규칙 기반 알고리듬이 평균 공격에 강하다.
- 그 이유는 성공적인 공격에 필요한 충분한 공격 프로파일이 없기 때문이다.
4. 강건한 행렬 인수분해
- 행렬 인수분해 방법은 일반적으로 공격 프로파일을 노이즈로 처리하는 자연스러운 능력 때문에 공격에 더 강력하다.
- 많은 행렬 인수분해 추천 시스템은 PLSA이 기반이다.
- 공격 단계를 중간 단계에서 제거하고 확률 매개변수를 다시 정규화하면 추천에 직접 사용할 수 있다.
- 또 다른 접근 방법은 행렬 인수분해에서 사용하는 최적화 기능을 수정해 공격에 대해 더 강력하게 만드는 것이다.
- 행렬 인수분해에서 m x n 평점 행렬 R은 다음과 같이 사용자 요인과 아이템 요인으로 분해된다.
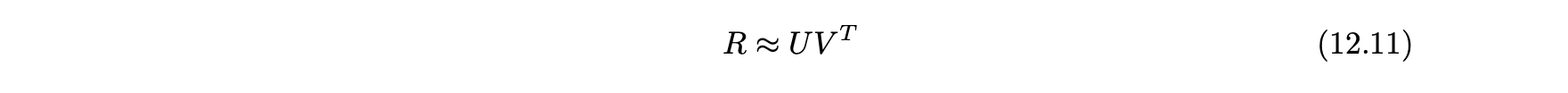
- 아이템의 예측값은 다음과 같다.
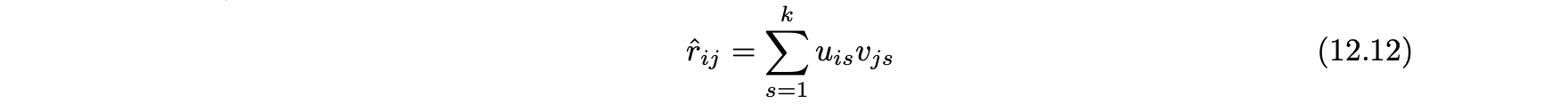
- 행렬 인수분해의 목적 함수는 다음과 같다.
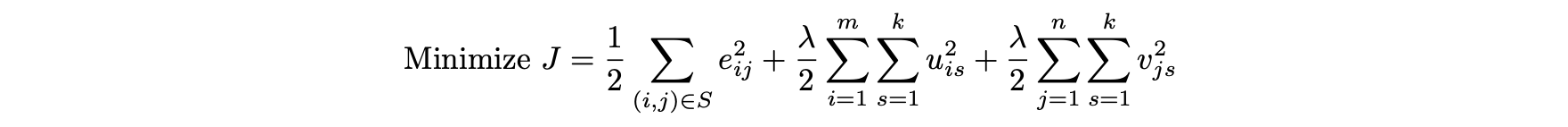
- 매우 큰 절댓값 오류의 영향을 강조하지 않기 위해 새로운 오류 항 세트를 정의한다.
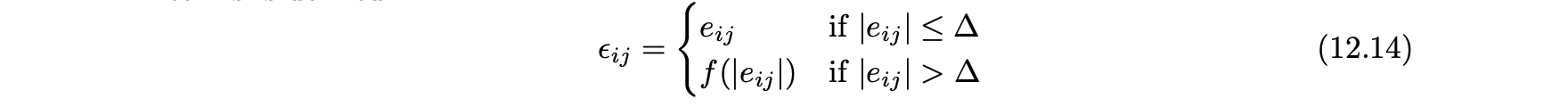
- 여기서 ▵는 사용자 정의 임계값으로, 원소가 커질 때를 의미한다.
- 감쇠는 큰 값의 오류가 지나치게 중요하지 않도록 하며, 다음과 같다.
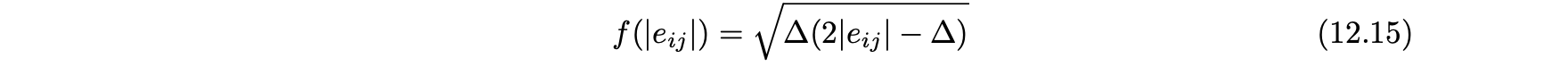
- 감쇠 함수를 사용한 강건한 행렬 인수분해를 위한 목적 함수는 다음과 같다.
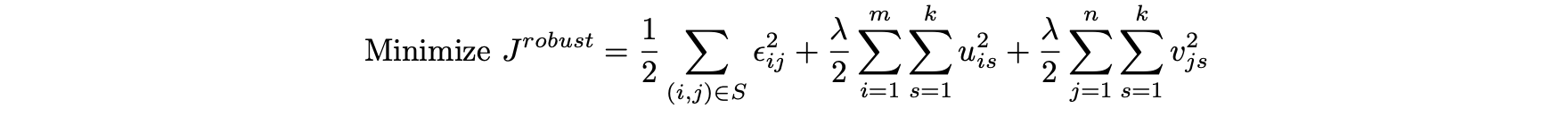
- 최소 제곱법 알고리듬을 최적화 프로세스에 사용한다.
첫 번째 단계는 각 결정 변수에 대한 목적함수의 기울기를 계산한다.
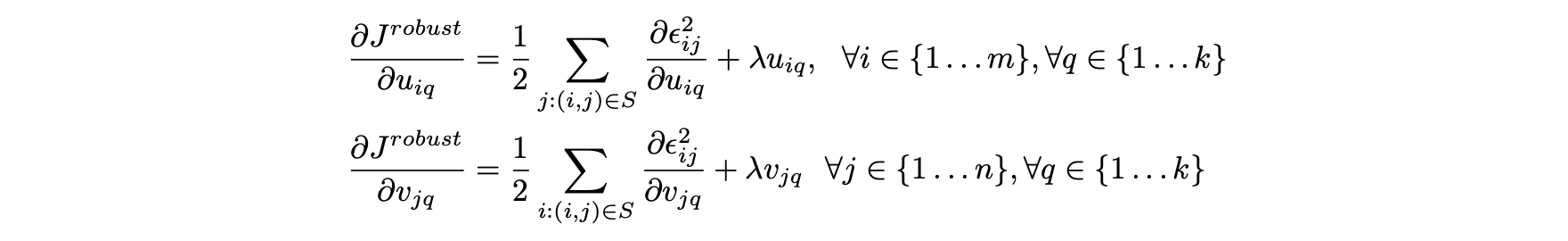
- 앞에서 언급한 그레이디언트는 결정 변수와 관련해 편미분을 포함한다는 점에 유의한다.
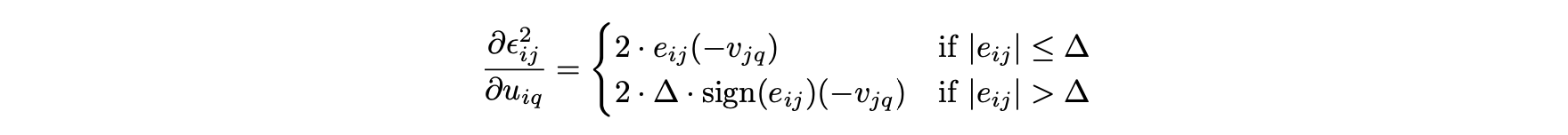
- 여기에서 부호 함수는 양수의 경우 +1, 음수의 경우 -1을 취한다.
미분에 대한 사례별 설명은 다음과 같이 단순한 형태로 통합할 수 있다.
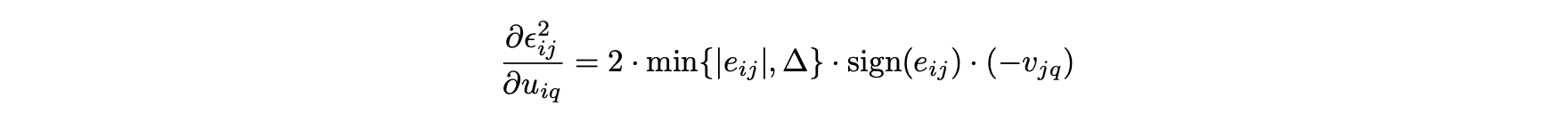
- vjq에 대한 편미분은 다음과 같이 계산할 수 있다.
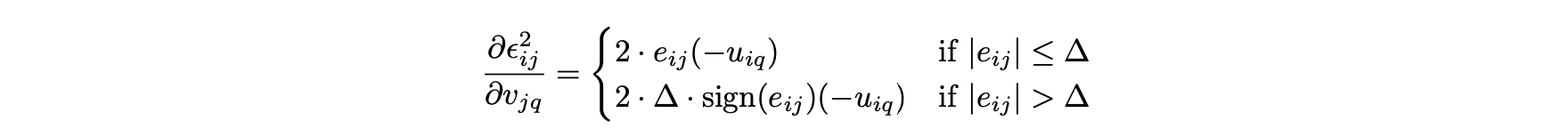
- 이제 각 사용자 i와 각 아이템 j에 대해 실행해야 하는 업데이트 단계를 다음과 같이 도출할 수 있다.
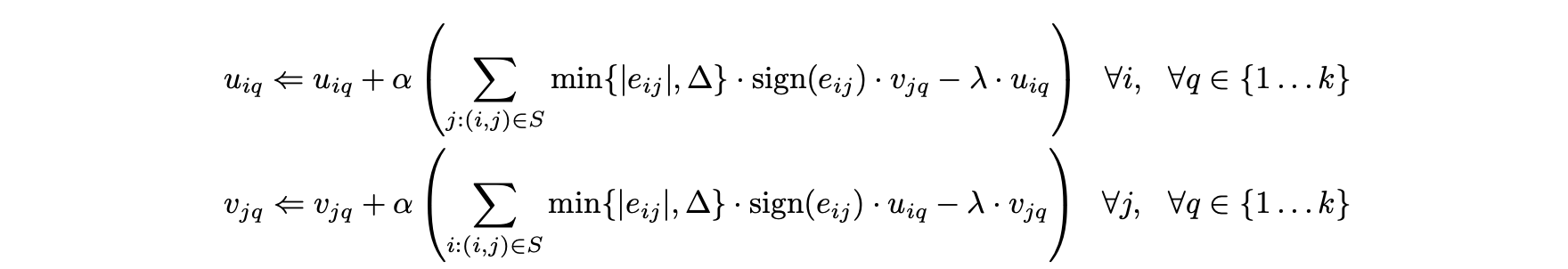
- 확률 경사하강법도 수행 가능하다.
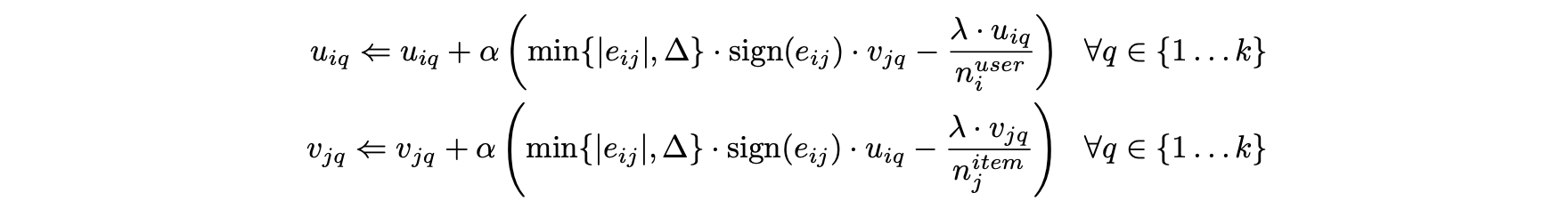
- 이러한 업데이트 단계는 오차가 ▵보다 큰 경우 기울기 성분의 절댓값을 제한한다는 점에서만 기존의 행렬 인수분해와 다르다.
- 행렬 인수분해에서 m x n 평점 행렬 R은 다음과 같이 사용자 요인과 아이템 요인으로 분해된다.

연세대학교 컴퓨터과학과 석사 과정