
Coding Test
눈떠보니 코딩테스트 전날
공백 제거
- replace()
문자열.replace(old, new)- 첫 번째 인자에는 없앨 문자, 두 번째 인자에는 바꿀 문자를 넣어주면 원하는 문자로 변경한 새로운 문자열을 반환
- strip()
문자열.strip()- 모든 공백을 제거할 수 있는
replace함수와 달리 양쪽 끝에 있는 공백을 제거할 수 있음 - 해당 함수는 문자열 양 끝에 있는 공백을 제거해주고 공백을 제거한 새로운 문자열을 반환
- 인자를 전달하지 않으면 문자열에서 공백을 제거
- 인자로 문자 1개를 전달하면 그 문자와 동일한 것을 모두 제거
- 인자로 여러 문자를 전달하면 그 문자들과 동일한 것들을 모두 제거
- 모든 공백을 제거할 수 있는
문자열.lstrip()함수는 문자열 왼쪽에 있는 공백을 없애줌문자열.rstrip()함수는 문자열 오른쪽에 있는 공백을 없애줌
아스키 코드 변환
- ord()
- 특정한 한 문자를 아스키 코드 값으로 변환해주는 함수
ord(문자)- 하나의 문자를 인자로 받고 해당 문자에 해당하는 유니코드 정수를 반환
- 나온 유니코드 10진수를 16진수로 변경하고 싶을 때
hex()로 감싸주면 됨
# 예시 코드
>>> print(ord('A'))
65
>>> print(ord('a'))
97
>>> print(hex(ord('b'))
0x62- chr()
- 아스키 코드 값을 문자로 변환해주는 함수 (10진수, 16진수 사용 가능)
chr(정수)- 하나의 정수를 인자로 받고 해당 정수에 해당하는 유니코드 문자를 반환
- 인자(정수)의 유효 범위는 0~1,114,111 (16진수: 0x10FFFF)
# 예시 코드
>>> print(chr(65))
A
>>> print(chr(96))
`
>>> print(chr(0x32))
2문자열 정렬
- zfill()
문자열.zfill(자리수)- 지정한 자리수에서 모자란 자리수에는 0을 채워줌
- 지정한 자리수보다 대상 문자열 길이가 긴 경우에는 아무런 변화가 일어나지 않음
- 문자열 앞에 '+'나 '-' 기호가 있는 경우에도 0을 채워줌
- 이 때 '+'나 '-'도 자리수에 포함되어 계산됨
# 예시 코드
>>> str = '1234'
>>> str_zero = str.zfill(8)
>>> print(str_zero)
00001234
>>> print(type(str_zero))
<class 'str'>
>>> print(str.zfill(3))
1234
>>> s = '-1234'
>>> print(s.zfill(8))
-0001234
>>> s = '+1234'
>>> print(s.zfill(8))
+0001234
>>> str = 'abcd'
>>> print(str.zfill(8))
0000abcd- rjust()
문자열.rjust(자리수, 메워줄 문자)- 오른쪽으로 정렬하도록 도와줌
- 공백의 수, 공백을 메워줄 문자를 넣어줄 수 있음
- ljust()
문자열.ljust(자리수, 메워줄 문자)- 왼쪽으로 정렬하도록 도와줌
- 공백의 수, 공백을 메워줄 문자를 넣어줄 수 있음
- center()
문자열.center(자리수, 메워줄 문자)- 가운데로 정렬하도록 도와줌
- 공백의 수, 공백을 메워줄 문자를 넣어줄 수 있음
람다 함수
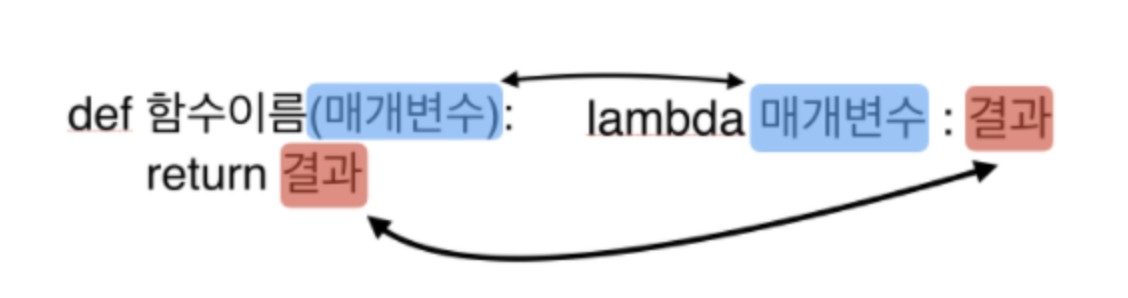
- lambda 인자: 표현식
lambda 매개변수(인자): 매개변수(인자)를 이용한 동작- 람다 함수는 일반 함수를 가볍게 만든 함수
유용한 내장 함수
- map()
map(함수, 리스트나 튜플)map(function, iterable)
- 함수(f)와 순회 가능한(iterable) 자료형을 입력으로 받음
- 첫번째 인자인 함수는 두번째 인자로 들어온 리스트나 튜플에 특별한 가공 처리를 해주는 함수
- map만 실행 시 요소의 내용이 바로 출력되지 않음
list()로 타입 변환하여 요소를 출력- 예시:
list(map(lambda x: x + 2, [1, 2, 3, 4, 5]))
- filter()
filter(함수, 리스트나 튜플)filter(function, iterable)
- 첫번째 인자에는 두번째 인자로 들어온 리스트나 튜플을 하나하나씩 받아서 필터링 할 함수
- True인 값을 가지는 요소만 filter
- filter만 실행 시 요소의 내용이 바로 출력되지 않음
list()로 타입 변환하여 요소를 출력- 예시:
list(filter(lambda x: x % 2 == 0, range(10)))
- zip()
zip(리스트나 튜플들)zip(*iterable)
- 동일한 개수로 이루어진 자료형을 묶어주는 역할
- 작은 크기를 가지는 리스트나 튜플에 맞춰 생성
# 예시 코드
>>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> b = [0, 1, 2, 3, 5, 8, 13, 21, 34, 55]
>>> c = [5, 6, 7]
>>> list(zip(a, b, c))
[(1, 0, 5), (2, 1, 6), (3, 2, 7)]- enumerate()
enumerate()enumerate(iterable, start=0)
- 순서가 있는 자료형을 입력 받아 인덱스를 포함하는 튜플 형태로 반환
# 예시 코드
>>> item = ["A", "B", "C"]
>>> for value in enumerate(item):
... print(value)
...
(0, 'A')
(1, 'B')
(2, 'C')
>>> for idx, value in enumerate(range(1, 10, 2)):
... print(f'index: {idx}, value: {value}')
...
index: 0, value: 1
index: 1, value: 3
index: 2, value: 5
index: 3, value: 7
index: 4, value: 9코딩 테스트 보기 전
Built-in Functions
- 내장 함수(Built-in Function)란 import 과정을 필요로 하지 않는 함수들을 일컬음
- 파이썬에는 약 40개 가량의 built-in Function이 존재
실무에서 자주 사용
- abs()
- 절대값을 반환
# 예시 코드
>>> a = -3
>>> b = -1.65
>>> c = 1 - 1j
>>> abs(a)
3
>>> abs(b)
1.65
>>> abs(c)
1.4142135623730951- all()
- 반복 가능한 (iterable) 객체의 모든 요소가 True일 때 True를 반환
- 빈 객체의 경우 False를 반환
# 예시 코드
>>> a = [1, 2, 3]
>>> b = [True, False, True]
>>> c = 'an apple'
>>> all(a)
True
>>> all(b)
False
>>> all(c)
True- any()
- 반복 가능한 (iterable) 객체의 요소 중 어느 하나라도 True일 때 True를 반환
- 빈 객체의 경우 False를 반환
# 예시 코드
>>> a = [1, 0, 3]
>>> b = [False, False, False]
>>> c = (1, 0, 0, 4)
>>> any(a)
True
>>> any(b)
False
>>> any(c)
True- dir()
- 객체가 가지고 있는 변수나 함수를 리스트 형태로 반환
- 모듈에 적용시 모듈에 포함된 함수를 볼 수 있음
# 예시 코드
>>> dir([1,2,3])
['__add__', '__class__', ..., 'reverse', 'sort']
>>> import sys
>>> dir(sys)
['__displayhook__', '__doc__;, ..., 'warnoptions', 'winver']코딩 테스트에서 자주 사용
- format()
- filter()
- len()
- 인덱스 마지막 값은 아님
- map()
- zip()
- max()
- min()
- reversed()
- sorted()
- sort() 와 차이점
- sort()는 리스트를 직접 만짐
- sorted()는 리스트 반환값만 정렬
- sorted()에는 key값 넣을 수 있음
- sort() 와 차이점
# 예제 코드
>>> testOne = ['abc', 'def', 'hello world', 'hello', 'python']
>>> testTwo = 'Life is too short, You need python'.split()
>>> testThree = list(zip('anvfe', [1, 2, 5, 4, 3]))
>>> sorted(testOne, key=len)
['abc', 'def', 'hello', 'python', 'hello world']
>>> sorted(testOne, key=len, reverse=True)
['hello world', 'python', 'hello', 'abc', 'def']
>>> sorted(testTwo, key=str.lower)
['is', 'Life', 'need', 'python', 'short,', 'too', 'You']
>>> sorted(testThree, key=lambda x: x[1])
[('a', 1), ('n', 2), ('e', 3), ('f', 4), ('v', 5)]
>>> sorted(testThree, key=lambda x: x[0])
[('a', 1), ('e', 3), ('f', 4), ('n', 2), ('v', 5)]- in
- not in
list
- append()
- clear()
- copy()
- count()
- extend()
- 요소 많이 추가할 때
- index()
- insert()
- 해당되는 자리에 요소 추가할 때
- pop()
- remove()
- del 로 지우는게 빠름
- reverse()
- sort()
# 예시 코드
# Que
>>> l = []
>>> l.append(10)
>>> l.append(20)
>>> l.appned(30)
>>> l.pop(0)
>>> l.append()
# Stack
>>> l = []
>>> l.append(10)
>>> l.append(20)
>>> l.append(30)
>>> l.pop()
>>> l.append()tuple
- count()
- index()
dictionary
- clear()
- copy()
- fromkeys()
- get()
- items()
- keys()
- pop()
- popitem()
- setdefault()
- update()
- values()
set
- add()
- clear()
- copy()
- difference()
- 차집합
집합하나.difference(집합둘)
- difference_update()
- discard()
- 삭제
- intersection()
- intersection_update()
- isdisjoint()
- issubset()
- issuperset()
- pop()
- remove()
- 요소 제거
- symmetric_difference()
- symmetric_difference_update()
- union()
- 합집합
- update()
- 요소 많이 추가할 때
# 예시 코드
>>> 판콜에이 = {'A', 'B', 'C'}
>>> 타이레놀 = {'A', 'B', 'D'}
>>> 판콜에이.difference(타이레놀) # 차집합
{'C'}
>>> 판콜에이.intersection(타이레놀) # 교집합
{'B', 'A'}
>>> len(판콜에이.intersection(타이레놀) # 교집합
2
>>> 판콜에이.union(타이레놀) # 합집합
{'B', 'A', 'D', 'C'}# 예시 코드
# 단톡방에 x마리의 동물이 대화를 하고 있습니다.
# 각각의 동물들이 톡을 전송할 때마다 서버에는 아래와 같이 저장됩니다.
# 1. 단톡방에는 모두 몇 마리의 동물이 있을까요? 톡은 무조건 1회 이상 전송합니다.
# 2. 단톡방에 동물들마다 몇 번의 톡을 올렸을까요?
>>> serverData = '개리 라이캣 개리 개리 라이캣 자바독 자바독 파이 썬'
>>> set(serverData.split())
{'개리', '라이캣', '썬', '자바독', '파이'}
>>> len(set(serverData.split()))
5
>>> d = {}
>>> for i in set(serverData.split()):
... d[i] = serverData.split().count(i)
>>> d
{'라이캣': 2, '썬': 1, '파이': 1, '자바독': 2, '개리': 3}# 예시 코드
>>> [int(i) for i in '1 2 3 4 5 6 7'.split()]
[1, 2, 3, 4, 5, 6, 7]
>>> list(map(int, '1 2 3 4 5 6 7'.split()))
[1, 2, 3, 4, 5, 6, 7]
🌱 Backend-Dev | hwaya2828@gmail.com