
Character Encoding
Character Encoding
문자 인코딩 (Character Encoding) 이란?
- 문자 인코딩(
Encoding)이란 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호(바이너리 데이터)로 만드는 것
- 컴퓨터는 모든 정보를 0과 1인 바이너리, 즉 숫자로 저장함
- 그러나 우리는 문서 작업, 코딩, 메시지 등 컴퓨터에서 문자를 사용하여 입력하고 저장하며 처리하고 있음
- 우리가 메모장에 한글로 문자열을 입력하여 저장하게 되면 컴퓨터가 한글을 어떻게 이해할 수 있을까?
- 입력된 한글을 컴퓨터가 이해할 수 있는 신호(바이너리 데이터)로 변환하는 과정이 일어남
- 역으로 디코딩(
Decoding)이란 0과 1로 구성된 바이너리 데이터를 다시 문자로 복구하는 것
문자 셋 (Character Set) = 코드표 | 인코딩 방식
- 바이너리 데이터로 변환하는 인코딩과 다시 문자로 변환하는 디코딩은 미리 정해진 규칙에 의해서 수행
- 이렇게 미리 정해진 규칙을 문자 셋이라고 하며, 초기 표준 문자열 셋은 아스키(
ASCII), 엡시딕(EBCDIC) 등 이었음 - 그러나 인터넷이 전세계적으로 보급되며 표현해야 할 문자가 증가하면서 문자 셋들을 표준화 할 필요성이 대두되었고 이후 이후 등장하게 된 것이 유니코드(
UNICODE)
- 이렇게 미리 정해진 규칙을 문자 셋이라고 하며, 초기 표준 문자열 셋은 아스키(
Tip! 아스키(
ASCII)란?
- American Standard Code for Information Interchange의 약자
- 아스키(
ASCII) 코드는 문자 그대로 미국에서 정의하고 있는 표준, 영문 알파벳을 사용하는 대표적인 문자 인코딩- 초창기 컴퓨터를 기계어만을 사용하여 개발하는 것에 어려움이 있어 문자를 코드화하기 위해 아스키(
ASCII) 코드가 탄생하게 되었고 대부분의 인코딩이 아스키(ASCII)에 기초하고 있음
Tip! 유니코드(
UNICODE)란?
- 한글 뿐만 아니라 중국어, 일본어도 마찬가지로 각자의 언어를 표현할 수 있는 인코딩 방식과 다른 문자열 셋을 사용하기 때문에 모든 언어를 동시에 표현할 수는 없었음
- 결국
전세계의 모든 문자를 하나의 문자 셋으로 표현할 수 없을까?라는 문제가 등장하게 됨
- 이러한 문제를 해결하기 위해 전세계적으로 사용되는 모든 문자 집합을 하나로 모아 탄생시킨 것이 유니코드(
UNICODE)- 다양한 언어들을 표현하기 위해 등장한 유니코드는 2바이트로 모든 문자를 표현하는데 아스키코드에 비해서 1바이트가 늘어난거죠.
- 유니코드(
UNICODE)의 목적은 현존하는 문자 인코딩 방법들을 모두 유니코드(UNICODE)로 교체하려는 것
문자 인코딩과 문자 셋
- 문자 인코딩과 문자 셋은 약간 다른 개념
- 문자 인코딩 : 문자를 컴퓨터가 이해할 수 있는 신호(바이너리 데이터)로 만드는 것
- 컴퓨터가 이해할 수 있는 바이너리로 어떤 방법을 사용해도 상관없는 방법론
- 문자 셋 : 인코딩과 디코딩을 위해 미리 정해진 규칙
- 문자를 숫자로 매핑해주는 표
- 문자 인코딩 : 문자를 컴퓨터가 이해할 수 있는 신호(바이너리 데이터)로 만드는 것
- 예를 들어
Base64인코딩은 문자열을 아스키(ASCII)로 인코딩한 후 다시Base64코드표를 통해 인코딩을 수행- 이미 컴퓨터가 이해할 수 있는 아스키(
ASCII)로 인코딩된 문자열을 새로운Base64코드표로 인코딩한다는 뜻 - 위의 예시와 같이 인코딩이란 바이너리를 생성하기 위한 과정이라고 볼 수 있음
- 이미 컴퓨터가 이해할 수 있는 아스키(
Tip!
Base64란?
- 그대로 직역하면 64진법이라는 뜻
- 컴퓨터 분야에서 쓰이는
Base 64란 8비트 이진 데이터(예를 들어 실행 파일이나, ZIP 파일 등)를 문자 코드에 영향을 받지 않는 공통 아스키(ASCII) 영역의 문자들로만 이루어진 일련의 문자열로 바꾸는 인코딩 방식을 가리키는 개념
- 임의의 바이트 스트림을 화면에 표시할 수 있는 아스키(
ASCII) 문자들로 바꾸는 인코딩 방식
- 또한 아스키(
ASCII) 인코딩과 같이 문자 셋과 문자 인코딩이 동일한 경우도 있기 때문에 인코딩이 문자 셋을 포함하고 있다고 생각할 수 있음
Tip! 추가 내용
UTF-8
- 전세계에서 개발자들이 가장 많이 사용하는 인코딩 방식
- 일반적으로 운영되는 서버들의 운영 체제는 리눅스 계열
- 이러한 리눅스 계열의 대부분은 유니코드(
UNICODE)를 지원하기 때문에UTF-8방식을 활용한다면 따로 인코딩 과정을 거치지 않아도 되게끔 인터넷 환경이 주어져 있음UTF-8방식은 조합형 인코딩 방식으로 주어진 문자들을 하나하나 조합해서 문자를 완성하는 방식- 예시: 'ㄱ' + 'ㅐ' + 'ㅂ' + 'ㅏ' + 'ㄹ' → 개발
EUC-KR
- 이 방식은 글자 하나하나가 완성되어야 하는 방식
- 예시: '개' + '발' → 개발
- 이를 완성형 방식이라고 하는데 컴퓨터에게 주어진 문자표에서 완성된 글자 하나하나를 찾아서 완성해나가는 방식이라고 생각하면 됨
- 얼핏 생각해보면 이 방식은 활용도 면에서 굉장히 안좋은 방식이라고 생각할 수 있는데 문자표에 우리가 표현하고자 하는 언어가 없다면 표현할 수 없기 때문
- 그런데 왜 이 방식을 사용하는걸까?
- 윈도우의 문자 인코딩 방식이 완성형이기 때문
- 사용하는 운영체제의 방식이 완성형이다보니 여기에 맞는 문자인코딩 방식이 필요했고 그 결과가
EUC-KR의 개발로 이어진 것
문자 깨지는 현상
- 컴퓨터를 사용하는 과정에서 문자가 깨지는 현상이 발생한다면 클라이언트와 서버 혹은 컴퓨터 사이에 문자 인코딩의 방식이 맞지 않아서 그런 것이라고 생각하면 됨
- 서로 간에 말을 통역해줄 수 있는 사람이 말을 제대로 전달해주지 못하고 있는 것
- 그렇기 때문에 이런 현상이 발생했을 때에는 당황하지 말고 문자인코딩의 방식을 바꾸어보시면 해결 가능
한글 깨짐 현상
원인 분석 및 해결 방법
- 우리나라 표준에는
KSC5601을 표준 한글 코드로 정의하고 있는데, 기본은 완성형 한글이고 자모가 입력될 때 글자를 모은 다음 코드 테이블에서 코드를 찾아 치환- 메모리 낭비가 심하다는 단점이 있음
- 한글 웹 브라우져에서는
KSC5601코드를 기본으로 사용- 그리고 웹으로 전송 할 때에는
x-www-form-urlencoded형식으로 인코딩이 됨 - 그런데 한글 코드
KSC5601이 인코딩되어 전달되면KSC5601이 왔다고 생각하지 않고 라틴어(ISO-8859-1)가 왔다고 생각하는 경우 존재- 라틴어 표준 코드는
ISO-8859-1
- 라틴어 표준 코드는
- 그러면 전달된 한글 코드를
ISO-8859-1형식으로 인코딩하게 됨 - 인코딩 방식을
KSC5601로 바꿔주면 해결
- 그리고 웹으로 전송 할 때에는
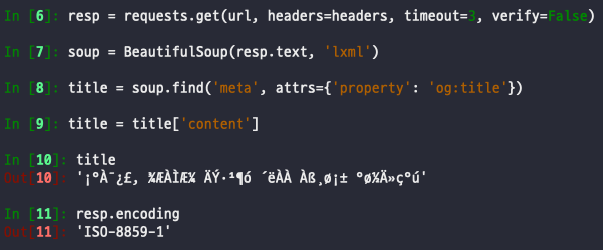

추가 문제
ISO-8859-1이었던 인코딩 방식을KSC5601로 변경해도 한글 깨지는 경우 발견- 인코딩 방식을
UTF-8로 변경하면 해결
- 인코딩 방식을



🌱 Backend-Dev | hwaya2828@gmail.com