
ElasticSearch
용어 정리
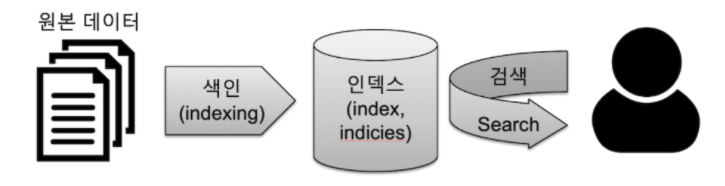
- 색인 (Indexing)
- 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환 & 저장하는 과정
- 인덱스 (Index)
- 색인 과정을 거친 결과물인 색인된 데이터가 저장되는 저장소
- 검색 (Search)
- 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정
- 질의 (Query)
- 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건
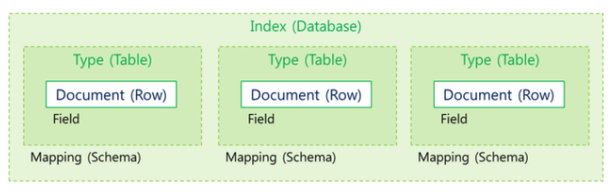
Tip! RDB와 비교
시스템 구조
- Index
- ElasticSearch의 가장 큰 데이터 단위 (Database)
- Document를 모아둔 집합
- Type
- Document를 유형별로 모아놓은 집합 (Table)
- Document
- ElasticSearch의 단일 데이터 단위 (Row)
- json 개체
Tip! ElasticSearch의 구성 요소
- 엘라스틱서치는 기본적으로 클러스터라는 단위로 데이터를 제공
- 클러스터는 하나 이상의 물리적인 노드로 이루어져 있으며 각 노드는 모두 데이터 색인 및 검색 기능을 제공하는 일종의 물리적인 서버와 같음
- 내부에는 루씬 라이브러리를 사용하고 있으며 루씬은 엘라스틱서치의 근간을 이루는 핵심 모듈
Shard < Node < Cluster
Shard
- 루씬의 단일 검색 인스턴스

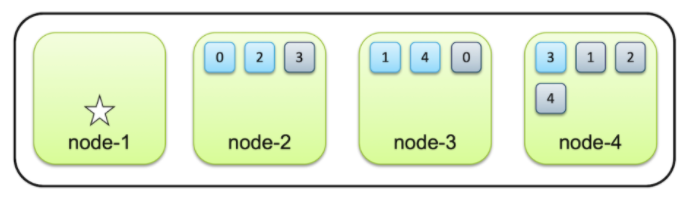
- Index는 Shard 단위로 분리되고, 각 Node에 분산되어 저장됨
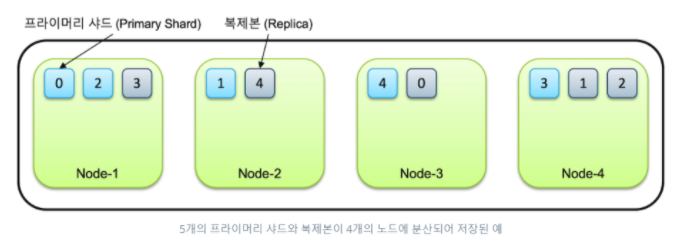
- 디폴트로 1개의 Replica가 생기지만, Node가 1개일 때는 생성되지 않음
- 데이터 가용성 & 무결성을 위해 최소 3개의 노드로 구성 권장
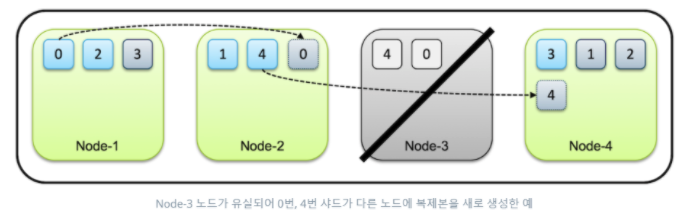
- Shard와 Replica는 반드시 서로 다른 노드에 저장됨
- 타임아웃 시 재복제
- Primary Shard 유실 시, 기존 Replica가 승격되고 다른 노드에 Replica 생성
Node
- Master Node
- Cluster 내에서 하나의 Node는 인덱스의 메타 데이터, Shard의 위치 등 Cluster 상태 정보를 관리해야 함
- Master Node 역할을 수행할 Node가 없으면 Cluster 작동 중지
- Master Eligible Node
- 현재 Master Node가 네트워크 상에서 끊어지거나 다운되면 후보 Node 중 하나가 Master Node로 선출
- Master Node 후보들은 Master Node의 정보들을 공유하고 있어서 즉시 Master 수행 가능
- Data Node
- Master Node와 관계 없이 오로지 데이터 관리에만 사용되는 Node
- Cluster에서 이들의 역할을 확실하게 나누어주면 업무 효율 상승
Split Brain
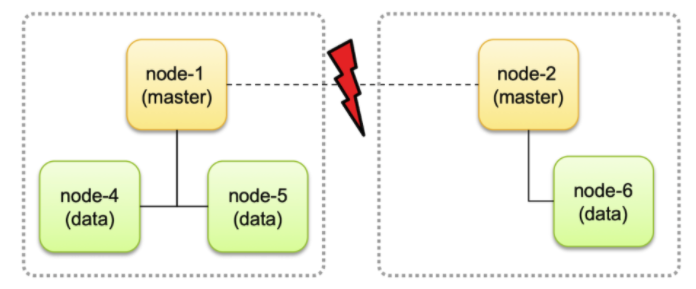
Tip! Split Brain이란?
- 마스터 후보 노드(Master Eligible Node) 사이에 네트워크가 단절되었을 때 각각의 마스터 후보 노드가 마스터 노드로 승격하여 두 개의 클러스터로 나뉘어 독립적으로 동작하는 현상
- 양쪽 클러스터에서 각각 데이터 업데이트가 이루어지면 나중에 네트워크가 복구되어도 각각 마스터가 따로 존재하기 때문에 따로 운영되어 데이터 비동기 문제로 데이터의 손실 발생
- Master Eligible Node가 하나일 경우, 그 Node가 유실되면 Cluster 전체 작동 중지 → 위험!
- 따라서 다수의 Master Eligible Node를 두기를 권고
- 짝수로 둘 경우 Split Brain 위험이 있음
minimun_master_nodes = (전체 master eligible node / 2) + 1개로 설정
ElasticSearch 데이터 색인
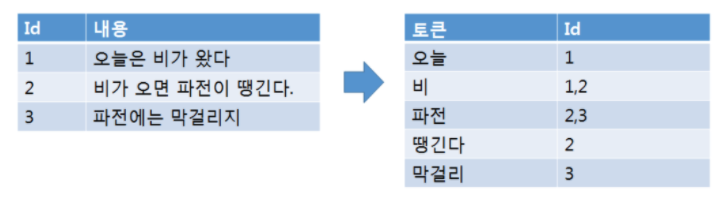
역인덱스
- ElasticSearch는 데이터를 저장할 때 검색에 유리하도록 데이터를 역인덱스(Inverted Index) 구조로 저장하기 때문에 데이터 검색에 한해서는 기존의 RDB 보다 성능이 뛰어남
- ElasticSearch에서는 데이터를 저장하는 과정을 색인(Indexing)한다고 표현
텍스트 분석
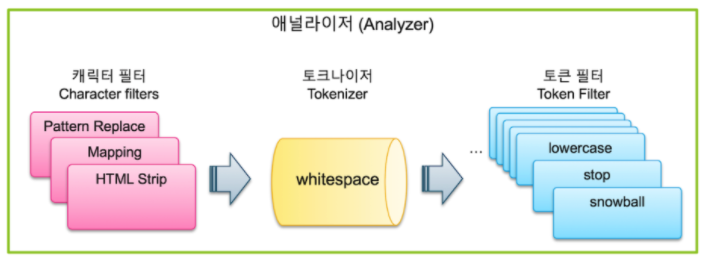
- 캐릭터 필터 (Character Filters)
- 필요에 따라 전체 문장에서 특정 문자를 대치하거나 제거하는 담당
- 토크나이저 (Tokenizer)
- 문장에 속한 단어들을 텀 단위로 하나씩 분리해내는 처리 과정 담당
- 토큰 필터 (Token Filter)
- 분리된 텀들을 하나씩 가공하는 과정 담당
- 예시 > snowball: -s, -ing 등을 제거하고 형태소끼리 동일한 단어는 동일하게 처리 & 동의어 처리

🌱 Backend-Dev | hwaya2828@gmail.com