
Kafka
탄생 배경
- 링크드인 ( LinkedIn ) 은 파편화된 데이터 수집 및 분배 아키텍처를 운영하는데 큰 어려움을 겪었음
- 일반적으로 데이터를 생성하는 소스 어플리케이션과 생성된 데이터가 적재되는 타깃 어플리케이션은 당연히 연결되어야 함
- 그런데 이 아키텍쳐들이 점점 거대하고 복잡해지면서 이 데이터 라인이 기하급수적으로 복잡해짐
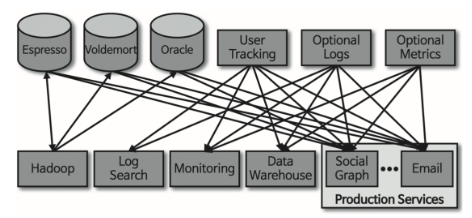
- 위 처럼 각각의 어플리케이션이 알아야 할 관계들이 많아짐에 따라 운영 관리가 복잡하게 되었고 이를 정리할 필요성을 느낌
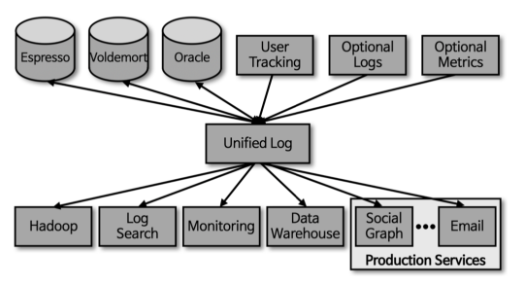
- 링크드인의 데이터 팀은 이 문제를 해결할 수 있는 신규 시스템을 만들었고 이것이 바로
Apache Kafka( 아파치 카프카 )Kafka는 어플리케이션의 관계를 연결하는 것이 아닌 한 곳에 모아서 처리할수 있도록 중앙집중화 하여 문제를 해결하였음
- 기존에 1:1 매칭으로 개발하고 운영하던 데이터 파이프라인은 어느 한 쪽의 어플리케이션에 장애가 발생할 시에 다른 쪽의 어플리케이션에 영향을 미침
Kafka는 대신 메시지 큐 기반 ( FIFO ) 의 구조를 활용하여 이러한 커플링을 해결- 소스 어플리케이션은 어떤 타깃 어플리케이션으로 보낼 것인지 하나하나 설정할 필요 없이 무조건
Kafka로 넣으면 그 이후에는 타겟 어플리케이션이 저장된 데이터를 필요할 때 입력된 순서대로 가져가기만 하면 됨
배치 처리를 통한 높은 처리량
- 매 요청마다 TCP 연결을 위해 3-handshake 를 하고 자원을 할당하는 것은 네트워크 비용
- 동일한 양의 데이터를 묶음으로 처리할 수 있다면 이러한 비용을 절감 할 수 있는데
Kafka는 많은 량의 데이터를 동일 목적의 데이터를 여러 파티션에 분배하고 이를 병렬 처리할 수 있음
- 동일한 양의 데이터를 묶음으로 처리할 수 있다면 이러한 비용을 절감 할 수 있는데
- 다만 소스 어플리케이션과 타겟 어플리케이션이 복잡할 경우에는 1:1 처리 시에 중복된 많은 네트워크 통신이 발생하겠지만 아키텍쳐가 단순할 때는 네트워크 비용 절감에 드라마틱한 효과를 보긴 어려움
- 가령 타겟 어플리케이션이 하나라면 애초에 데이터 저장에 있어 중복된 요청들이 없기 때문에 네트워크 통신은 타겟 어플리케이션이 부담하는 것들이 단순히
Kafka로 이동한 형태가 됨
- 가령 타겟 어플리케이션이 하나라면 애초에 데이터 저장에 있어 중복된 요청들이 없기 때문에 네트워크 통신은 타겟 어플리케이션이 부담하는 것들이 단순히
장애 발생을 대비하는 영속성
Kafka는 다른 메시징 플랫폼과는 다르게 전송받은 데이터를 메모리에 저장하지 않고 파일 시스템에 저장- 일반적으로 파일 시스템에 저장하게 되면 메모리에 저장하는 것보다 느림
Kafka는 이를 파일 I/O 성능 향상을 위한 페이지 캐시 ( Page Cache ) 영역을 메모리에 따로 생성하여 사용하는 운영체제의 방식을 활용- 한번 읽은 파일 내용은 메모리에 저장해두고 사용하기 때문에 파일 시스템에 데이터를 저장하더라도 전송 처리량이 높음
- 파일 시스템으로 저장하기 때문에 갑작스럽게 장애가 발생하여 서비스가 종료되더라도 프로세스를 재시작하여 안전하게 데이터를 재처리 할 수 있음
카프카 내부의 고가용성
- 일반적으로
Kafka클러스터는 3개 이상의 서버들로 운영- 이 경우에는 일부 서버에 장애가 발생하더라도 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있음
- 클러스터로 이루어진
Kafka는 데이터의 복제를 통해 고가용성의 특징을 가짐
- 프로듀서로 전송받은 데이터는 하나의 브로커에만 저장하는것이 아니라 여러 브로커에 저장하여 복제된 데이터를 기준으로 지속적으로 데이터 처리가 가능
- 이 때문에
Kafka내부의 장애가 발생하더라도 데이터의 유실에 대비할 수 있음
- 이 때문에
Data Lake Architecture
Data Lake Architecture( 데이터 레이크 아키텍처 )- 실시간 분석을 지원하는 빅데이터 아키텍쳐로써
Lambda Architecture( 람다 아키텍처 ) 라는 것이 일반적 - 대량의 데이터를 실시간으로 분석하기 어려우니 배치로 미리 만든 데이터와 실시간 데이터를 혼합해서 사용하는 방식
- 실시간 분석을 지원하는 빅데이터 아키텍쳐로써
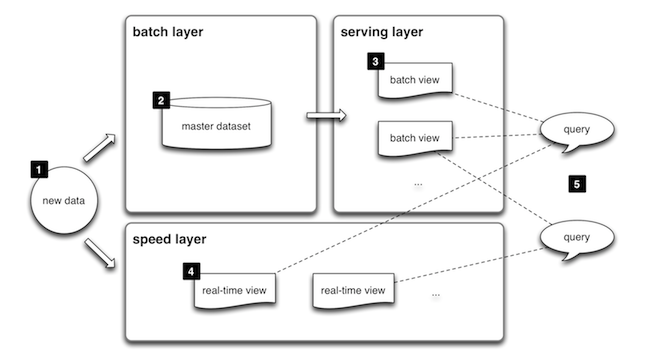
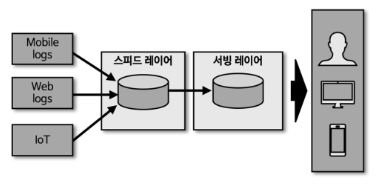
- 이 아키텍처는 총 3개의 레이어로 구성
- 배치 레이어는 이름 그대로 배치 데이터를 모아서 특정 이벤트마다 일괄 처리
- 서빙 레이어는 가공된 데이터를 사용자가 사용할 수 있게 데이터를 저장해둔 공간
- 스피드 레이어는 서비스에서 생성되는 원천 대이터를 실시간으로 분석하는 용도로 활용
- 배치 데이터에 비해 빠르게 분석해야 하는 경우 스피드 레이어를 통해 데이터를 분석
- 이 때 배치 처리를 하는 레이어와 실시간 처리를 하는 레이어를 분리함으로써 데이터 처리의 목적에 맞는 방식을 명확히 분리할 수 있음
- 하지만 레이어가 2개로 분리되면서 데이터를 처리하는데 필요한 로직이 각각의 레이어에 별개로 존재해야 하고 배치 데이터와 실시간 데이터를 섞어 사용해야 할 경우에는 다소 어려움을 겪게 되는 단점이 생김
- 이러한 단점을 해소하기 위해서
Kappa Architecture( 카파 아키텍처 ) 가 제안됨Lambda Architecture에서 단점으로 부각되었던 로직의 파편화 ∙ 디버깅 ∙ 배포 ∙ 운영 분리에 대한 이슈를 제거하기 위해 배치 레이어를 제거함Kappa Architecture는 스피드 레이어에서 데이터를 모두 처리할 수 있었으므로 이러한 중복 이슈를 해결할 수 있음
- 이렇게 될 경우에 기존의 배치 레이어가 하는 역할을 스피드 레이어가 대신해야 함
- 스피드 레이어의 데이터 처리 방식인 스트림 데이터를 배치 레이어가 사용하는 방식인 배치 데이터로 사용할 수 있어야 함
Kafka는 다음과 같은 방법으로 문제를 해결
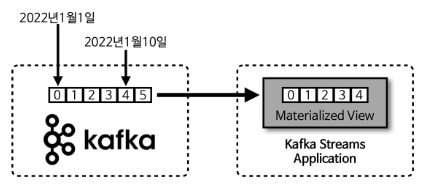
- 스트림 데이터를 배치 데이터로 사용하는 방법은 로그에 시간을 남기는 것
- 로그에 남겨진 시간을 기준으로 데이터를 처리하면 스트림으로 적재된 데이터도 배치로 처리할 수 있게 됨
- 예를 들어 2021년 신입생 목록을 배치 데이터로 가져오기 위해서 스트림 데이터로 적재된 1월 1일부터 12월 31일까지의 데이터를 구체화된 뷰로 가져온다면 배치로 처리할 수 있게 됨
Kafka는 로그에 시간 ( Timestamp ) 을 남기기 때문에 이런 방식의 처리가 가능
핵심 개념
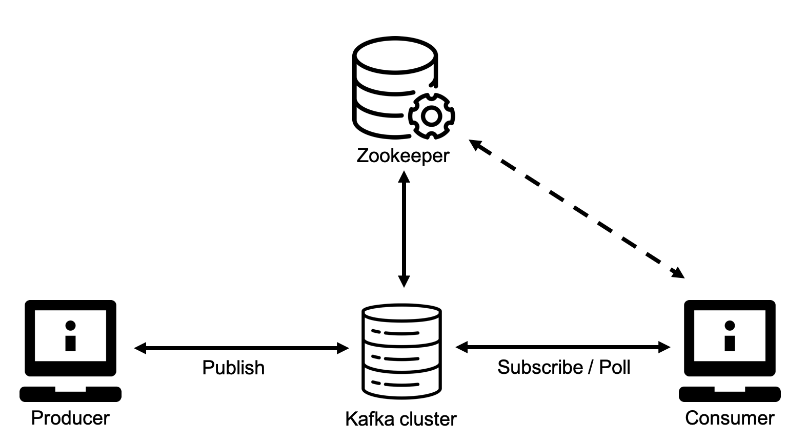
- 카프카 브로커는 클라이언트와 데이터를 주고 받기 위해 사용하는 어플리케이션
- 가장 기본이 되는 서버 어플리케이션이라고 생각하면 좋을 듯 하며 하나의 서버에는 한 개의 카프카 브로커만이 실행됨
- 카프카 브로커 서버 1대로도 기능은 동작하지만 일반적으로 데이터를 안전하게 보관하고 처리하기 위해서 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영
- 카프카 클러스터는 이 상위 개념으로써 이름 그대로 카프카의 브로커들을 포함하며 프로듀서들이 보낸 데이터를 여러 브로커에 분산 저장하거나 복제하는 역할을 수행
- 주키퍼는 분산 시스템에서 서버 및 시스템들 간의 여러 코디네이팅을 해주는 어플리케이션
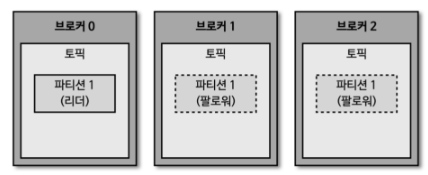
- 브로커 내에는 다시 토픽 ∙ 리더 파티션 ∙ 팔로워 파티션 ∙ 세그먼트 ∙ 레코드와 같은 분류가 존재
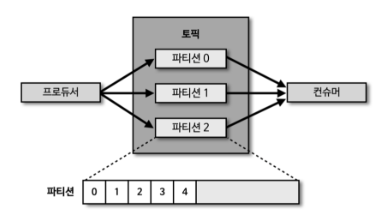
- 토픽은 목적에 따라 분리된 데이터 저장 공간으로써 브로커에 원하는 만큼 생성 할 수 있음
- 데이터베이스의 테이블과 유사한 역할을 하기 때문에 도메인 별로 분리될 수 있음
- 파티션은 토픽 안에 위치하며 논리적으로 저장되어 있는 데이터 저장 공간으로 오프셋을 할당 받아 저장됨
- 하나의 토픽 안에 여러 파티션들이 있을 수 있음
- 파티션들은 또 다른 브로커로 복제 가능한데 이렇게 생성한 파티션을 팔로워 파티션이라고 부름
- 이를 통해서 데이터의 가용성을 높일 수 있다는 강력한 장점 때문에 일반적으로는 2개 이상의 복제 개수를 설정하는 경우가 많음
- 다만 너무 많은 팔로워 파티션들은 쓰기 시에 오버헤드가 발생할 수 있고 복제 개수만큼 저장 용량이 증가 하기 때문에 적절한 값이 필요
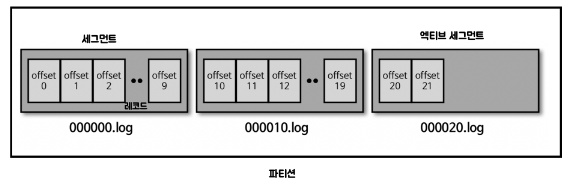
- 파티션은 다시 세그먼트로 나뉘는데 이는 실제로 메시지가 저장되는 파일 시스템 단위
- 세그먼트의 마지막 파일 즉, 쓰기가 현재 일어나고 있는 파일은 별도로 액티브 세그먼트라고 부름
- 현재 열려있는 파일은 분리된 상태에서 작업되어야 하기 때문에 이러한 분류가 있음
retention옵션에 따라 세그먼트를 어느 주기로 얼마만큼 보유하고 나머지를 삭제할 지 설정하는데 이 때 대부분의 경우 액티브 세그먼트는 이 정책에서 제외됨- 세그먼트들은 오프셋들을 할당받는데 이를 통해서 컨슈머들이 데이터를 어디까지 가지고 갔는지에 대한 여부를 알 수 있음
- 세그먼트의 마지막 파일 즉, 쓰기가 현재 일어나고 있는 파일은 별도로 액티브 세그먼트라고 부름
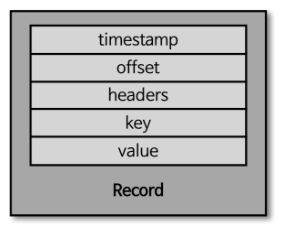
- 데이터를 나타내는 가장 작은 단위가 레코드
- 프로듀서가 생성한 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 저장되게 됨
- 이 때 한번 적재된 레코드는 수정할 수 없고
retention관리 등으로 삭제만 가능하기 때문에 입력 시에 의도한 대로 데이터가 들어오는지 확인해야 함
- 레코드 구성요소로는 타임스탬프 ∙ 헤더 ∙ 메시지 키 ∙ 메시지 값 ∙ 오프셋이 있음
- 타임 스탬프는 스트림 프로세싱에서 활용하기 위한 시간을 저장하는 용도로 사용됨
- 오프셋은 컨슈머에서 중복 처리를 방지하기 위한 구분자 역할을 하기 때문에 어디까지 처리를 완료했고 앞으로 처리해야할 데이터가 무엇인지를 구분하는 역할을 함
- 헤더는 key/value 데이터를 추가할 수 있으며 일반적으로는 레코드의 스키마 버전이나 포맷과 같은 데이터 프로세싱에 참고할만한 정보를 담아서 사용할 수 있음
- 레코드 키는 처리하고자 하는 메시지의 값을 분류하기 위한 용도로 사용할 수 있음
- 이를 파티셔닝이라고 부르는데 파티셔닝에서 사용하는 메시지 키는 파티셔너에 따라 토픽의 파티션 번호가 정해짐
- 메시지 키는 필수 값이 아니라 지정하지 않으면
null로 설정됨 - 메시지 키가
null인 경우에는 키 별로 파티셔닝이 불가능하므로 파티션에 라운드 로빈으로 전달되며null이 아닌 경우에는 해쉬값에 의해서 특정 파티션에 매핑되어 전달됨
- 레코드 값은 실제로 처리할 데이터가 담기는 공간
- 메시지 값의 포맷은 제네릭으로 사용자가 정할 수 있음
Float,Byte,String등 다양한 형태로 지정할 수 있으나 일반적으로는 직렬화에 어려움 때문에String을 가장 많이 쓰고 그 외 JSON 이 유용하게 쓰임- 브로커에 저장된 값의 포맷에 대해 컨슈머는 어떤 포맷으로 지정되어 있는지 알 방법이 없으므로 미리 역직렬화 포맷을 알고 있어야 함
It can’t get simpler than this: Set Up Kafka Cluster in AWS
AWS MSK secure Python Kafka client

🌱 Backend-Dev | hwaya2828@gmail.com