
Machine Learning
기계학습
- 하나를 가르치면 열을 안다
- 똑같은 문제뿐만 아니라 비슷한 문제도 해결할 수 있는 총명한 사람들을 두고 하는 말
- '이런 총기를 기계에 부여해서 스스로 결정하도록 할 수 없을까?' 라는 꿈을 꾼 사람들에 의해서 만들어진 기술이 바로 기계학습(Machine Learning)
- 머신러닝 때문에 두뇌가 필요 없어지는 것은 결코 아님
- 머신러닝은 우리의 두뇌가 가진 중요한 기능인 판단능력을 확장해서 우리의 두뇌가 더욱 빠르고 정확하게 결정할 수 있게 돕는 기가 막힌 도구
Tip! 참고 사이트
Teachable Machine
모델
- 머신러닝에서는 판단력이라는 표현 대신 모델(Model)이라는 용어를 사용
- 모델은 머신러닝을 이해하는 중요한 열쇠
- 머신러닝에서 이야기하는 모델의 의미를 이해했다면 머신러닝의 개념을 파악한 것이라고 할 수 있음
- 좋은 판단력은 나의 삶과 인류의 진보에 필수적인 도구
- 머신러닝이란 판단력을 기계에게 부여하는 기술이라고 할 수 있음
- 머신러닝을 만든 사람들은 이런 판단력을 모델(Model)이라고 부르기로 함
- 또 이 모델을 만드는 과정을 학습(Learning)이라고 부름
- 학습이 잘 되어야 좋은 모델을 만들 수 있고, 모델이 좋아야 더 좋은 추측을 할 수 있음
Tip! 참고 사이트
머신러닝머신 : Teachable Machine에서 생성한 모델을 이용해서 애플리케이션을 만들어주는 서비스
애플리케이션
- 애플리케이션(application)은 한국어로는 '응용'이라는 뜻
- 어떤 기능을 부품으로 사용해서 만든 완제품을 애플리케이션이라고 함
- '부품을 응용한 것'이라는 뜻
- 머신러닝머신에서 만든 것은 머신러닝의 모델이라는 부품을 응용해서 만든 소프트웨어
- 그런 점에서 머신러닝 애플리케이션이라고 할 수 있음
- 어떤 기능을 부품으로 사용해서 만든 완제품을 애플리케이션이라고 함
프로그램
- 우리가 만든 것을 프로그램(program)이라고도 함
- 프로그램이라는 말 속 깊은 곳에는 시간, 순서라는 의미가 포함되어 있음
- 생각해보면 우리가 하는 모든 일들이 시간의 흐름에 따라서 순서대로 일어남
- 시간의 순서에 따라서 동작하고 있는 것을 프로그램이라고 함
- 프로그램이라는 말 속 깊은 곳에는 시간, 순서라는 의미가 포함되어 있음
- 기계가 해야 할 일을 기계가 알아들을 수 있는 방식으로 순서대로 적으면 그것이 프로그램
- 기계는 그것을 보고 해야 할 일을 순서대로 실행할 것
- 이런 프로그램을 만드는 일을 프로그래밍(programming)이라고 함
- 그리고 프로그램을 만드는 사람을 프로그래머(programmer)라고 함
사물인터넷
- 요즘엔 전등이나 자동차와 같은 사물에도 컴퓨터가 들어감
- 사물에 컴퓨터가 들어가면 여러 가지 기능을 손쉽게 제어할 수 있음
- 전등불을 켤 수 있고 자동차 시동을 끌 수도 있음
- 그 컴퓨터가 인터넷에 연결되어 있다면 지구 반대편에서도 그 장치를 제어할 수 있음
- 다시 말해서 원격으로 조정할 수 있는 전등 앱, 자동차 앱을 만들 수 있다는 것
- 이것을 인터넷으로 사물을 제어한다는 의미에서 사물 인터넷(IoT, Internet of Things)이라고 함
데이터
- 머신러닝으로 무엇인가를 하려면 당연히 데이터가 필요
- 세상에는 무한히 많은 데이터가 있음
- 작은 세포 하나도 그 세포의 움직임을 관찰하기 위해서는 수많은 데이터가 필요
- 그런데 우리가 살고 있는 세계는 우주로 세포부터 은하까지 무수히 많은 존재들로 가득 차 있음
- 이 모든 것들은 데이터로 표현될 수 있으므로 우선 복잡한 현실에서 관심사만 뽑아서 단순한 데이터로 만들어야 함
- 세상에는 무한히 많은 데이터가 있음
- 현실을 데이터화 할 수 있다면 복잡한 현실에서 발견하기 어려운 통찰을 단순해진 데이터로부터 찾아낼 수 있을 것
- 이를 통해서 현실을 변화시키는 일을 하는 것이 데이터 산업
- 데이터 산업은 크게 데이터 과학(Science)과 데이터 공학(Engineering)으로 분리해볼 수 있음
- 데이터 과학은 데이터를 만들고 만들어진 데이터를 이용하는 일을 함
- 책에 비유한다면 작가라고 할 수 있음
- 데이터 공학은 데이터를 다루는 도구를 만들고 도구를 관리하는 일을 함
- 책에 비유한다면 종이와 연필을 만들고 책을 잘 출판하고 정리 정돈해서 도서관을 운영하는 것과 비슷
- 데이터 과학과 데이터 공학은 정신과 육체의 관계와 비슷
- 구분되는 것처럼 보이지만 한쪽이 없으면 다른 한쪽이 존재할 수 없기 때문에 사실은 하나라고 할 수 있음
표
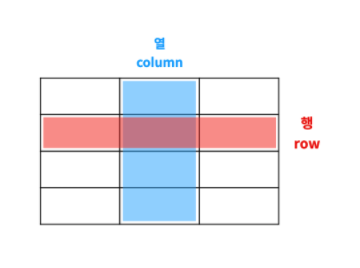
- 가로를 행이라고 하고 세로를 열이라고 함
- 행과 열이 표의 기본 구조
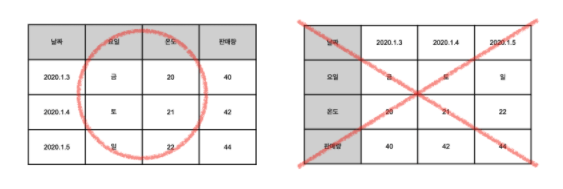
- 하지만 데이터 산업에서는 오른쪽처럼 하지 않음
- 왼쪽처럼 입력하자고 약속을 했으니 헷갈리지 말아야 함
- 표는 데이터들의 모임
- 그래서 표를 데이터 셋(data set)이라고도 부름
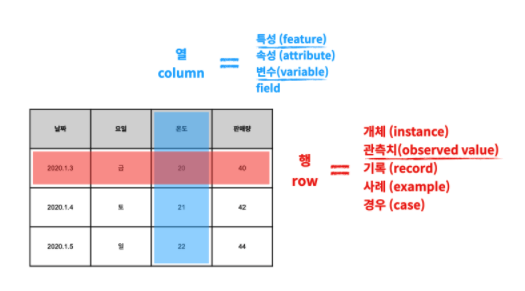
- 행 (row)
- 개체 (instance)
- 관측치 (observed value)
- 기록 (record)
- 사례 (example)
- 경우 (case)
- 열 (column)
- 특성 (feature)
- 속성 (attribute)
- 변수 (variable)
- field
변수
- 변수는 영어로 variable이라고 함
- '변할 수 있는'이라는 뜻
- 누군가 표에 대해서 이야기하면서 변수를 언급하면 그것은 열을 이야기하는 것
- 열을 변수라고 하는 이유
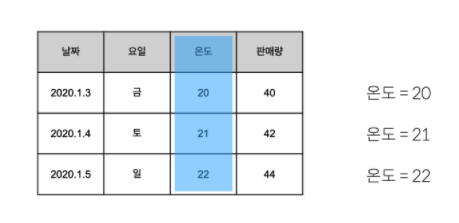
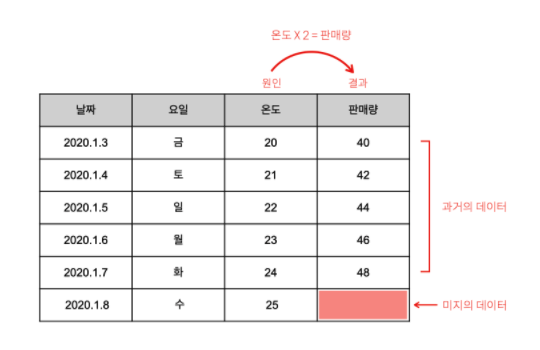
- 예를 들어서, 아래의 표에서 온도의 값은 이렇게 달라지고 있음
- 온도 = 20
- 온도 = 21
- 온도 = 22
- 예를 들어서, 아래의 표에서 온도의 값은 이렇게 달라지고 있음
- 열을 변수라고 하는 이유
독립변수와 종속변수
- 독립변수 = 원인이 되는 열
- 종속변수 = 결과가 되는 열
- 예를 들어서, '온도가 20도일 때 40잔이 팔렸다.'
- 여기서 원인은 온도 20도이고 결과는 판매량 40잔
- 잘 생각해보면 원인은 결과와 상관없이 일어나는 사건
- 판매량 때문에 온도가 달라질리가 없음
- 결과에 영향을 받지 않는 독립적인 사건
- 하지만 결과는 원인에 종속되어서 발생한 사건
- 여기서 원인은 온도 20도이고 결과는 판매량 40잔
- 그래서 원인은 독립적이기 때문에 독립변수, 결과는 원인에 종속되어 있기 때문에 종속변수라고 함
상관관계
- 서로 상관있는 특성들은 이런 징후가 있음
- 한쪽의 값이 바뀌었을 때, 다른 쪽의 값도 바뀐다면 두 개의 특성은 '서로 관련이 있다'고 추측할 수 있음
- 이 때, 두 개의 특성을 '서로 상관이 있다'고 하며 이런 관계를 '상관관계'라고 함
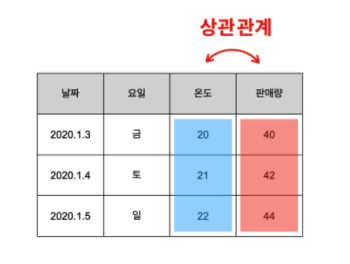
- 예를 들어서, 위의 표에서 온도와 판매량은 서로 상관관계가 있다고 의심해볼 수 있음
- 온도와 판매량이 같이 변하고 있음
인과관계
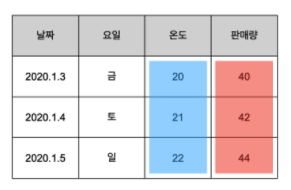
- 위의 표를 잘 살펴보면 온도와 판매량 사이에 보다 미묘한 관계가 있는 것을 관찰할 수 있음
- 온도와 판매량이 같이 커지고 작아지고 있음을 발견
- 판매량이 달라지니 온다가 달라짐: 이상
- 온도가 달라지니 판매량이 달라짐: 가능
- 온도의 2배가 판매량이 되는 일정한 패턴이 발견됨
- 온도와 판매량이 같이 커지고 작아지고 있음을 발견
- 이런 사실을 종합하면 '온도'는 '원인'이고, '판매량'은 '결과'라고 할 수 있음
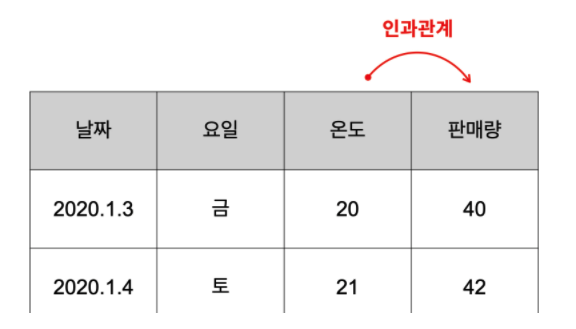
- 이렇게 각 열이 원인과 결과의 관계일 때 인과관계가 있다고 함
- 상관관계와 인과관계는 비슷한 듯 하지만 중요한 차이가 있음
- 상관관계는 인과관계를 포함
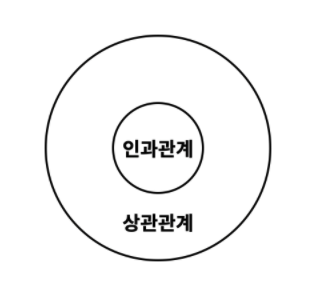
- 즉, 모든 인과관계는 상관관계
- 하지만 모든 상관관계가 인과관계인 것은 아님
- 특성들 사이의 관계를 파악하는 것은 매우 어렵고, 조심스럽게 접근해야 하는 작업
- 적은 수의 데이터를 가지고 상관관계가 있다고 단정하면 안됨
- 또 단지 서로 상관관계를 맺고 있을 뿐인데, 그것을 인과관계라고 단정해도 안 됨
Tip! 정리
- 독립변수는 원인
- 종속변수는 결과
- 독립변수와 종속변수의 관계를 인과관계라고 함
- 인과관계는 상관관계에 포함됨
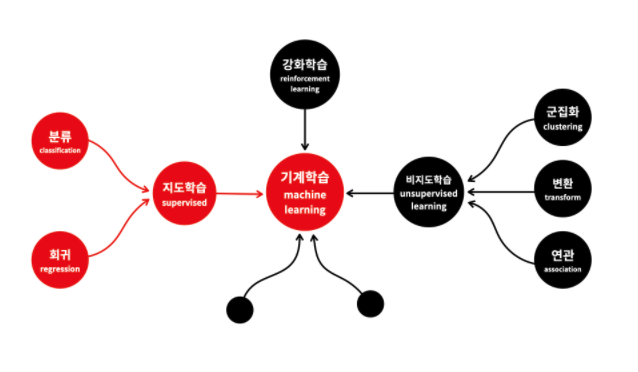
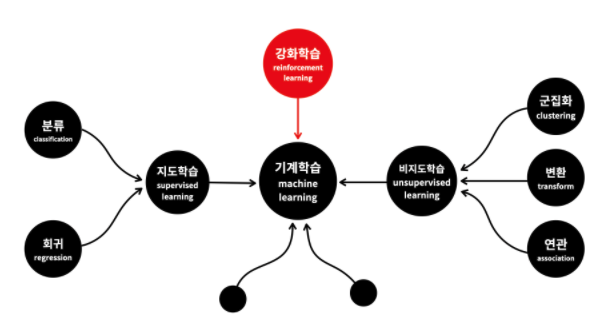
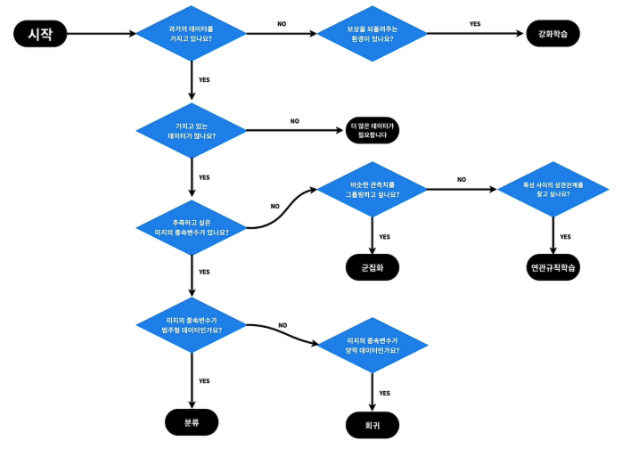
기계학습의 분류
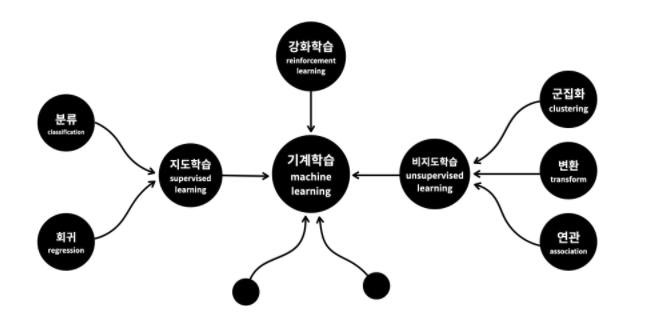
- 지도학습의 '지도'는 기계를 가르친다(supervised)는 의미
- 마치 문제집을 푸는 것과 비슷
- 문제집에는 문제가 있고, 정답이 있음
- 문제와 정답을 비교하고 맞추다 보면 문제풀이에 익숙해지게 됨
- 이후에 비슷한 문제를 만나면 오답에 빠질 확률은 점점 낮아짐
- 문제집으로 학생을 가르치듯이 데이터로 컴퓨터를 학습시켜서 모델을 만드는 방식을 '지도학습'이라고 함
- 마치 문제집을 푸는 것과 비슷
- 비지도학습은 지도학습에 포함되지 않는 방법들
- 여기에 속하는 도구들은 대체로 기계에게 데이터에 대한 통찰력을 부여하는 것이라고 이야기할 수 있음
- '통찰'의 사전적 의미는 '예리한 관찰력으로 사물을 꿰뚫어 봄'
- 즉, 누가 정답을 알려주지 않았는데도 무언가에 대한 관찰을 통해 새로운 의미나 관계를 밝혀내는 것이라고 할 수 있음
- 데이터의 성격을 파악하거나 데이터를 잘 정리정돈 하는 것에 주로 사용됨
- 여기에 속하는 도구들은 대체로 기계에게 데이터에 대한 통찰력을 부여하는 것이라고 이야기할 수 있음
- 강화학습은 학습을 통해서 능력을 향상시킨다는 점에서는 지도학습이랑 비슷
- 차이점은 지도학습이 정답을 알려주는 문제집이 있는 것이라면,
강화학습은 어떻게 하는 것이 더 좋은 결과를 낼 수 있는지를 스스로 느끼면서 실력 향상을 위해서 노력하는 수련과 비슷 - 경험을 통해 '더 좋은 답'을 찾아가는 것
- 마치 게임 실력을 키우는 것과 같음
- 게임에는 룰이 있고, 룰에 따라 어떤 행동을 하면, 그 결과에 따라서 상이나 벌을 받음
- 더 큰 상을 받기 위한 과정을 끝없이 반복하다 보면 그 게임의 고수가 됨
- 이런 과정을 기계에게 시켜서 기계 스스로가 고수로 성장하도록 고안된 방법이 강화학습이라고 할 수 있음
- 차이점은 지도학습이 정답을 알려주는 문제집이 있는 것이라면,
Tip! 정리
- 지도학습
- 정답이 있는 문제를 해결하는 것
- 비지도학습
- 무언가에 대한 관찰을 통해 새로운 의미나 관계를 밝혀내는 것
- 강화학습
- 더 좋은 보상을 받기 위해서 수련하는 것
지도학습
- 지도학습은 '역사'와 비슷
- 역사에는 과거에 있었던 사건이 원인과 결과로 기록되어 있음
- 역사를 알면 어떤 사건이 일어났을 때, 그것의 결과로 어떤 일이 일어날지를 예측할 수 있게 됨
- 마찬가지로 지도학습은 과거의 데이터로부터 학습해서 결과를 예측하는 데에 주로 사용됨
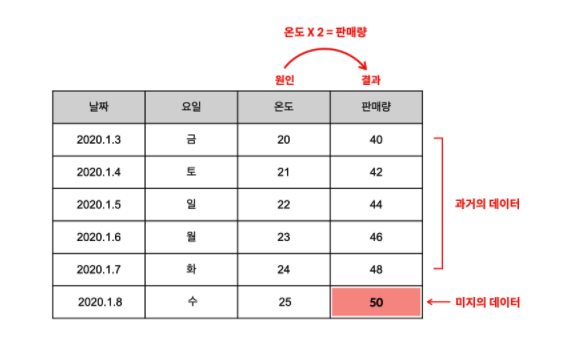
- 예를 들어서, 위의 표에서 일기예보를 보니 1월 8일에 온도가 25도라고 했을 때 우리가 궁금한 것은 1월 8일에는 레모네이드 몇 잔이 판매될지를 예측하는 것
- 그래야 레몬이 몇 개가 필요한지 알 수 있음
- 즉, 과거에 대한 학습을 통해서 미지의 데이터를 추측하고 싶은 것
- 이때 머신러닝의 지도학습이 이용될 수 있음
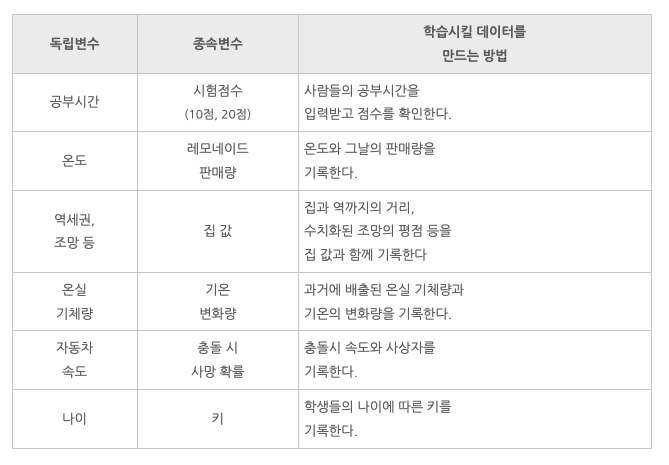
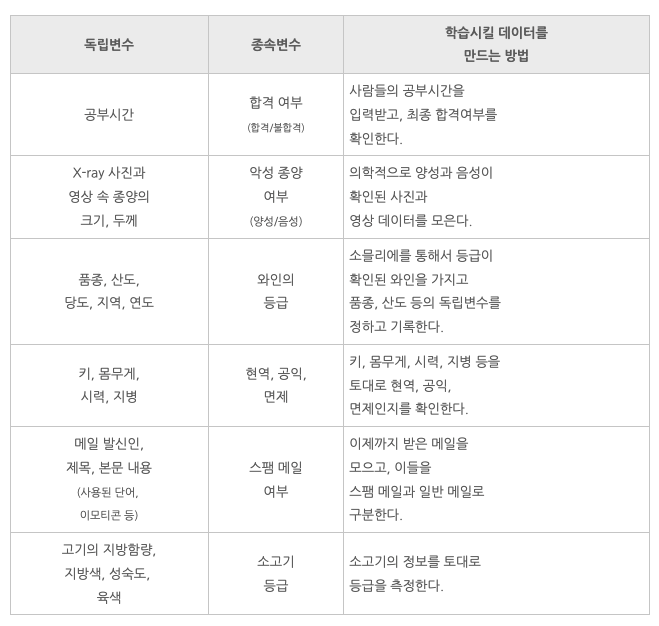
- 머신러닝의 지도학습을 이용하기 위해서는 우선 충분히 많은 데이터를 수집해야 함
- 데이터는 독립변수와 종속변수로 이루어져 있어야 함
- 이것을 지도학습으로 훈련시키면 컴퓨터는 모델을 만듬
온도 X 2 = 판매량- 일단 모델이 만들어지면 모델을 사용하면 되는데 이 모델에 온도를 입력하면 판매량을 예측 할 수 있음
- 만약 내일의 온도가 25도라면 몇 잔이 판매될까?
25도 X 2 = 50개
- 만약 내일의 온도가 25도라면 몇 잔이 판매될까?
- 즉, 머신러닝의 지도학습을 이용하면
온도X2라는 모델을 컴퓨터가 알아서 만들어주는 것
- 지도학습을 하기 위해서는 우선 과거의 데이터가 있어야 함
- 그리고 그 데이터를 독립변수(원인)와 종속변수(결과)로
분리해야 함
- 그리고 그 데이터를 독립변수(원인)와 종속변수(결과)로
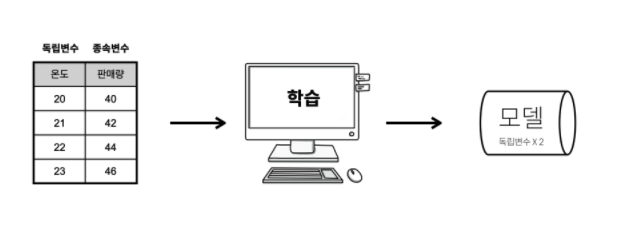
- 독립변수와 종속변수의 관계를 컴퓨터에게 학습시키면 컴퓨터는 그 관계를 설명할 수 있는 공식을 만들어냄
- 이 공식을 머신러닝에서는 '모델'이라고 함
- 좋은 모델이 되려면 데이터가 많을수록, 정확할수록 좋음
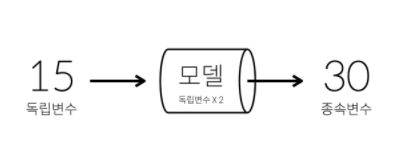
- 일단 모델을 만들면 아직 결과를 모르는 원인을 모델에 입력했을 때 결과를 순식간에 계산해서 알려줌
지도학습: 회귀 VS 분류
- 지도학습은 크게 '회귀'와 '분류'로 나뉨
- 회귀는 영어로 Regression이고, 분류는 Classification
회귀 (Regression)
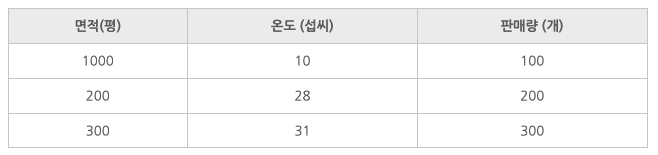
- 예측하고 싶은 종속변수가 숫자일 때 보통 회귀라는 머신러닝의 방법을 사용
- 레모네이드 예제가 바로 회귀를 이용한 것
- 우리가 예측하고 싶은 1월 8일의 판매량은 어떤 형태의 데이터인가?
숫자 - 숫자를 예측하고 싶다면 회귀 사용
- 우리가 예측하고 싶은 1월 8일의 판매량은 어떤 형태의 데이터인가?
- 회귀의 여러 사례
분류 (Classification)
- 어떤 문제를 만났는데 그 문제에서 추측하고 싶은 결과가 이름 혹은 문자라면 분류라는 방법을 이용
- 분류의 여러 사례
Tip! 정리
- 가지고 있는 데이터에 독립변수와 종속변수가 있고, 종속변수가 숫자일 때 회귀를 이용하면 됨
- 가지고 있는 데이터에 독립변수와 종속변수가 있고, 종속변수가 이름일 때 분류를 이용하면 됨
양적 데이터와 범주형 데이터
- 산업에서는 숫자라는 다소 모호한 표현 대신에 '양적'이라는 말을 많이 사용
- 즉, 얼마나 큰지, 얼마나 많은지, 어느 정도인지를 의미하는 데이터라는 뜻에서 '양적'(量的, Quantitative)이라고 함
- 누가 양적 데이터라고 말했다면 숫자라고 알아들으면 됨
- 즉, 얼마나 큰지, 얼마나 많은지, 어느 정도인지를 의미하는 데이터라는 뜻에서 '양적'(量的, Quantitative)이라고 함
- 또 산업에서는 이름이라는 표현 대신에 '범주'(範疇, Categorical)라는 말을 사용
양적 데이터
- 종속변수가 양적 데이터라면 회귀를 사용하면 됨
범주형 데이터
- 종속변수가 범주형 데이터라면 분류를 사용하면 됨
비지도학습
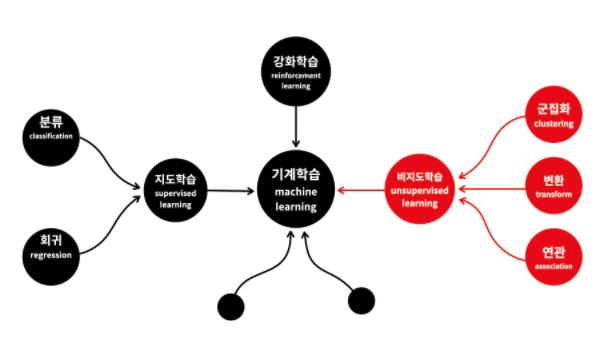
- 비지도 학습의 사례로는 '군집화'와 '연관 규칙 학습'이라는 것이 있음
- 군집화는 영어로 Clustering이고, 연관 규칙 학습은 Association rule learning
군집화 (Clustering)
- 군집화는 비슷한 것들을 찾아서 그룹을 만드는 것
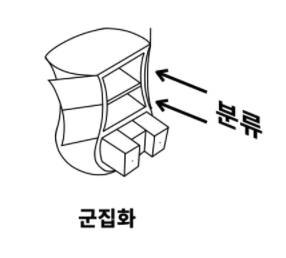
- 비슷한 것들끼리 모아서 적당한 그룹을 만드는 것이 군집화
- 그룹을 만들고 난 후에는 각각의 물건을 적당한 그룹에 위치시키는 것이 분류
- 어떤 대상들을 구분해서 그룹을 만드는 것이 군집화라면, 분류는 어떤 대상이 어떤 그룹에 속하는지를 판단하는 것
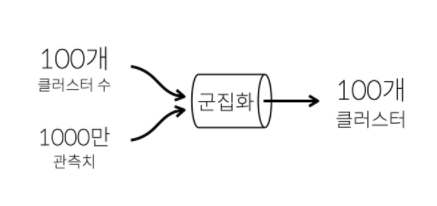
- 예를 들어서, 배달 사업의 경우 서비스를 이용하는 사용자가 전국적으로 1000만명이 있다고 가정
- 아래 표는 1000만명의 위치(
위도,경도)를 표시하고 있는 표 - "100개의 배달본부를 오픈하려고 하는데 어디에 배치하면 좋을까?"
- 이 질문에 답 하기 위해서는 1000만명이 적절히 분포되어 있는 100개의 그룹을 만들어야 함
- 이런 그룹을 한국어로는 군집, 영어로는 cluster라고 함
- 군집을 만드는 것을 군집화, 영어로는 clustering이라고 함
- 표의 숫자만 보고 군집화를 하는 것은 쉽지 않은데 이때 우리를 구원해줄 도구가 좌표평면
- 아래 표는 1000만명의 위치(
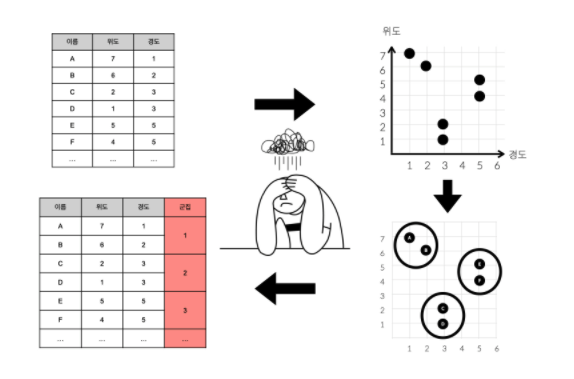
- 그런데 표의 행(
A,B,C,D,E,F)이 6개가 아니라 1000만개라면 어떨까?- 또 열이 2개(
위도,경도)가 아니라 100개라면 위 예제처럼 x, y 축으로 이루어진 2차원의 좌표평면에 표현하는 것이 불가능 - 심지어 행의 값이 계속해서 추가되고, 수정되고, 삭제 된다면?
- 또 열이 2개(
- 이런 데이터 지옥 속에서 우리를 구원해줄 도구가 바로 머신러닝, 그 중에서 비지도 학습, 그 중에서 군집화
- 군집화라는 도구에 1000만개의 관측치(행)를 입력하고 100개의 클러스터가 필요하다고 알려주면, 유사한 속성을 가진 관측치끼리 분류하여 총 100개의 클러스터를 만들어줌
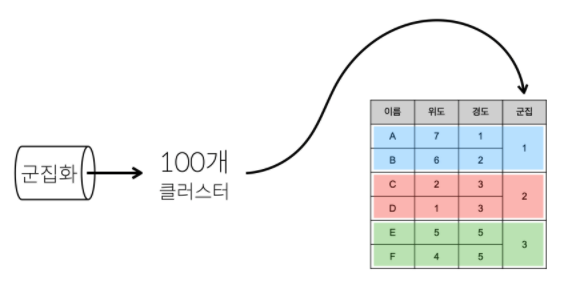
- 잘 생각해보면 군집화는 서로 가까운 관측치를 찾아주는 머신러닝의 기법이라는 것을 알 수 있음
- 좌표상에서 가깝다는 것은 데이터가 서로 비슷하다는 의미와 같음
Tip! 정리
- 군집화
- 비슷한 행을 그룹핑하는 것
연관 규칙 학습 (Association rule learning)
- 연관 규칙 학습은 서로 연관된 특징을 찾아내는 것
- 일명 장바구니 분석이라고 불림
- 이제부터 여러분은 온라인 쇼핑몰의 사장이며 더 많은 상품을 판매하기 위해서 고민 중임
- 고객의 장바구니에 담긴 상품을 바탕으로 관심을 가질만한 상품을 추천하면 더 많은 상품을 판매할 수 있겠다는 생각을 하게 되었는데 이럴 때는 표를 봐야함
- 아래는 지금까지 판매 내역
- 하나 이상 구매했다면 O, 구매하지 않았다면 X
- 고객의 장바구니에 담긴 상품을 바탕으로 관심을 가질만한 상품을 추천하면 더 많은 상품을 판매할 수 있겠다는 생각을 하게 되었는데 이럴 때는 표를 봐야함
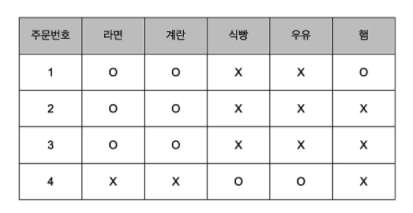
- 유심히 보면 라면을 구입한 사람은 계란을 구입할 확률이 높음
- 즉, 라면과 계란은 서로 연관성(Association)이 높다는 것을 알 수 있음
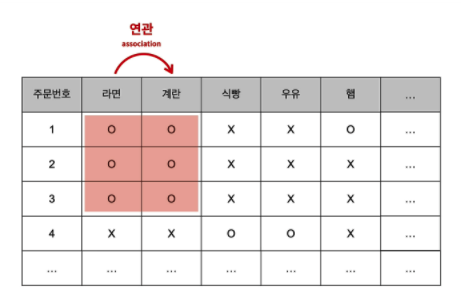
- 연관성을 파악할 수 있다면, 고객이 미처 구입하지 못했지만 구입할 가능성이 매우 높은 상품을 추천해줄 수 있음
- 이 정도 양의 데이터라면 라면과 계란의 상관관계를 사람이 직접 찾을 수도 있음
- 그런데 판매하는 제품의 종류가 1만개이고, 하루에 1000만 명이 여러분의 쇼핑몰을 이용한다고 상상하면 제품들 간의 연관성을 사람이 찾아내는 것은 정말 어려운 일
- 이것을 기계가 대신해줄 수 있는데 이때 우리를 구원해줄 수 있는 도구가 바로 연관 규칙
- 잘 생각해보면 연관 규칙은 서로 관련이 있는 특성(열)을 찾아주는 머신러닝의 기법이라는 것을 알 수 있음
Tip! 정리
- 군집화
- 관측치(행)을 그룹핑 해주는 것
- 연관 규칙 학습
- 특성(열)을 그룹핑 해주는 것
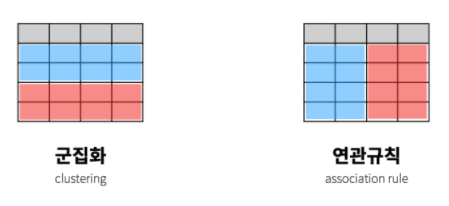
지도학습과 비지도학습의 차이점

- 비지도학습은 탐험적
- 탐험이 미지의 세계를 파악하는 것이듯, 데이터들의 성격을 파악하는 것이 목적
- 독립변수와 종속변수의 구분이 중요하지 않으며 데이터만 있으면 됨
- 지도학습은 역사적
- 과거의 원인과 결과를 바탕으로 결과를 모르는 원인이 발생했을 때 그것은 어떤 결과를 초래할 것인가를 추측하는 것이 목적
- 그래서 원인인 독립변수와 결과인 종속변수가 꼭 필요
강화학습
- 강화학습은 영어로는 Reinforcement Learning이라고 하는데 Reinforcement 강화, 증강이라는 뜻
- 강화학습의 핵심은 일단 해보는 것

- 비유하자면 지도학습이 배움을 통해서 실력을 키우는 것이라면, 강화학습은 일단 해보면서 경험을 통해서 실력을 키워가는 것
- 그 행동의 결과가 자신에게 유리한 것이었다면 상을 받고, 불리한 것이었다면 벌을 받는 것
- 게임 실력을 키워가는 것도 강화학습과 비슷
- 여기서는 두 개의 주체를 생각해봐야 함
- 우선 게임이 있어야 하고 게임은 게이머에게 보여줄 화면이 필요
- 또 하나의 주인공은 게이머이며 게이머는 우선 현재의 상태를 관찰해야 함
- 관찰 결과에 따라서 게임을 조작하는 행동을 해야 함
- 관찰과 행동을 하기 위해서는 판단력이 필요
- 여기서는 두 개의 주체를 생각해봐야 함
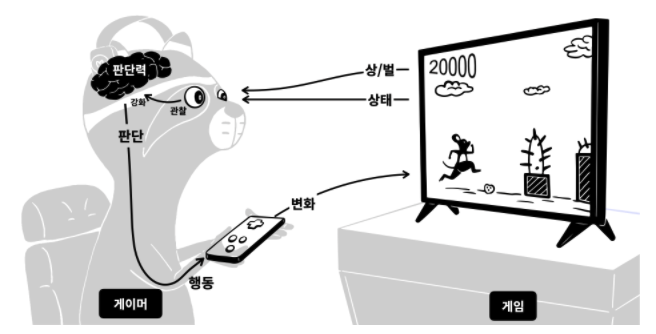
- 게임의 실력을 키워가는 과정
- 우선 게임은 게이머에게 현재의 상태를 보여줌
- 캐릭터는 어디에 있고, 장애물은 어디에 있는지 알려줌
- 동시에 현재의 점수도 알려줌
- 게이머는 이 값이 높아지는 것이 상이고, 장애물에 부딪히는 것이 벌
- 관찰의 결과에 따라서 어떤 상태에서 어떻게 행동해야 더 많은 상을 받고, 더 적은 벌을 받을 수 있는지를 알게 됨
- 즉, 판단력이 강화
- 판단에 따라서 행동을 함
- 그 행동은 게임에 변화를 주게 됨
- 우선 게임은 게이머에게 현재의 상태를 보여줌
- 이런 과정을 반복하면 판단력이 점점 강화되는데 이것이 현실에서 게임의 실력자가 되는 과정
- 생각해보면 배우지 않고도 결국에 잘하게 되는 많은 일들이 이런 과정을 통해서 이루어짐
- 강화학습은 이러한 과정을 모방해서 기계를 학습시키는 것
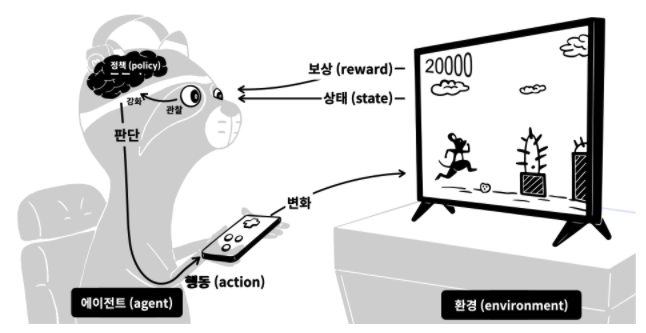
- 강화학습의 경우
- 게임 → 환경 (environment)
- 게이머 → 에이전트 (agent)
- 게임화면 → 상태 (state)
- 게이머의 조작 → 행동 (action)
- 상과 벌 → 보상 (reward)
- 게이머의 판단력 → 정책 (policy)
- 강화학습에서는 더 많은 보상을 받을 수 있는 정책을 만드는 것이 핵심
- 이렇게 만들어진 정책은 게임의 인공지능 플레이어를 만드는 데 사용될 수 있음
- 바둑으로 인간을 이긴 알파고가 바로 강화학습을 통해서 구현된 소프트웨어
- 자동차의 자율주행 기능도 강화학습을 이용해서 만들어짐
- 이렇게 만들어진 정책은 게임의 인공지능 플레이어를 만드는 데 사용될 수 있음
Tip! 추가 내용
- 판단의 지도

🌱 Backend-Dev | hwaya2828@gmail.com