
MongoDB
- MongoDB 프로그래밍 강의 정리
NOSQL 특징
NOSQL 등장 배경
- 기존 컴퓨팅 시스템 특징
- 기업 업무를 자동화하고 효율화하는 목적
- 기업의 복잡한 데이터를 저장하고 그 데이터 간의 관계를 정의하고 분석하는데 최적화
- 기업의 업무 시스템은 해당 기업의 생산과 판매를 지원하기 위한 것
- 생성되는 데이터 양은 한계를 가지고 있음
- ① 2000년대에 들어서면서 인터넷의 발전과 함께 SNS 서비스가 활성화
- ② SNS 서비스 시스템은 전세계 사용자 대상의 서비스로 발전
- ③ 기존의 기업 시스템에서 볼 수 없었던 대규모 데이터를 생산
- ④ 이러한 데이터들은 기존 기업 데이터에 비해 매우 단순한 형태를 가짐
- 데이터의 패러다임이 한정된 규모의 복잡성이 높은 데이터에서 단순한 대량의 데이터로 넘어가기 시작했음
- 기존의 데이터 저장 시스템으로는 커버할 수 없는 여러 가지 한계를 야기했고 결국에는 새로운 형태의 데이터 저장 기술을 요구하게 되었음
- 대표적인 인터넷 기업이면서 대용량 단순 데이터를 가장 많이 보유했기 때문에, 단순한 대용량 데이터 처리에 대한 요구가 가장 많은 구글과 아마존에 의해 빅테이블(Bigtable)과 Dynamo라는 논문이 발표되었음
- 이 두 논문은 새로운 데이터 자장 기술을 만들어내는 시발점이 되었고, 기존의 오라클 등으로 대변되는 RDBMS 중심의 데이터 저장 기술 시장에 새로운 데이터 저장 기술인 NoSQL이 등장하는 계기가 됨
- NoSQL은 Not Only SQL의 약자로 기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미함
NOSQL 특징
-
NoSQL 이라고 해서 RDBMS 제품군 (MS-SQL, Oracle, Sybase, MySQL) 등과 같이 공통된 형태의 데이터 저장 방식(테이블)과 접근 방식(SQL)을 갖는 제품군이 아니라 RDBMS와 다른 형태의 데이터 저장 구조를 총칭하며, 제품에 따라 각기 그 특성이 매우 달라서 NoSQL을 하나의 제품군으로 정의할 수는 없음
-
관계형 데이터베이스인 RDBMS가 데이터의 관계를 Foreign Key 등으로 정의하고 이를 이용해 Join 등의 관계형 연산을 하지만, NoSQL은 데이터 간의 관계를 정의하지 않음
-
RDBMS의 복잡도와 용량 한계를 극복하기 위한 목적으로 등장한 만큼, 페타바이트급의 대용량 데이터를 저장할 수 있음
-
NoSQL은 기존의 RDBMS처럼 하나의 고성능 머신에 데이터를 저장하는 것이 아니라, 일반적인 서버(인텔 계열의 CPU를 사용하는 Commodity Server) 수십 대를 연결해 데이터를 저장 및 처리하는 구조를 가짐
-
분산형 구조를 통해 데이터를 여러 대의 서버에 분산해 저장하고, 분산 시에 데이터를 상호 복제해 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 없는 형태임
-
NoSQL은 RDBMS와는 다르게 테이블의 스키마가 유동적임
-
ID로 사용하는 키 부분에만 타입이 동일하고, mandatory(생략되지 않는) 필드로 지정하면 값에 해당하는 컬럼은 어떤 타입이든, 어떤 이름이 오든 허용됨 (ID 필드는 공통이지만, 데이터를 저장하는 컬럼은 각기 다른 이름과 다른 데이터 타입을 가질 수 있음)
- NoSQL은 분산형 구조를 띠고 있기 때문에 분산 시스템의 특징을 그대로 방영하며 대부분 CAP 이론을 따름
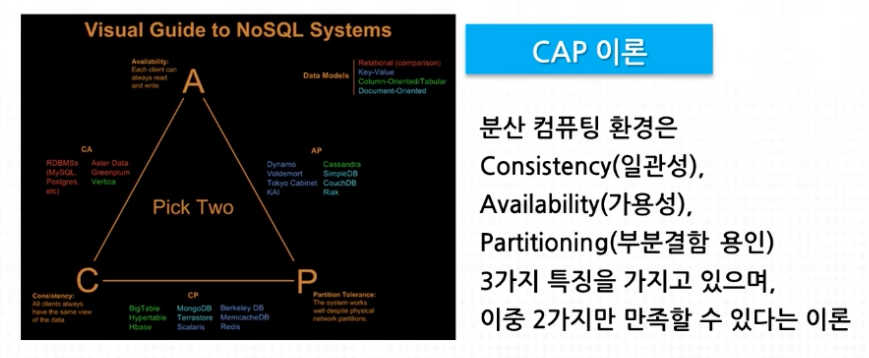
NOSQL 종류
Key / Value Store
- 대부분의 NoSQL은 Key / Value 개념을 지원
- Unique Key에 하나의 Value를 가지고 있는 형태
- put(key, value), value:= get(key) 형태 API 사용

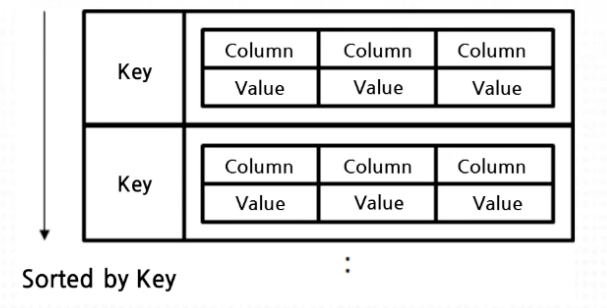
Ordered Key / Value Store
- 데이터가 내부적으로 Key를 순서로 Sorting되어 저장됨
- Key 안에 (column: value) 조합으로 된 여러 개의 필드를 가지는 구조
- 대표 제품: Hbase, Cassandra
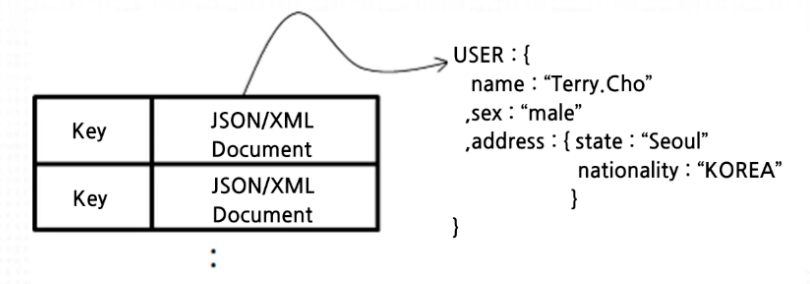
Document Key / Value Store
- Key / Value Store의 확장된 형태
- 저장되는 Value의 데이터 타입으로 "Document"라는 구조화된 데이터 타입(JSON, XML, YAML 등)을 사용
- 복잡한 계층구조 표현 가능
- 제품에 따라 추가 기능(Sorting, Join, Grouping) 지원
NoSQL System List
- Key-Value Stores: Oracle Coherence, Redis, Kyoto Cabinet
- BigTable-style Databases: Apache HBase, Apache Cassandra
- Document Databases: MongoDB, CouchDB
- Full Text Search Engines: Apache Lucene, Apache Solr
- Grapg Databases: neo4j, FlockDB
NOSQL 장점 / 단점
Relational modeling
- 전형적으로 가용한 데이터 구조에 기반
- "내가 가지고 있는 답이 무엇인가?" ("What answer do I have?")
- 데이터 모델 정의 후, 어플리케이션에 맞는 쿼리 개발
- RDBMS 모델링 기법
- 저장하고자 하는 도메인 모델 분석
- 개체 간의 관계(relationship) 식별
- 테이블 추출
- 테이블을 이용한 쿼리 구현
NoSQL data modeling
- 어플리케이션 특징적인 데이터 접근 패턴에 따라 모델링
- "내가 가지고 있는 질문은 무엇인가?" ("What questions do I have?")
- 어플리케이션의 필요한 쿼리와 성능을 정의한 이후, 요구 사항에 부합하도록 데이터 모델을 구성
- NoSQL 데이터 모델링 기법
- 도메인 모델 분석
- 쿼리 결과 도출
- 테이블(데이터 저장 모델) 설계
NOSQL 모델링 특징
- 관계형 데이터베이스 모델링 보다 더 깊은 데이터 구조 및 접근 알고리즘에 대한 이해가 필요함
- NoSQL 쿼리가 실제 몇 개의 물리 노드에 걸쳐서 수행되는지에 대한 이해가 있어야 제대로된 쿼리 디자인이 가능함
- NoSQL 디자인은 DB와 어플리케이션 뿐만 아니라 인프라(네트워크, 디스크)에 대한 디자인을 함께 해야 함
- 대부분의 NoSQL DB는 인증이나 인가 체계가 없어서 보안에 매우 취약하기 때문에 별도의 보안 체계를 마련해야 함 (방화멱이나 Reverse Proxy 등)
RDBMS 장점
- 범용적이며 고성능
- 대부분의 경우에 관계형 데이터 베이스를 사용하는 것이 가장 안정적
- 데이터의 일관성을 보증할 수 있음 (트랜잭션)
- 한번에 이뤄져야 하는 작업의 경우 데이터 불일치 상황을 방지
- 정규화를 전제로 하고 있기 때문에 업데이트시 비용이 적음
- 동일 컬럼은 동일 장소에 존재
- 데이터베이스 설계시 이미 불필요한 중복이 삭제됨
- 복잡한 형태의 쿼리도 가능 (Join 등)
- 이미 성숙한 기술
RDBMS 단점
- 대량의 데이터 입력 처리
- 테이블의 인덱스 생성이나 스키마 변경시
- 개발 / 운영시 컬럼을 확정 짓기 어려운 경우
- 인덱스 = 데이터 검색을 빠르게 하기 위해 테이블마다 키값 기반 색인 작업
- 스키마 = 데이터 구조와 데이터 타입, 관계 등을 정의한 세부 명세
NOSQL 장점
- NoSQL은 특정 용도로 특화되어있음
- 그래서 각 NoSQL의 솔루션의 특징을 알 필요가 잇음
- 데이터 분산에 용이
- 기본적으로 NoSQL의 join 연산은 대부분 불가능함
- 즉 데이터 모델 자체가 독립적으로 설계되어있어 데이터를 여러 서버에 분산시키는 것이 용이함
- 데이터에 대한 캐시가 필요한 경우
- 배열 형식의 데이터를 고속으로 처리할 필요가 있는 경우
- 어쨌든 모든 데이터를 저장하고 싶은 경우
NOSQL 단점
- 각 솔루션의 특징을 이해할 필요가 있음
- 아직 새로운 기술로 운영 노하우가 적음
- 버그가 상대적으로 많이 있는 상태
- 업체마다 고유의 특색을 살린 NoSQL을 개발해 공개하는 경우가 많아 새로운 솔루션이 계속 출시되는 상태
학습정리
- NOSQL
- Not Only SQL의 약자로 기존 RDBMS 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미함
- NOSQL 종류
- Redis, Apache HBase, Apache Cassandra, MongoDB
- NOSQL 장점
- 데이터모델 자체가 독립적으로 설계되어있어 데이터를 분산시키는 것이 용이하고, 배열 형식의 데이터를 고속으로 처리하는 것이 가능함
