
그래프 탐색 알고리즘
Tip! 자료구조와 알고리즘
- 자료구조란 데이터의 표현 및 저장 방법
- 프로그램이란 데이터를 표현하고 그렇게 표현된 데이터를 처리하는 것
- 여기서 데이터의 표현은 데이터의 저장을 포함하는 개념이며 데이터의 저장을 담당하는 것이 자료구조
- 데이터 처리는 알고리즘, 즉 문제의 해결 방법을 뜻함
탐색 알고리즘
- 탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 의미
- 탐색 알고리즘의 종류는 굉장히 다양한데 그 중 DFS와 BFS는 그래프 탐색 알고리즘 ( Graph Traversal Algorithm ) 에 속함
- 그래프 탐색 알고리즘이란 그래프의 모든 꼭짓점 ( Node 또는 Vertex ) 을 방문하는 알고리즘을 의미
- 트리 탐색은 ( Tree Traversal ) 그래프 탐색의 특수한 일종이며 방문한 노드는 다시 방문하지 않음
그래프
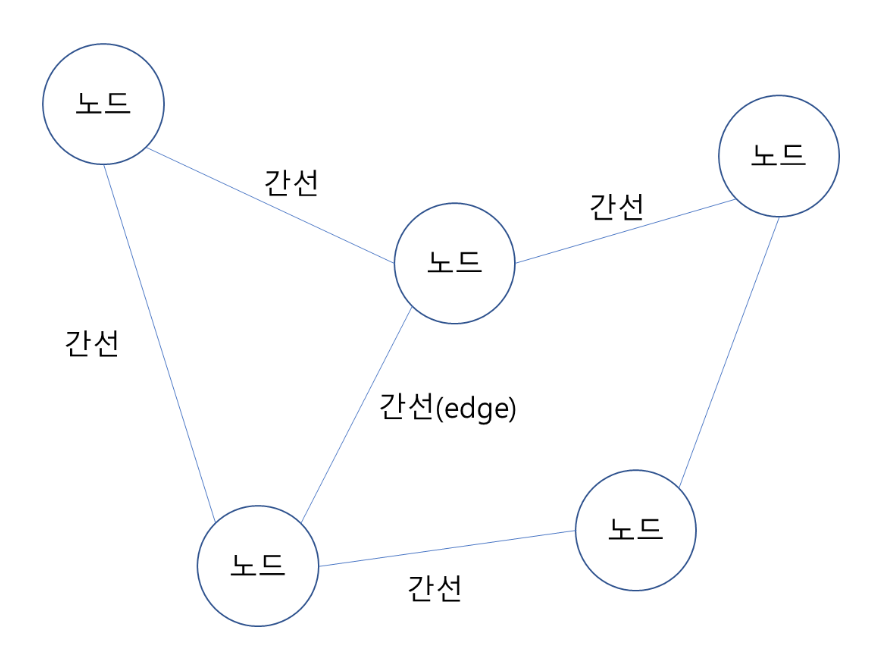
- 그래프는 노드 ( Node ) 와 간선 ( Edge ) 으로 이루어진 자료구조의 일종
- 리스트•스택•큐 등은 선형 구조로 자료구조의 일종
- 트리와 그래프는 비선형 구조의 자료구조
- 트리는 그래프의 일종
- 간선으로 연결되어 있는 노드들은 인접하다 ( adjacent ) 라고 표현
- 그래프를 구현하는 방식은 두 가지
- 트리와 그래프는 비선형 구조의 자료구조
그래프 구현 방식
- 인접 행렬 ( Adjecency Matrix )
- 2차원 배열을 활용하여 그래프를 표현하는 방식
- 인접 리스트 ( Adjacent List )
- 연결 리스트를 활용하여 표현하는 방식
인접 행렬
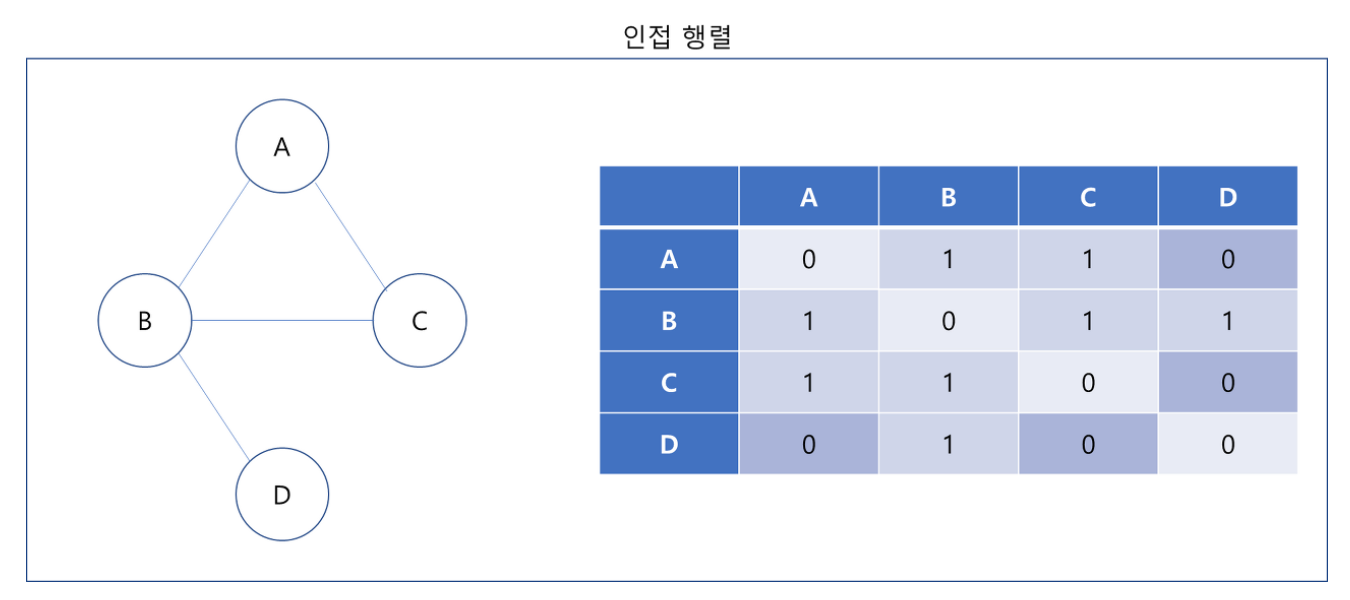
- 인접 행렬은 2차원 배열에 각 노드가 연결된 형태를 기록하는 방식
- A와 A끼리는 자기 자신이니
0으로 표현 - 연결되어 있다면
1로 아니라면0으로 표현
- A와 A끼리는 자기 자신이니
graph = [
[0, 1, 1, 0],
[1, 0, 1, 1],
[1, 1, 0, 0],
[0, 1, 0, 0]
]인접 리스트
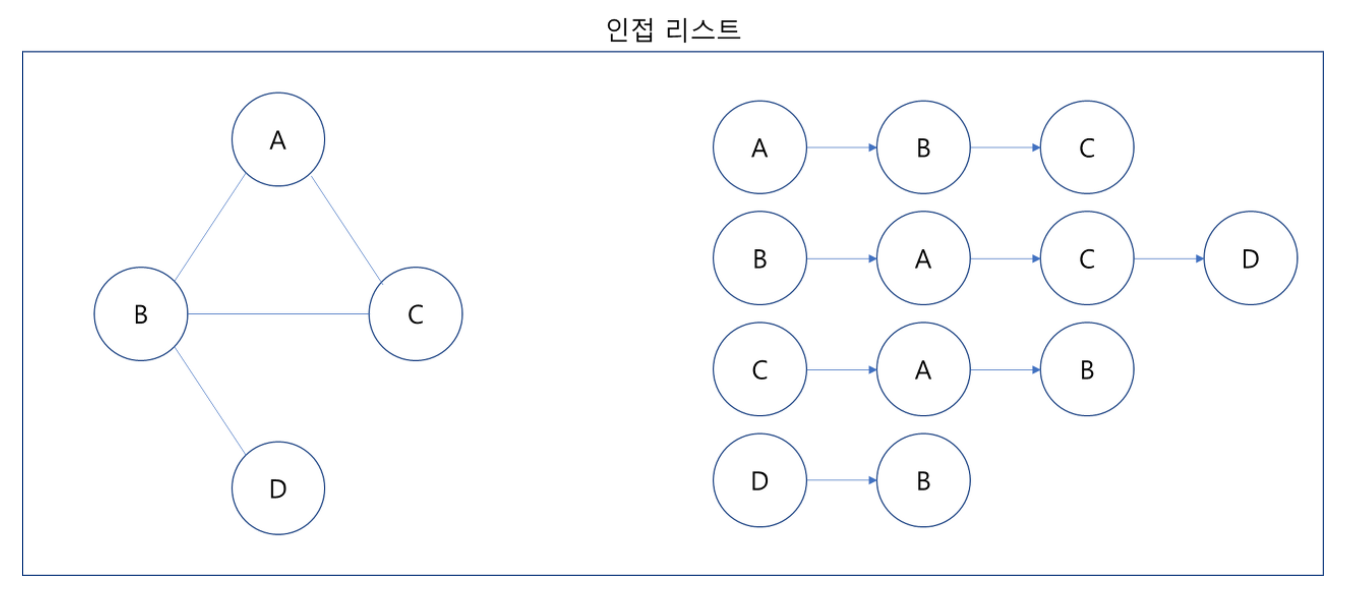
- 인접 리스트는 모든 노드에 연결된 노드들의 정보를 차례대로 기록하는 방식
- C 나 Java 같은 언어들은 배열을 사용할 때 미리 배열의 크기를 지정하고 선언해야 하는데 Python 의 리스트는
append()와 같은 메소드를 가지고 있음으로 배열과 연결 리스트의 기능을 모두 제공- 그리하여 Python 으로는 2차원 배열로도 그래프를 표현하기 충분
- C 나 Java 같은 언어들은 배열을 사용할 때 미리 배열의 크기를 지정하고 선언해야 하는데 Python 의 리스트는
graph = [[] for _ in range(4)]
# 노드 A
graph[0].append('B')
graph[0].append('C')
# 노드 B
graph[1].append('A')
...
graph = [['B', 'C'], ['A', 'C', 'D'], ['A', 'B'], ['B']]인접 행렬과 인접 리스트 비교
- 인접 행렬
- 장점
- 두 노드의 간선의 존재 여부를 바로 알 수 있음
- 단점
- 모든 관계를 기록함으로 노드의 개수가 많을 수록 불필요한 메모리 낭비가 일어남
- 장점
- 인접 리스트
- 장점
- 연결된 것들만 기록함
- 어떤 노드의 인접한 노드들을 바로 알 수 있음
- 단점
- 두 노드가 연결되어 있는지 확인이 인접 행렬보다 느림
- 장점
- 인접 행렬은 그래프에 간선이 많이 존재하는 밀집 그래프일 경우 사용
- 인접 리스트는 간선이 적은 희소 그래프일 경우 사용
DFS & BFS
- DFS와 BFS의 차이점은 노드 방문 순서
DFS
- DFS는 깊이 우선 탐색이라는 그 이름답게 그래프의 깊은 부분을 우선적으로 탐색하는 알고리즘
- 스택 자료구조를 사용하여 그래프의 가장 깊은 곳까지 방문한 뒤 다시 돌아가 다른 경로를 탐색
- 구체적인 동작 과정
- 첫번째: 탐색 시작 노드를 스택에 삽입하고 방문 처리
- 이미 방문했던 노드를 재방문하지 않기 위해
- 두번째: 스택의 최상단 노드에 방문하지 않은 인접 노드가 있다면 그 노드를 스택에 넣고 방문 처리
- 만약 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄
- 세번째: 두번째 과정을 더 이상 수행할 수 없을 때까지 반복
- 첫번째: 탐색 시작 노드를 스택에 삽입하고 방문 처리
- DFS의 시간 복잡도는
O(N)- 재귀 함수로 구현하면 굳이 스택을 사용하지 않아도 됨
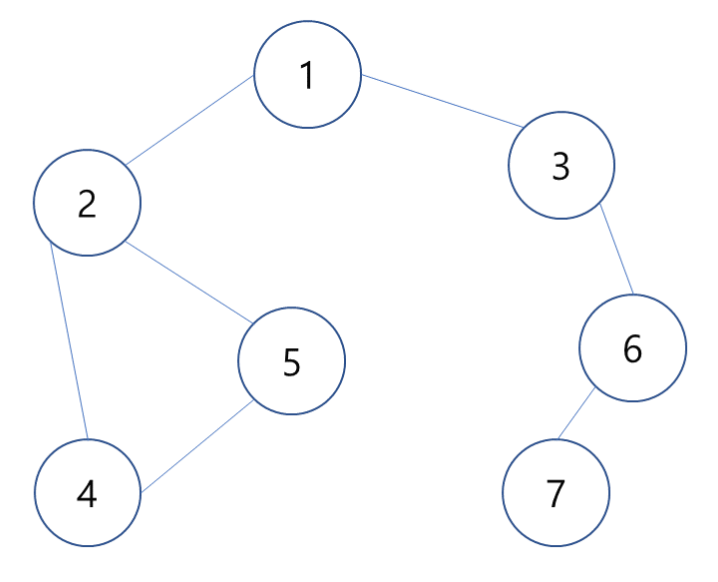
graph = [
[], # 0
[2, 3], # 1
[4, 5], # 2
[6], # 3
[2, 5], # 4
[2, 4], # 5
[3, 7], # 6
[6] # 7
]
# 방문 정보를 기록하기 위한 리스트
visited = [False] * 8
def dfs(v):
# 방문 표시
visited[v] = True
print(v, end=' ')
# 그래프를 순환하면서 인접 노드들을 방문
for i in graph[v]:
# 만약 방문하지 않은 노드가 있다면
if not visited[i]:
# 탐색 시작
dfs(i)
# 탐색 시작 노드 1을 넣어주며 dfs() 실행
dfs(1)BFS
- BFS 너비 우선 탐색이라는 이름에 걸맞게 그래프의 너비부터 탐색
- DFS가 세로로 탐색하는 반면 BFS는 그래프를 가로로 탐색
- DFS는 인접 노드의 인접 노드를 계속해서 탐색해 가지만 BFS는 인접 노드를 계속 큐에 넣어가며 큐에 들어온 순서대로 탐색을 시작하기에 시작 노드에서부터 가까운 노드들부터 탐색한다는 의미
- 구체적인 동작 과정
- 첫번째: 탐색 시작 노드를 큐에 삽입하고 방문 처리.
- 두번째: 큐에서 노드를 꺼내 해당 노드의 방문하지 않은 모든 인접 노드를 모두 큐에 삽입하고 방문 처리
- 세번째: 두번째 과정을 더 이상 수행할 수 없을 때까지 반복
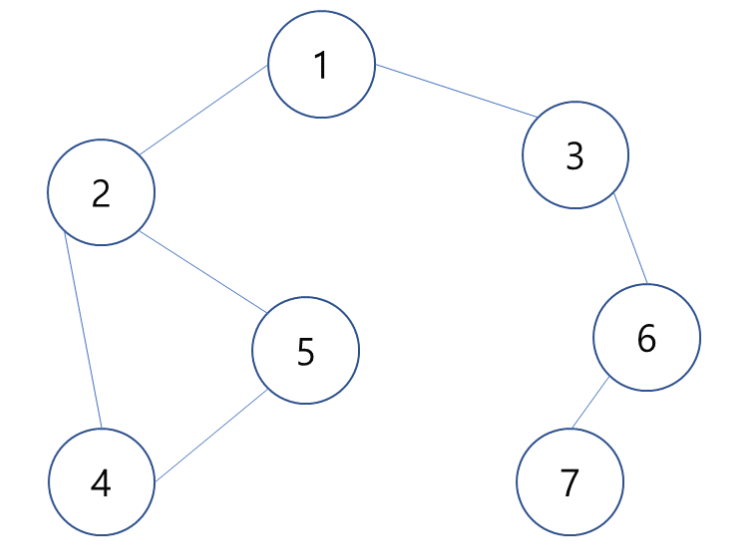
- BFS의 시간 복잡도는
O(N)- 큐를 사용하기에
deque라이브러리를 사용하는 것을 추천 - 일반적으로 BFS가 재귀로 구현한 DFS보다 조금 더 빠르게 동작
- 큐를 사용하기에
from collections import deque
graph = [
[], # 0
[2, 3], # 1
[4, 5], # 2
[6], # 3
[2, 5], # 4
[2, 4], # 5
[3, 7], # 6
[6] # 7
]
visited = [False] * 8
def bfs(v):
# 큐 생성 및 큐에 시작 노드 삽입
q = deque()
q.append(v)
# 아직 방문해야 하는 노드가 있다면
while q:
# 큐에서 노드를 꺼내서 x에 저장
x = q.popleft()
print(x, end=' ')
# 그래프를 탐색하다가 방문하지 않은 노드가 있다면
for i in graph[x]:
if not visited[i]:
# 큐에 방문하라고 삽입하고 방문 처리
q.append(i)
visited[i] = True
bfs(1)Tip! 시간 복잡도 비교
- 두 방식 모두 조건 내의 모든 노드를 검색한다는 점에서 시간 복잡도는 동일
- 일반적으로 DFS를 재귀 함수로 구현한다는 점에서 DFS보다 BFS가 조금 더 빠르게 동작
- 예시: N이 노드의 개수이고 E가 간선의 개수일 때
- 인접 행렬:
O(N^2)- 인접 리스트:
O(N + E)
DFS 장단점
DFS 장점
- 현 경로 상의 노드들만 기억하기 때문에 적은 메모리를 사용
- 목표 노드가 깊은 단계에 있는 경우 BFS 보다 빠르게 탐색 가능
DFS 단점
- 해가 없는 경로를 탐색할 경우 단계가 끝날 때까지 ( 현 경로의 가장 끝까지 ) 탐색함
- 답이 아닌 경로가 매우 깊다면 그 경로에 깊이 빠지게 됨
- 여러 경로 중 무한한 길이를 가지는 경로가 존재하고 해가 다른 경로에 존재하는 경우 무한한 길이의 경로에서 빠져나오지 못해 영원히 종료하지 못함
- 효율성을 높이기 위해서 미리 지정한 임의 깊이까지만 탐색하고 ( 재귀로 구현한다면 재귀 호출 횟수를 제한하는 등 ) 해를 발견하지 못하면 빠져나와 다른 경로를 탐색하는 방법을 사용해야 함.
- 목표에 이르는 경로가 다수인 경우 DFS는 해에 도착하면 탐색을 종료하기에 얻어진 해가 최단 경로라는 보장이 없음
BFS 장단점
BFS 장점
- 모든 경로를 탐색하기에 여러 해가 있을 경우에도 최단 경로임을 보장함
- 최단 경로가 존재하면 깊이가 무한정 깊어진다고 해도 답을 찾을 수 있음
- 여러 경로 중 무한한 길이를 가지는 경로가 존재하더라도 모든 경로를 동시에 탐색을 진행하기 때문에 탐색 가능
- 노드의 수가 적고 깊이가 얕은 해가 존재할 때 유리함.
- 탐색하는 트리 또는 그래프의 크기에 비례하는 시간 복잡도를 가짐
BFS 단점
- 노드의 수가 많을수록 탐색 가지가 급격히 증가함에 따라 보다 많은 기억 공간 ( 메모리)* 을 필요로 하게 됨
- 메모리 상의 확장된 노드들을 저장할 필요가 있기에 탐색하는 트리 또는 그래프의 크기에 비례하는 공간 복잡도를 가짐

Tip! 추가내용
문제의 특징별 활용
그래프의 모든 정점을 방문하는 것이 주요한 문제
- 단순히 모든 정점을 방문하는 것이 중요한 문제의 경우 DFS•BFS 두 가지 방법 중 어느 것을 사용해도 상관이 없음
경로의 특징을 저장해둬야 하는 문제
- 예를 들어 각 정점에 숫자가 적혀있고 a부터 b까지 가는 경로를 구하는데 경로에 같은 숫자가 있으면 안 된다는 문제 등 각각의 경로마다 특징을 저장해둬야 할 때는 DFS를 사용
- BFS는 경로의 특징을 가지지 못함
최단거리를 구하는 문제
- 미로 찾기 등 최단 거리를 구해야 할 경우 BFS가 유리
- 왜냐하면 DFS로 경로를 검색할 경우 처음으로 발견되는 해답이 최단거리가 아닐 수 있지만 BFS는 현재 노드부터 가까운 곳부터 찾기 때문에 경로 탐색 시 먼저 찾아지는 해답이 곧 최단거리이기 때문
- 이외에도 검색 대상 그래프가 정말 크다면 DFS를 고려
- 검색 대상의 규모가 크지 않고 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 BFS를 고려

🌱 Backend-Dev | hwaya2828@gmail.com