
Linked List
생활코딩: Data Structure (자료구조)
참고 사이트 : VISUALGO
소개
- linked list는 엘리먼트와 엘리먼트 간의 연결(link)을 이용해서 리스트를 구현한 것을 의미
- 그렇게 보면 linked list에서 가장 중요한 것은 연결이 무엇인가를 파악하는 것이라고 할 수 있음
- 또 연결이 아닌 것은 무엇인가를 생각해보는 것도 의미가 있음
메모리
- 컴퓨터에는 3가지 중요한 부품이 있음
- CPU와 메모리(memory) 그리고 스토리지(storage)
- 메모리는 보통 RAM이라고 부름
- 스토리지의 종류로는 HDD와 SSD가 있음
Tip! 메모리와 스토리지
- 메모리(DRAM)는 단기 데이터 액세스를 허용하는 컴퓨터의 구성 요소
- 애플리케이션 로드, 웹 탐색 또는 스프레드시트 편집과 같은 시스템의 순간 작동은 단기 데이터 액세스를 사용하여 수행되므로 설치된 메모리의 속도와 크기는 시스템 성능에 중요한 역할을 함
- (하드 드라이브 또는 SSD의 형태에 관계 없이) 스토리지는 장기적 데이터 액세스를 가능하게 하는 컴퓨터의 구성 요소
- 파일, 애플리케이션 및 운영 체제에 액세스하고 저장하는 구성 요소
- 메모리와 스토리지는 함께 시스템의 프로세서와 협력하여 데이터를 사용하고 액세스함
- ① 스토리지 드라이브는 프로그램과 파일을 보관
- 스토리지 드라이브의 속도는 시스템이 얼마나 빨리 부팅되고 저장된 데이터에 얼마나 빨리 액세스하는지를 결정하는 데 큰 역할을 함
- ② 프로세서는 스토리지 드라이브에 액세스하고 단기 액세스(순간 작동)를 위해 메모리에 장기 데이터를 전송
- 예를 들어, 프로그램을 시작하면 시스템의 프로세서가 스토리지 드라이브의 장기 데이터에 액세스하여 메모리를 통해 액세스할 수 있는 사용 가능한 단기 데이터로 변환해야 함
- ③ 프로세서는 프로그램 실행, 파일 편집, 다른 애플리케이션 간의 전환을 위해 메모리에서 데이터에 액세스함
- 설치된 메모리의 속도와 용량은 애플리케이션의 로드 및 작동 속도를 판별하고 컴퓨터가 얼마나 효율적으로 멀티태스킹을 수행할 수 있는지 판별하는 데 도움이 됨
- 시스템이 데이터에 액세스하는 방식 때문에 메모리와 스토리지의 속도는 프로세서가 얼마나 빠르게 여러 데이터 유형 간에 데이터를 변환하고 사용 가능하게 만들 수 있는지에 큰 역할을 함
- 느린 메모리와 스토리지 구성 요소는 데이터 병목현상을 유발하므로 하나 또는 두 개의 구성 요소를 모두 업그레이드하는 것이 최선
Tip! HDD와 SSD
- HDD는 Hard Disk Drive의 약자로 컴퓨터의 정보와 문서 자료 등을 저장하고 읽을 수 있는 장치를 말함
- HDD는 자기디스크를 회전하는 방식으로 버퍼 메모리가 클수록 속도가 빠른 것이 이론이지만 현재는 성능이 평준화되어 큰 차이는 없음
- 고속으로 디스크를 회전시켜 저장하는 방식이라 충격에 약하며 디스크가 회전하는 동안에는 소음이 발생할 수도 있음
- 최근에는 디스크 메모리 대신 SSD의 사용이 증가했는데 HDD보다 속도가 빠르며 소음이 거의 없는 장점이 있음
- SSD는 Solid State Drive의 약자로 PC에서 보조기억장치의 역할을 함
- PC는 주로 중앙처리장치, 주기억장치, 보조기억장치로 운영이 되는데 HDD의 속도의 한계와 소음을 극복하기 위해 나올 것이 보조기억장치인 SSD
- 기존에는 CPU나 RAM은 지속적인 발전이 이루어진 반면 보조기억장치는 발전이 더딘편이었기 때문에 PC의 속도에도 한계점도 있었음
- SSD가 소음이 적고 속도가 빠른 이유는 반도체로 데이터를 저장하기 때문인데 이러한 특성 때문에 소음이 없으며 속도가 HDD 보다 빠를 수 밖에 없음
- HDD는 자기디스크를 회전하는 방식으로 저장하기 때문에 회전 속도에 한계가 있었지만 HDD는 대용량을 저장할 수 있는 반면 그에 비하면 SSD는 큰 저장용량을 자랑하지는 않음
- 메모리는 속도가 매우 빠른 반면 용량이 작고 전기를 끄면 데이터가 사라지는 속성을 가지고 있음
- 반면에 스토리지는 속도가 느리지만 용량이 훨씬 크고 전기를 꺼도 데이터가 남아 있음
- 이런 이유로 데이터는 기본적으로 스토리지에 저장
- 하지만 스토리지는 매우 느리기 때문에 CPU와 함께 일을 하기에는 속도면에서 부족
- 그래서 어떤 프로그램을 실행하면 그 프로그램과 데이터는 메모리로 옮겨짐
- CPU는 메모리에 로드된 데이터를 이용해서 여러가지 일을 하게 됨
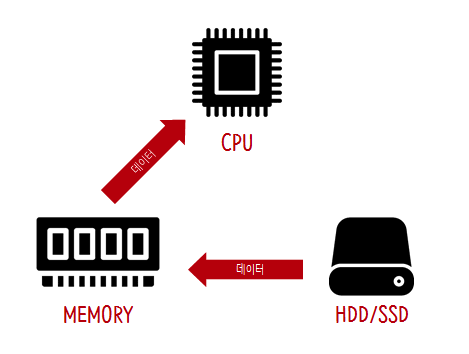
- 그러므로 실행속도를 결정하는 것은 대체로 메모리
- 데이터 스트럭쳐를 배우는 이유는 메모리의 효율적인 사용이라고 할 수 있음
메모리의 구조
- 메모리는 건물에 비유할 수 있음
- 아래 그림은 배열을 사용하는 것과 linked list를 사용하는 것을 비유해서 보여주고 있음
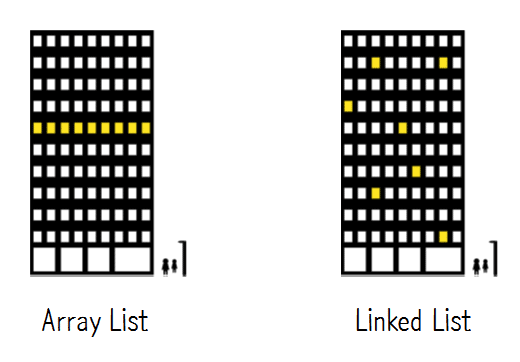
Array List
- 첫번째 회사는 모든 직원이 한곳에 모여있어야 한다는 철학이 있기 때문에 사무실이 모여있음
- 배열은 건물을 이런 식으로 사용하는 것과 비슷
- 만약 회사가 성장해서 사무실이 좁아지면 붙어있는 공간이 없기 때문에 더 이상 새로운 직원을 뽑을 수 없음
- 만약 더 많은 공간이 필요하다면 더 많은 사람을 수용할 수 있는 공간을 찾아서 전체가 이사해야 함
Linked List
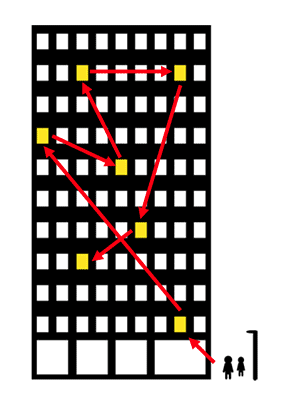
- linked list는 한 건물 내에서 한 회사가 임대한 사무실이 서로 떨어져 있는데 건물에서 비어있는 곳 아무데나 임대해서 들어가면 되기 때문에 직원이 늘어도 큰 걱정이 없음
- 그런데 방문자가 사무실을 찾는 방법이 비효율
- 위의 그림에 있는 방문자가 3번째 사무실을 찾아가려면 우선 첫 번째 화살표의 사무실을 찾아가야 함
- 이 사무실의 직원에게 다음 사무실이 어딘지 물어보고 알려주는 사무실로 이동 한 후에 다시 물어봐서 그다음 사무실로 이동
- 이렇게 물어물어 사무실을 찾아가야 하는 방식이 linked list
- 그래서 linked list에서는 몇 번째 엘리먼트를 찾는 것이 느림
- 반면에 array list는 엘리먼트가 같은 곳에 모여있음
- 만약에 3번째 자리로 가고 싶다면 한번에 3번째 방으로 갈 수 있음
- 찾고자 하는 사무실이 몇 번째에 있는지 알고 있다면 array list는 매우 빠름
연결
- 배열과는 다르게 linked list는 그 위치가 흩어져 있기 때문에 서로 연결되어 있어야 하는데 바로 그런 점에서 연결이라는 이름을 갖게 된 것
- linked list는 다양한 데이터 스트럭쳐에서 광범위하게 사용되는 개념
- linked list와 같이 연결된 엘리먼트들은 노드(node, 마디, 교점의 의미) 혹은 버텍스(vertex, 정점, 꼭지점의 의미)라고 부름
- 이런 용어들은 연결성이 강조된 표현
구조
- 리스트는 노드(엘리먼트)들의 모임이기 때문에 내부적으로 노드를 가지고 있어야 함
- array list의 경우 엘리먼트가 배열의 엘리먼트였으나 linked list는 배열 대신에 다른 구조를 사용
- 노드는 최소한 두 가지 정보를 알고 있어야 함
- 노드의 값과 다음 노드
- 각각의 노드가 다음 노드를 알고 있기 때문에 하나의 연결된 값의 모임을 만들 수 있음
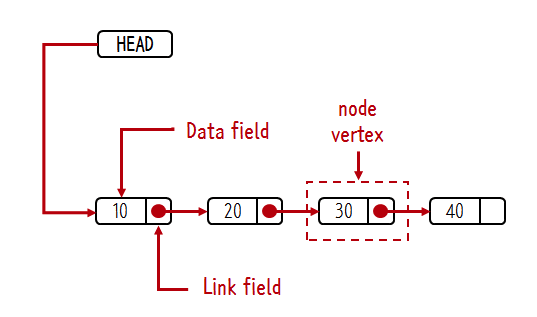
- 이것을 구현하는 방법은 여러가지
- 만약 사용 언어가 C라면 구조체, 자바와 같은 객체지향 언어라면 객체에 데이터 필드와 링크 필드를 만듬
- 보통 데이터 필드는 value라는 이름의 변수, 링크 필드는 next 변수를 사용
- value에는 노드의 값이 저장되고, next에는 다음 노드의 포인터나 참조값을 저장해서 노드와 노드를 연결시키는 방법을 사용
Head
- 위의 그림을 보면 head라는 것이 있음
- 건물의 비유를 다시 사용해봤을 때, 건물에 들어가려면 출입문을 찾아야 함
- 리스트를 하나의 건물로 비유하자면 출입문에 해당하는 것이 head
- linked list를 사용하기 위해서는 이 head가 가리키는 첫번째 노드를 찾아야 함
- 취향에 따라서는 first와 같은 이름을 사용하는 경우도 있음
데이터의 추가
시작 부분에 추가
- 노드를 첫번째 위치에 추가하는 방법
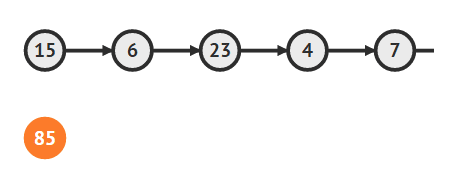
- 우선 새로운 노드를 생성
Vertex temp = new Vertex(input)
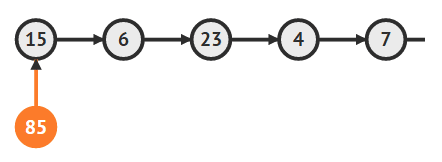
- 새로운 노드의 다음 노드로 첫번째 노드를 가리킴
temp.next = head

- 새로 만들어진 노드가 첫번째 노드가 되도록 head의 값을 변경
head = temp
Tip! 위 작업에 대한 전체 코드
Vertex temp = new Vertex(input) temp.next = head head = temp
중간에 추가
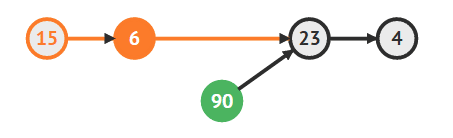
- 3번째 자리(인덱스 2)에 90을 추가하는 방법
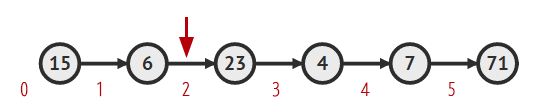
- 3번째 자리는 붉은 화살표가 표시된 부분
- 즉 6과 23 사이에 90을 위치시키는 것이 하려는 것
- 우선 3번째 자리를 찾아야 함

- head를 참조해서 첫번째 노드 찾기
Vertex temp1 = head

- 23의 자리에 새로운 노드를 위치시키기 위해서는 6을 알고 있어야 함
- 6의 next로 새로운 노드를 지정해야 하기 때문
- 아래는 6을 temp1으로 지정하기 위한 반복문
// 현재 k의 값은 2
while (--k!=0)
temp1 = temp1.next
- 6의 next를 이용해서 23을 찾아서 temp2로 지정
Vertex temp2 = temp1.next
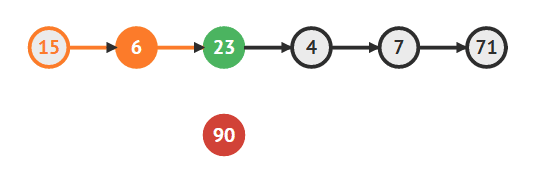
- 값이 90인 새로운 노드 생성
Vertex newVertex = new Vertex(input)
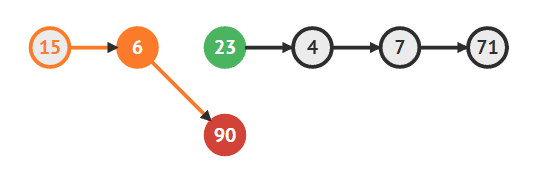
- 6의 다음 노드로 새로운 노드를 지정
temp1.next = newVertex
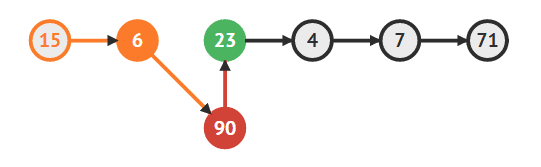
- 새로운 노드의 다음 노드로 23번을 지정
newVertex.next = temp2

- 이렇게 해서 90을 3번째 자리에 위치시켰음
- 이것이 array list와 linked list의 핵심적인 차이점
- 배열의 경우는 엘리먼트를 중간에 추가•삭제할 경우 해당 엘리먼트의 뒤에 있는 모든 엘리먼트의 자리 이동이 필요했음
- 그래서 배열은 추가•삭제가 느림
- 반대로 linked list의 경우 추가•삭제가 될 엘리먼트의 이전, 이후 노드의 참조값(next)만 변경하면 되기 때문에 속도가 빠름
Tip! 위 작업에 대한 전체 코드
Vertex temp1 = head while (--k!=0) temp1 = temp1.next Vertex temp2 = temp1.next Vertex newVertex = new Vertex(input) temp1.next = newVertex newVertex.next = temp2
데이터의 제거
- 데이터를 제거하는 것도 추가하는 것과 비슷
- 세번째 노드(인덱스 2)를 제거하는 방법
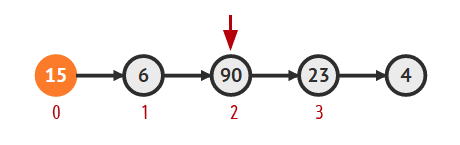
- 우선 head를 이용해서 첫번째 노드 찾기
Vertex cur = head

- 두번째 노드로 이동
// k = 2
while (--k!=0)
cur = cur.next
- 세번째 노드를 찾음
Vertex tobedeleted = cur.next
- 두번째 노드의 next를 23으로 변경
cur.next = cur.next.next
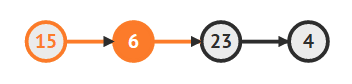
- 이제 90을 지워도 됨
- 90을 삭제해서 메모리에서 제거
delete tobedeleted
Tip! 위 작업에 대한 전체 코드
Vertex cur = head while (--k!=0) cur = cur.next Vertex tobedeleted = cur.next cur.next = cur.next.next delete tobedeleted
인덱스를 이용한 데이터 조회
- 인덱스를 이용해서 데이터를 조회할 때 linked list는 head가 가리키는 노드부터 시작해서 순차적으로 노드를 찾아가는 과정을 거쳐야 함
- 만약 찾고자 하는 엘리먼트가 가장 끝에 있다면 모든 노드를 탐색해야 함
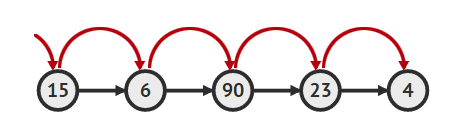
- 반면에 array를 이용해서 리스트를 구현하면 인덱스를 이용해서 해당 엘리먼트에 바로 접근 할 수 있기 때문에 매우 빠름
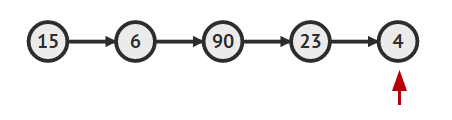
Trade Off
- 트래이드 오프는 어떤 특성이 좋아지면 다른 특성이 나뻐지는 상황을 의미
- array list와 linked list는 트레이드 오프의 좋은 사례라고 할 수 있으며 데이터 스트럭쳐를 배우는 이유 중의 하나는 이러한 트레이드 오프를 이해하기 위해서인데 장점과 단점의 미묘한 균형을 이해할 수 있어야 올바른 선택을 할 수 있기 때문


🌱 Backend-Dev | hwaya2828@gmail.com