구글에서 여러 정보를 찾아보던 중,
파이썬은 GIL이 있어서 멀티스레드 환경에서 좋지 않다
는 내용의 글을 언뜻 보았다.
이 문장을 보니깐, 내 프로젝트에 동시에 수행하기 위해 스레드를 매우 여러개를 계층을 나눠서
분리해놨던 것이 생각났다.
혹시 성능에 영향을 크게 주지 않을까 GIL에 대해 찾아보고, 멀티스레드로 성능 체크 및
멀티프로세스까지 사용해서 비교해봤다.
GIL이란?
GIL은 Globla Interpreter Lock으로, 말그대로 전역으로 인터프러터에 락을 건다는 것이다.
여기서 말하는 락은 데이터베이스나 운영체제에서 배우는 그 Lock과 같다.
DB나 OS에서 배운 것처럼 이것 역시 병렬 프로그래밍에서 발생할 수 있는 문제를 방지하기 위해 Lock을 사용한다.
그러면 전역 인터프리터에 락을 건다는게 무슨 뜻일까?
Python Interpreter은 동일한 시점에 스레드를 오직 하나만 수행할 수 있고, 이때 하나만 이용하기 위해 사용하는 Lock이 GIL이다.
싱글 코어 프로세서를 가진 컴퓨터가 아니더라도, 실제 동시에 수행하지 않고
동시에 수행하는 척만 하는 것이다
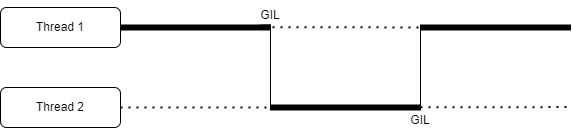
코어 하나에서 여러개의 스레드를 처리하는 것도 사실 동시에 수행하는 것처럼 보이는
동시성이다. 하지만, 요즘 컴퓨터든 핸드폰이든 싱글코어 프로세서를 사용하는 경우는 없으니, 멀티스레드를 사용하면 여러 프로세서에 OS 관리 하에 적절히 분배돼서
실제 병렬 실행 된다.
그러나, 파이썬은 동시에 오직 하나의 스레드만 수행할 수 있으므로,
이건 큰 단점이 될 수 있다.
왜 굳이 Lock을 거냐면, Python의 가비지 컬렉션 메모리 관리 기법인
Reference Counting 때문이다.
이 참조 카운트가 결국 critical section인데, 이를 참조할 때 동시성을 관리하지 않으면
큰 문제가 발생하기 때문이다 (DeadLock, Race Condition..)
이와 비슷하게, 예전에 블로그에 Java에서 사용하는 GC에 대해서 글을 작성한 적이 있는데
Java는 스레드간에 전환할 떄 GIL로 하는 방식은 아니여도 Java도 GC를 수행할 떄는
모든 스레드를 멈추고 GC를 수행한다.
다시 본론으로 돌아와, 이 GIL 및 멀티스레드 환경을 Python Code로 작성하고
또 멀티프로세스 방식으로도 동일한 수행을 실험해 봤다.
import time
from threading import Thread
import multiprocessing
COUNT = 10000000
def count_test(n):
while n>0:
n -= 1
if __name__ == '__main__':
TEST_COUNT = 16
start = time.time()
p_or_t = []
for i in range(TEST_COUNT):
proc_or_thread = multiprocessing.Process(target=count_test, args=(COUNT,))
# proc_or_thread = Thread(target=count_test, args=(COUNT,))
proc_or_thread.start()
p_or_t.append(proc_or_thread)
for pt in p_or_t:
pt.join()
end = time.time()
print('소요 시간(초) -', end - start)아래 코드 중간에 있는 proc_or_thread를 한줄을 주석하고 나머지 한줄을 주석을 풀면
멀티스레드와 멀티프로세스를 비교할 수 있고, 스레드 개수 또는 생성할 프로세스 수를
조절할 수 있게 하였다.
결과를 확인해보면
프로세스 16개 / COUNT=1000만 : 약 1.6초
스레드 16개 / COUNT=1000만 : 약 3.1초
프로세스 16개 / COUNT=5000만 : 약 7.0초
스레드 16개 / COUNT=5000만 : 약 14.2초
프로세스 4개 / COUNT=5000만 : 약 2.3초
스레드 4개 / COUNT=5000만 : 약 5.57초
이렇게 결과가 나왔다.
단순히 수를 더하는 아주 간단한 작업임에도, 파이썬은 이를 동시에 수행할 수 없기 때문에
시간차이가 생각보다 크게 발생한다.
그렇다면 Python에서는 멀티스레드를 사용하면 안되는 것인가?
하지만 Python에서 멀티스레드가 효율이 좋지 않더라도, 특정한 상황에서는 효율적인데
바로 I/O Bound가 큰 작업을 수행할 때이다.
I/O bound랑 프로세스가 진행 될 때 I/O에 소요 되는시간이 큰 경우이다.
이럴 경우에는 스레드를 분리해놓으면, I/O를 접근해서 수행하는데 걸리는 대기 시간
동안 다른 스레드에서 일을 할 수 있기 때문이다.
위에 예시에서 멀티스레드의 비효율을 보여주기 위해 멀티 프로세스도 같이 테스트 했는데,
위 내용까지만 보면 멀티프로세스가 훨씬 좋아보인다.
하지만, "프로세스"는 "스레드"와 다르게 스레드끼리 공유하는 메모리 영역이 없기 때문에
Context Switching 비용이 훨씬 크다.
또한, 위 예시 코드에서는 단순히 인자 전달해서 while 루프로 숫자를 더하는 작업만
수행했지만, 수행하는 내용이 복잡할 수록 코드 설계나 작성하기가 크게 어려워진다.
예를 들어 하나의 프로그램 내에서 멀티프로세스를 이용해서
공유 메모리 영역을 만드는 상황이 그 예시다
Python에서 멀티스레드를 사용하면 어차피 스레드끼리 변수 공유하려면
그냥 전역변수가 이미 서로 공유 되는거라 크게 설정할 작업이 없다.
하지만 멀티 프로세스는, 공유할 메모리 영역을 만들어서 이걸 인자로 넣어서 전달을 하든
해야 되고, 이게 숫자 같은 것들은 Python multiprocessing에서
이미 함수로 지원하고 있다.
그러나 이건 단순한 int,str 값 같은 경우이고, 공유 하고자 하는 대상이 클래스의
인스턴스이거나 복잡한 배열 등등의 경우 골치아파진다.
나는 프로젝트에서 프로세스끼리 numpy array를 공유하는 상황을 만들었는데,
실제 공유 영역을 안만들고 단순히 numpy객체 인자만 넘기다가는 같은 곳을 바라보는
numpy array가 아니라 내용만 같고 가리키는 곳이 다른 새로운 배열이 만들어진다.
그래서 파이썬의 SharedMemory를 이용해서 힘들게 구현했다.
이렇듯, 파이썬에서는 멀티 프로세스가 멀티 스레드보다 무조건 유리한 것도 아니고
멀티 스레드보다 싱글스레드가 무조건 유리한 것도 아니므로 상황에 맞게 사용해야한다.
추가로, 멀티 스레드로 분리 해도 되는 상황을 테스트 해봤는데,
두개 이상의 흐름에서 만약 time.sleep()을 호출하는 경우에도 쉬는 시간 동안
다른 스레드를 수행할 수 있으므로 굳이 멀티프로세스를 안쓰고 멀티스레드를 이용하는게
유리하다.
위에 올려놓은 코드에 count_test()함수 수행할 때 중간에 time.sleep(0.1) 이렇게
추가해서 보면, 멀티 프로세스보다 멀티 스레드가 조금 더 빨리 동작한다.
물론 얼마나 쉬냐에 따라 다르겠지만, 여유롭게 쉰다면 GIL이 있어도 다른 스레드가
쉬는 동안 다른 스레드가 일을 하면 된다. 특히 멀티 프로세스는 문맥 교환 비용이
크기 때문에 이런 부분에서는 멀티 스레드가 유리한 것 같다.
