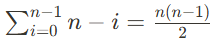
선택 정렬
- 탐색 범위에서 최소값을 찾은 후, 그 값을 범위의 가장 앞으로 보내면서 정렬하는 정렬법이다.
- 동작순서
1) 현재 리스트에서 최소값을 찾는다.
2) 그 값을 첫번째 인덱스 값과 교환한다.
3) 첫 원소를 제외한 나머지 리스트를 기준으로 다시 1번으로 돌아가 정렬한다.
ex)
TEST = [9, 4, 3, 7, 10, 22, 1, 6]
# 첫 원소 ~ 가장 마지막 원소를 제외한 원소까지
for i in range(len(TEST)-1):
# 가장 작은 원소의 인덱스를 시작 지점으로 설정
min_idx = i
# 시작 원소의 다음 원소 부터 배열 끝까지 값 탐색
# 가장 작은 인덱스를 찾는다.
for j in range(i+1, len(TEST)):
if TEST[min_idx] > TEST[j]:
min_idx = j
# 1번 탐색마다 각 배열의 범위에서 가장 작은 인덱스와 시작 인덱스를 변경한다.
TEST[i], TEST[min_idx] = TEST[min_idx], TEST[i]
print(TEST)시간 복잡도
- 최악 시간복잡도
- 배열이 역 정렬 상태일 경우- O(N2)
- 최선 시간복잡도
- 배열이 이미 정렬되어 있을 때도, 최솟값을 찾기 위해 동일하게 탐색해야 한다.- O(N2)
버블 정렬
- 현재 요소와 다음 요소를 비교하며, 큰 값을 뒤로 넘겨준다.
- 이 과정을 반복하여 가장 큰 요소를 범위의 가장 뒷 부분에 보내며 정렬하는 정렬법이다.
동작순서
1) 현재 인덱스와 다음 인덱스를 비교하여, 현재 인덱스가 더 큰 경우 스왑한다.
2) 현재 인덱스의 값이 len(iterater)-1일 때까지 반복한다. 마지막 인덱스일 경우 다음 인덱스와 비교가 불가능하기 때문이다.
3) 매 정렬마다 비교한 iterater의 마지막 부분이 정렬 범위 중 가장 큰 값이기 때문에, 다음 정렬은 첫 인덱스 ~ 이전 정렬의 마지막 부분을 제외한 부분 까지로 지정한다.
(즉, 이전의 정렬 범위가 i 인덱스였다면 다음 정렬 탐색 범위는 iterator[:i] 가 된다.)
ex)
def bubble_sort(array):
for i in range(1, len(array) - 1):
for j in range(len(array) - i):
if array[j] > array[j + 1]:
array[j], array[j + 1] = array[j + 1], array[j]
return array
# [1, 2, 3, 5, 6, 7, 23, 23, 45]
print(bubble_sort([1, 5, 3, 23, 23, 45, 6, 7, 2]))시간 복잡도
- 최악 시간 복잡도
- 배열이 역 정렬 상태일 경우- O(n2)
- 최선 시간 복잡도
- 배열이 정렬 상태일 경우에도 동일하게 비교를 진행해줘야한다.- O(n2)
삽입 정렬
- 각 모든 요소를 이미 정렬된 앞 부분과 비교하여, 현재 요소의 적합한 위치를 찾아 삽입하여 정렬하는 정렬법이다.
동작 순서
1) 현재 인덱스(i)가 처음인덱스(0) ~ 자신의 바로 앞 인덱스(i-1)중 어디에 삽입되야되는지 확인한다.
삽입 위치를 확인하기 위해, (i-1) 인덱스 → 0 인덱스 순으로 비교하며, 현재 인덱스(i) 값이 더 작을 경우 스왑한다.
만약 스왑을 하지 않게 된다면, 이후 탐색을 하지 않고, 바로 i → i+1 로 변경해준다. (다음 탐색 진행)
2) 위 과정을 두 번째 인덱스(1)부터 마지막 인덱스(n)까지 반복한다.
ex)
def insert(array):
# 앞 인덱스를 비교해야하기 때문에 1번 인덱스 부터 진행
for i in range(1, len(array)):
# 현재 인덱스
idx = i
# 이전 인덱스보다 작으며, idx가 0보다 클 경우 계속 스왑하며 비교 인덱스를 줄여나간다.
while array[idx - 1] > array[idx] and idx > 0:
array[idx - 1], array[idx] = array[idx], array[idx - 1]
idx -= 1시간 복잡도
- 최악 시간 복잡도
- 배열이 역 정렬 상태일 경우- O(N2)
- 최선 시간 복잡도
- 배열이 정렬되어 있을 경우, 각 인덱스마다 1번씩만 비교를 한다.- O(N)
퀵 정렬
- 정렬 범위 중 하나의 피벗을 선택 후, 피벗보다 작은 배열과 큰 배열을 나누고 이 배열들을 다시 재귀적으로 정렬하는 정렬법이다.
- 동작순서
1) 첫 번째 원소를 피벗으로 설정한다.
2) 두 번째 원소 위치를 left, 마지막 원소 위치를 right로 설정한다.
(left는 배열의 뒤쪽으로, right는 배열의 앞쪽으로 이동하며 값을 탐색한다.)
3) left 위치의 값이 피벗보다 클 때, right 위치의 값이 피벗보다 작을 때 left와 right 위치의 값을 바꿔준다.
(이 과정을 거쳐 피벗보다 작은 값은 배열 앞쪽에, 피벗보다 큰 값은 배열 뒤쪽에 위치한다.)
4) 모든 구분이 끝나면 피벗보다 작은 값들 중 가장 큰 값의 위치와 피벗과 바꿔준다.
5) 피벗을 기준으로 왼쪽과 오른쪽 배열로 나눠, start와 end를 설정한 두 재귀함수를 동작시킨다.
ex) 첫 원소를 피벗으로 사용하는 경우 → 정렬 / 역정렬된 배열일 경우 최악의 경우가 되며 오랜 시간이 소요
def quick_sort(array, start, end):
# 탐색 원소 범위가 1개일경우
if end - start < 1:
return
pivot = start # 피벗은 첫 번째 원소
left = start + 1 # 2번째 원소
right = end # 마지막 원소까지
while left <= right:
# 피벗보다 큰 데이터를 찾을 때까지 반복
while left <= end and array[left] <= array[pivot]:
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while right > start and array[right] >= array[pivot]:
right -= 1
# 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
if left <= right:
array[left], array[right] = array[right], array[left]
# 구분이 끝난 후, 피벗과 변경해준다.
array[right], array[pivot] = array[pivot], array[right]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
TEST = [4, 2, 3, 5, 6, 7]
quick_sort(TEST, 0, len(TEST) - 1)
print(TEST)ex) 매번 피벗을 랜덤으로 지정하는 경우 → 최악의 경우가 거의 발생하지 않음 (거의 불가능)
import random
def quick_sort(array, start, end):
# 탐색 원소 범위가 없을 경우
if end - start < 1:
return
pivot = random.randint(start, end) # 피벗은 랜덤한 인덱스로 선택한다.
left = start # 2번째 원소
right = end # 마지막 원소까지
# 랜덤하게 선택된 피벗을 가장 첫 인덱스와 자리를 바꾼다.
# 피벗은 탐색 범위 밖에 있어야 한다.
array[left], array[pivot] = array[pivot], array[left]
while left <= right:
# 가장 첫 인덱스에 존재하는 피벗보다 큰 데이터를 찾을 때까지 반복
while left <= end and array[left] <= array[start]:
left += 1
# 가장 첫 인덱스에 존재하는 피벗보다 작은 데이터를 찾을 때까지 반복
while right > start and array[right] >= array[start]:
right -= 1
# 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
if left <= right:
array[left], array[right] = array[right], array[left]
# array[right] 자리에는 left와 right가 엇갈리면서, right는 피벗보다 작은 데이터가 존재하는 index가 들어가게 된다.
# 따라서 구분이 끝난 후, 피벗이 존재했던 탐색 범위의 첫 원소와 변경해준다.
array[start], array[right] = array[right], array[start]
# 피벗이 존재했던 탐색 범위의 첫 원소와 변경해주면서, 피벗은 array[right]에 위치하게 된다.
# 분할 이후 피벗 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
TEST = [4, 2, 3, 5, 6, 7]
quick_sort(TEST, 0, len(TEST) - 1)
print(TEST)- 시간 복잡도
- 최악 시간 복잡도
- 피벗을 첫번째 원소로 사용하기 때문에, 정렬/역정렬 상태일 경우 구분의 의미가 없어진다
- O(N2)
- 최선 시간 복잡도
- 하지만, 피벗을 잘만 고른다면 정렬/역정렬 상태일 경우에도 시간 복잡도를 줄일 수 있다.- 최선의 경우는 모든 피벗이 정확히 중간 값으로 설정되어, 모두 절반씩 분할되는 경우이다. 이때 시간 복잡도는 O(NlogN)이 된다.
큌 정렬을 효과적으로 사용하기 위한 피벗 설정
- 피벗을 어떻게 고르냐에 따라 이후 작업의 시간이 결정되며, 상황에 맞게 피벗을 고르는게 매우 중요하다.
1) 정렬하고자 하는 배열을 랜덤화 시켜준다. 즉 한번 뒤섞고 정렬을 해주는 것인데, 이러면 어떤 원소를 피벗으로 사용해도 최악의 시간 복잡도는 막을 수 있다.
2) 고정된 위치에서 피벗을 선택하지 않고, 매 정렬 시 피벗 위치를 랜덤으로 선택하는 것이다.
3) 마지막은 피벗의 후보를 3개를 뽑아서 그 중 중간값을 선택하는 방법이다.
병합(합병) 정렬
- 전체 원소를 하나 단위로 분할 후, 원소를 각각 비교하며 병합하는 과정에서 정렬하는 정렬법이다.
동작순서
1) 배열을 반으로 계속 나누며, 각 배열이 1개의 원소를 가질 때까지 반복한다.
2) 이제 나눠진 배열을 하나로 합치며, 작은 원소값이 앞에 오도록 합쳐준다.
3) 2번 과정에서 합쳐진 다른 배열들끼리 다시 비교하여 작은 원소값이 앞에 오도록 합쳐진 배열을 만들어준다.
4) 3번 과정을 반복한다. → 3번 과정으로 배열이 합쳐지면서 정렬이 수행되는 것이다.
ex)
def mergeSort(array):
# 배열의 요소를 더 이상 좌우로 나눌 수 없을 때
if len(array) < 2:
return array
# 중간 인덱스를 구한다.
mid = len(array) // 2
# 배열을 좌우로 나눠 그 배열을 또 나눕니다.
left = mergeSort(array[mid:])
right = mergeSort(array[:mid])
# 좌우를 결합합니다.
return merge(left, right)
def merge(left, right):
# 좌, 우가 정렬된 데이터를 저장하는 임시 배열입니다.
merged = []
# 좌, 우 배열이 둘다 요소가 존재할 때 까지 반복합니다.
while len(left) > 0 and len(right) > 0:
# 가장 작은 첫번째 요소끼리 비교한 후 작은 값은 임시 배열에 추가합니다.
if left[0] < right[0]:
merged.append(left.pop(0))
else:
merged.append(right.pop(0))
# 만약 왼쪽 배열이 남아있는 경우 모두 임시 배열에 붙어준다.
if left:
merged += left
# 만약 오른쪽 배열이 남아있는 경우 모두 임시 배열에 붙어준다.
else:
merged += right
return merged- 시간 복잡도
- 최악과 최선 시간 복잡도가 동일하게 O(NlogN)이다.
- logN의 의미
- N개의 배열이 각각 1개의 원소를 갖는 배열로 쪼개지기까지 logN번의 과정을 거친다.
- N의 의미
- 각 배열의 병합 시, 각 원소를 비교하여 새로운 버퍼에 삽입한다.- 이미 정렬된 두 배열을 합칠 때는 버퍼의 크기만큼 N만큼만 처리를 해준다.
- 따라서 배열의 길이인 N을 곱해준다.
