아티클 스터디
1. 데이터 리터러시를 올리는 방법
[주제]
데이터 리터러시의 중요성 및 향상을 위한 방법
[아티클 요약]
데이터 리터러시의 정의
- ‘데이터를 활용해 문제를 해결하는 능력’
- 문제와 관련없는 데이터는 많아도 의미가 없음
- 데이터를 활용해 문제를 잘 정의하고 해결해야 함
데이터 리터러시 향상을 위한 세가지 방법 소개
- 데이터/실험 기반 사고방식 : 실험 프로세스 도입
- 업무 문제 해결을 위해 실험을 하는 방식으로 진행
- 많은 구성원이 문제 정의 → 솔루션 → 측정 지표를 만들어 내는데 익숙해 짐
- 분석 흐름대로 데이터를 탐색할 수 있는 환경
- 데이터맵
- 분석가 없이 지표에 집중할 수 있게 하는 관계도 제작
- 인풋 지표 원칙 : 측정 가능, 직접 control 가능
- 문제와 지표 연관성 빠르게 파악 가능
- 대시보드
- 지표의 현재 수준 확인
- 문제와 관련된 하위 지표들이 있는 분석 대시보드를 통해 지표 변동 및 원인 파악 가능
- 데이터맵
- 이 과정을 도와주는 분석가
- 데이터 분석가 (Data Scientist)
- 단순히 데이터 추출 및 분석 리포팅에 국한되면 안됨
- 실질적인 액션 아이템 도출
- 협업팀의 실행을 이끌어내는 역할
- 실험 활성화를 위한 코칭 및 컨설팅 역할
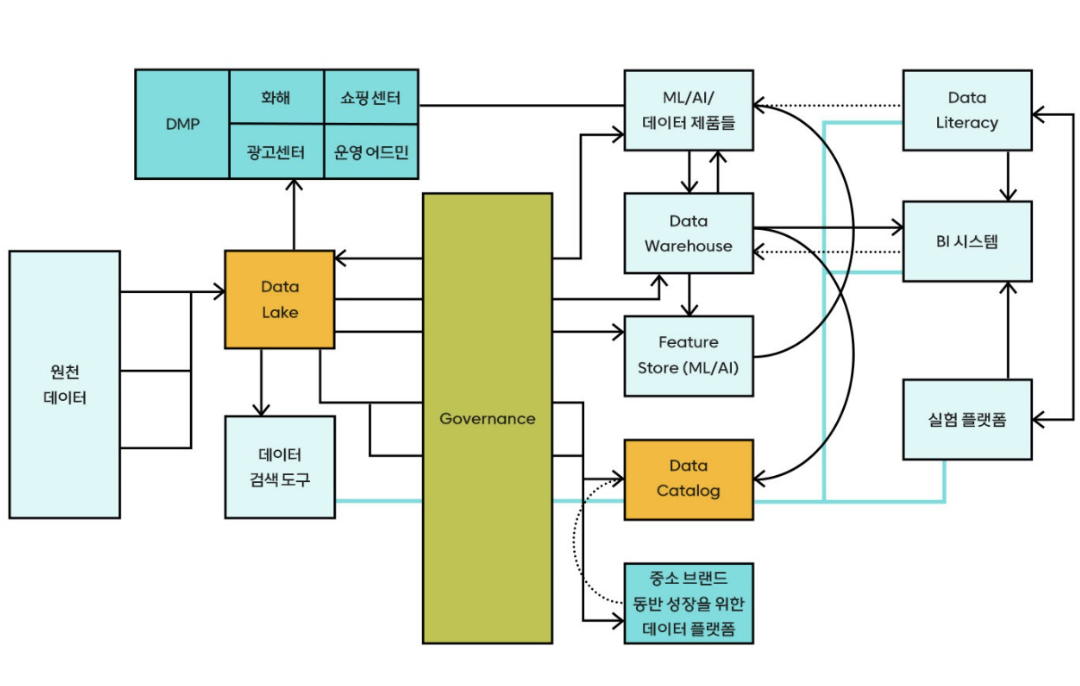
- 데이터 플랫폼
- 데이터 레이크 (모든 원천데이터 적재)
- 데이터 웨어하우스 (신속 정확하게 데이터 추출 가능하도록 구조화)
- 데이터 카달로그 (레이크/웨어하우스 내에 어떤 데이터가 있는지 쉽게 확인 가능)
- 데이터 분석가 (Data Scientist)
결론
- 단순히 데이터를 보여주는 것만으로 문제 해결력 상승 X
- 데이터를 바라보는 올바른 관점 형성이 가장 중요
- 그 관점을 유지 및 강화 위한 환경 필요
[인사이트]
너무 많은 데이터를 보고자 하지만 문제와 관련없는 데이터는 쓸모가 없는 말에 공감했다. 특히 웬만한 정보는 다 모으는 성향이라, 졸업 논문을 작성할 때 쓸모없는 자료를 찾느라 시간만 허비하고 결국 활용은 하나도 못한 적이 있었다. 삼일 동안 진행된 아티클 스터디에서 똑같이 강조되는 내용이지만, 그만큼 중요한 내용이고 또 간과하기 쉬운 부분이라고 생각한다. 데이터를 문제를 잘 정의하고 해결하는 데이터 리터러시는 데이터 분석가 뿐만 아니라 모든 직무의 사람들이 알고 실천해야하는 내용이라고 느꼈다.
2. 그 데이터는 잘못 해석되었습니다
[주제]
잘못 해석된 데이터 유형 및 제대로 해석하는 방법
[아티클 요약]
- 잘못 해석된 데이터 유형
- 생존자 편향의 오류
- 이탈자를 대상으로 했기 때문에 발생
- 잘못된 지표 설정과 잘못된 해석
- 고치기 위해선 전체 대상자를 기준으로 잡아야 함
- 심슨의 역설
- 전체 지표와 그룹을 나눈 지표의 방향성이 다르게 나타남
- 집단 수 비율의 차로 인해 발생
- 집단을 나눈 지표 확인 필요
- 상관관계를 통한 성급한 일반화
- 비슷해 보이는 패턴을 쉽게 일반화하려는 경향
- 상관성은 있으나 인과성 없는 경우, 제 3의 공통 원인 존재할 수 있음
- 방지하기 위한 방법
- 사용자의 행동과 심리 인지적으로 구조화
- 두 지표에 동시에 영향을 줄 공통 원인 확인
- 새로운 구조로 지표 간 관계 파악 필요
- 목적에 맞지 않는 지표 선택
- 같은 목적이 있더라도, 정확히 어떤 관점에서 개선할지 명확한 방식 필요.
- CTA 버튼 개선이라는 같은 목적으로도 다양한 지표 선택 가능함
- 유저 수 → 단순 클릭수 로만 변경해도 다른 방법이 나옴
- 생존자 편향의 오류
- 세이건 표준 참고
- ‘특별한 주장에는 특별한 근거가 필요하다’
- 데이터는 가공 기준 및 방법에 따라 바뀔수도 있으며, 해석하는 사람의 생각이 반영되기도 함
- 충분한 근거를 파악했는지, 잘못 해석했을 가능성은 없는지 파악하려고 노력해야 함
[인사이트]
데이터를 해석하는 중 발생하는 실수를 다양한 유형으로 구분지어서 이해하기 편했다. 대학 생활을 돌아보면 나도 인지하지 못하게 다양한 오류를 범했다는 것을 느꼈다. 특히 같은 목적이라도 관점에 따라 선택할 수 있는 지표와 방식이 다를 수 있다는 사실이 흥미로웠다. 협업 시 의사소통이 제대로 이루어지지 않는다면 같은 목적으로 분석하는 것처럼 보이지만 내부적으로 혼란이 생길 수도 있겠다는 생각이 들었다. 팀원 간 의사소통과 목적의 명확한 설정이 반드시 필요한 것 같다.
또한 특별한 주장에는 특별한 근거가 필요하다는 세이건 표준이 인상깊었다. 사실 데이터 분석을 통해 혁신적인 해결책을 제시하고 싶은 마음은 나 뿐만 아니라 데이터를 공부하는 많은 사람들이 가지고 있다고 생각한다. 욕심에 앞서 잘못 해석한 데이터로 특별한 주장을 하는 오류를 범하지 말고 충분한 근거를 기반으로 주장하는 것의 중요성을 다시금 느끼게 되었다.
SQL
숫자 연산
- 기본 사칙 연산 : +, -, *, /
- 합계 : SUM(컬럼)
- 평균 : AVG(컬럼)
- 최솟값 : MIN(컬럼)
- 최댓값 : MAX(컬럼)
- 데이터 갯수 : COUNT(컬럼)
[컬럼명 대신 1, * 사용 가능]
실습 문제
1) 주문 금액이 30,000원 이상인 주문건의 갯수 구하기
SELECT COUNT(price) AS high_price
FROM food_orders
WHERE price >= 30000;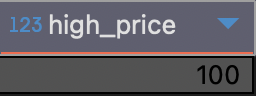
어차피 주문건의 개수를 구하는 거니까,
COUNT(price) 말고 COUNT(1)을 해도 된다.
2) 한국 음식의 주문 당 평균 음식가격 구하기
# 가격의 평균
SELECT AVG(price) AS korean_avg_price
FROM food_orders
# 한국 음식만 필터링
WHERE cuisine_type = 'Korean';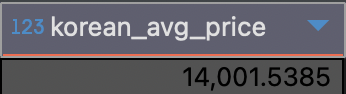
범주별 연산 GROUP BY
where 절을 사용해서 수십개의 쿼리를 작성하는 것은 너무 비효율적
카테고리별로 지정하여 연산 가능
SELECT 카테고리컬럼(원하는컬럼 아무거나), sum(계산 컬럼), FROM GROUP BY 카테고리컬럼(원하는컬럼 아무거나)
실습 문제
1) 음식점별 주문 금액 최댓값 조회하기
SELECT restaurant_name,
#최댓값 연산
MAX(price) AS max_pirce
FROM food_orders
#음식점 이름으로 카테고리 지정
GROUP BY restaurant_name;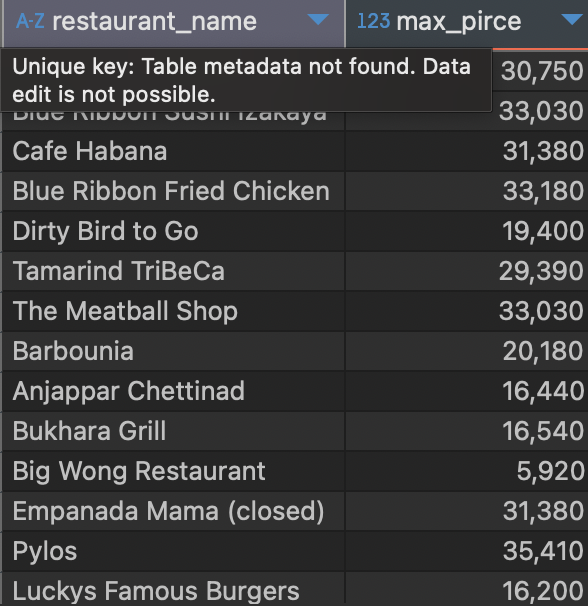
2) 결제 타입별 가장 최근 결제일 조회하기
SELECT pay_type,
#최근 결제일 지정
MAX(date) AS "최근 결제일"
FROM payments
#결제 타입으로 카테고리 지정
GROUP BY pay_type;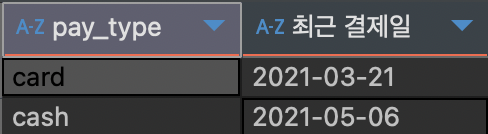
정렬문 ORDER BY
계산 결과를 오름차순 혹은 내림 차순으로 정리
select 카테고리컬럼(원하는컬럼 아무거나), sum(계산 컬럼), from group by 카테고리컬럼(원하는컬럼 아무거나) order by 정렬을 원하는 컬럼 (카테고리컬럼(원하는컬럼 아무거나), sum(계산 컬럼) 둘 다 가능)
오름차순 : ORDER BY 컬럼
내림차순 : ORDER BY 컬럼 DESC
실습문제
1) 음식점별 주문 금액 최댓값 조회하기 - 최댓값 기준으로 내림차순 정렬
SELECT restaurant_name,
MAX(price) max_price
FROM food_orders
# GROUP BY 에서는 별명을 사용할 수 없지만
GROUP BY restaurant_name
# ORDER BY에서는 별명을 사용할 수 있다
ORDER BY max_price DESC;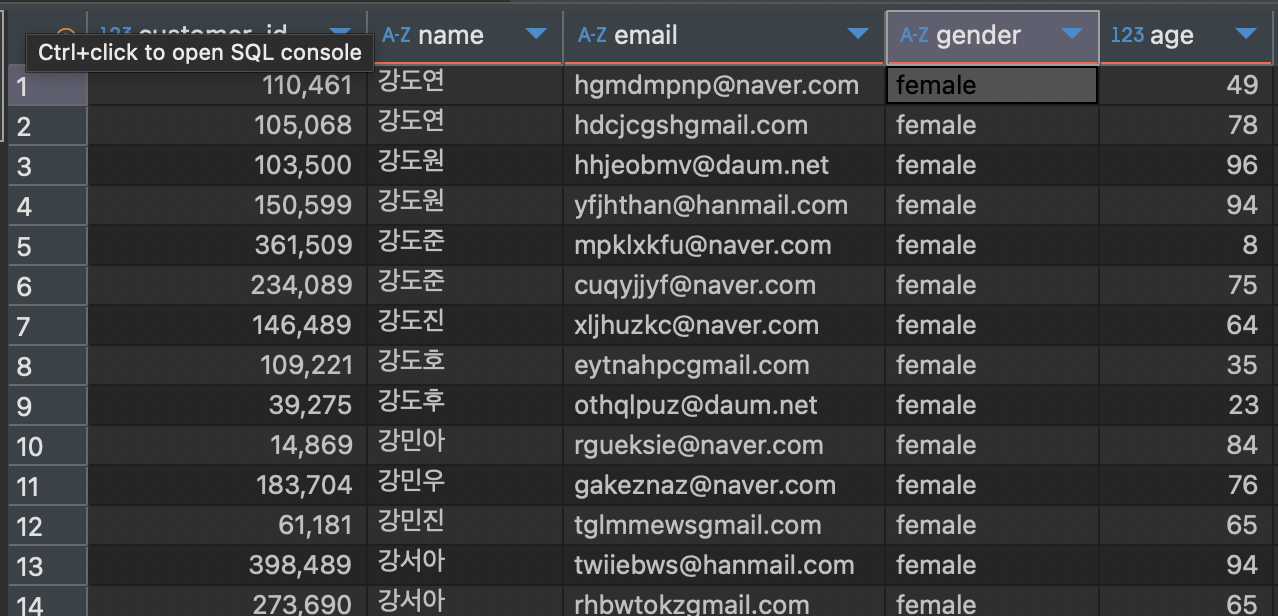
2) 고객을 이름 순으로 오름차순으로 정렬하기
#주어진 조건이 없으므로 테이블 전체를 출력
SELECT *
FROM customers
ORDER BY name;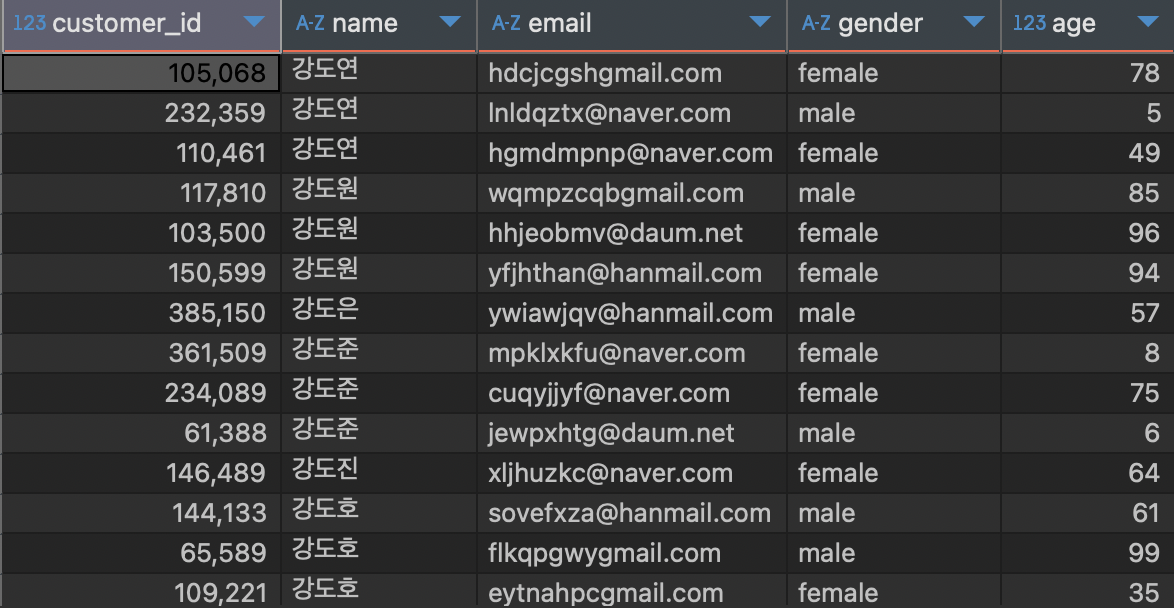
- 정렬 기능을 두 번 이상 사용하면, 앞에 있는 컬럼 순으로 정렬된다.
#주어진 조건이 없으므로 테이블 전체를 출력
SELECT *
FROM customers
ORDER BY gender,name;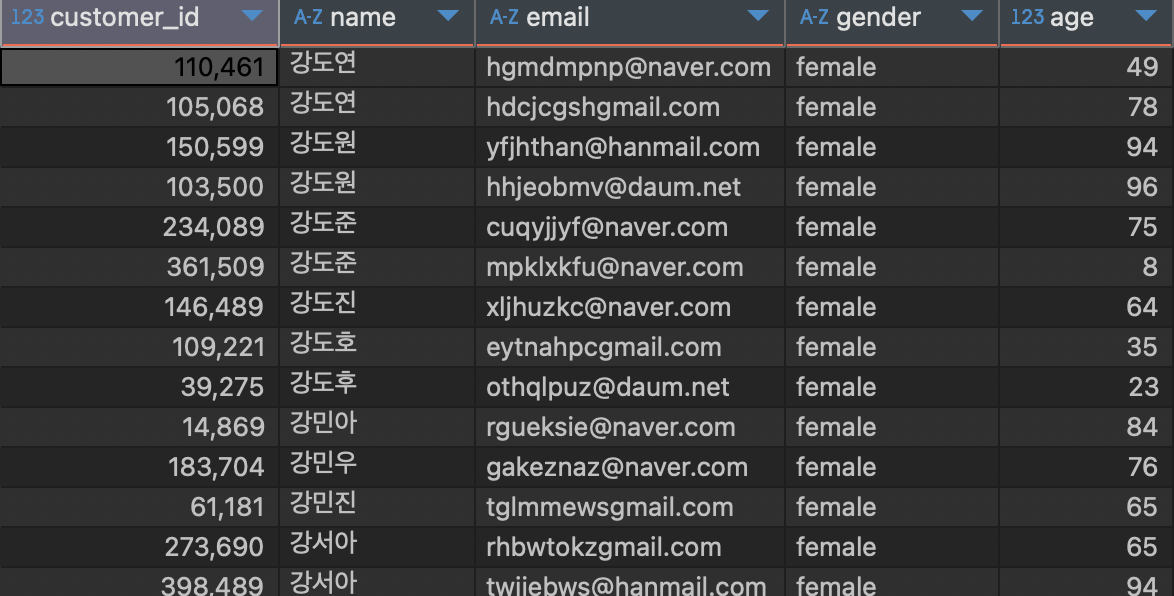
느낀점
아티클 두개를 해서 공부를 많이 못한 것 같지만, 그래도 SQL의 기초적 형식은 익혔다. 내일은 문제를 많이 풀면서 익숙해져야겠다. 별로 하는게 없는 것 같은데 4시간이 금방 지나간다. 문제 풀기만 하고 넘어가지 말고, 각주 잘 활용해서 기록하자. 안중요해 보여도 궁금한건 챗GPT한테 꼭 물어보자.
