아티클 스터디
SQL 가독성을 높이는 다섯가지 습관
[주제]
SQL 가독성을 높이는 방법
[아티클 요약]
- SQL은 들여쓰기, 띄어쓰기 규칙이 거의 없음
- 자유롭지만 가독성이 떨어지는 경우 많음
- 가독성있는 SQL 코드를 쓰는 5가지 방법
- 예약어는 대문자로 쓴다
- SELECT, FROM, GROUP BY, WHERE 등 대문자로 작성
- 행갈이를 자주 한다
- 작성자의 의도와 코드 구조를 쉽게 파악할 수 있음
- 행갈이를 더! 자주 하자
- 주석 처리를 통해 조건을 편하게 넣었다 뺐다 효율적으로 작성 가능!
- 주석을 쓰자
- 코드를 쓴 의도를 짧게 적어 놓는 습관
- 조건의 필요성, 어떻게 동작하는지 등
- 코드 이해가 수월해짐
- Alias (별명설정)을 잘 하자
- 나중에 다시 코드를 볼 때, 처음부터 다 봐야하는 경우 생김
- 예약어는 대문자로 쓴다
- 가장 중요한 것은 합의된 규칙
- 팀에서 사용하고 있는 규칙을 따라야 팀 간 협업이 용이해짐
- 누군가 나의 코드를 본다고 생각하면서 작성하고 정리하는 것이 필요
[인사이트]
SQL 을 공부하면서 스스로 경험했던 부분이라 굉장히 인상깊었다. 공부를 하면서 챗GPT를 통해 모르는 부분을 물어보는데 GPT가 코드를 아티클과 같은 방식으로 작성해서 설명했다. 그 부분에 대해 질문했더니 아티클과 같은 내용을 말해준 적이 있었다. 아티클을 보면서 지금 하고 있는 방식이 맞다는 생각이 들어 좋았다. 그만큼 SQL의 가독성을 높이는 방식이 중요하고 의식하지 않고 쓸 만큼 체화하는 것이 중요한 것 같다. 또한 누군가 나의 코드를 본다고 생각하면서 작성하고 정리하는 것이 정말 도움이 될 것 같다고 생각했다. 그런만큼 velog를 잘 활용해서 공부한 내용을 더 잘 정리하는 습관을 들이고 싶다. 마지막으로 캠프에서 같은 내용을 함께 공부하는 만큼 서로의 블로그를 참고하면서 공부하면 훨씬 좋을 것 같다!
SQL
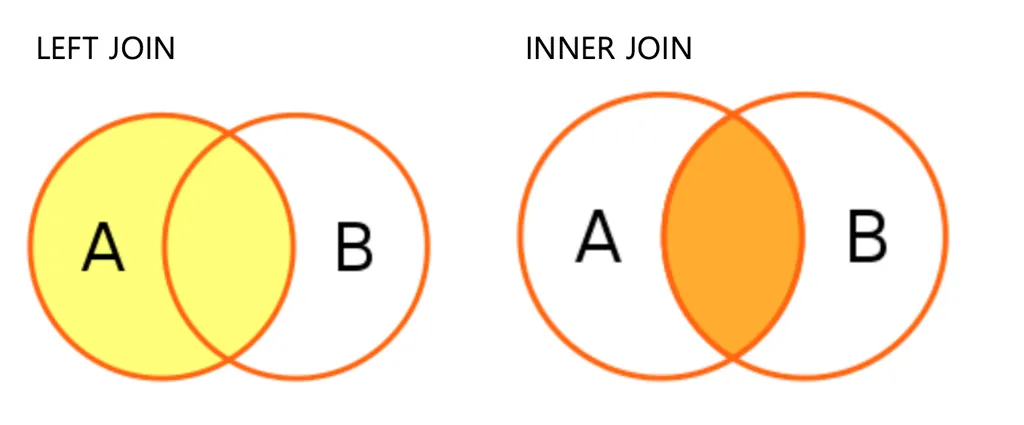
서로 다른 테이블에 있는 데이터 조회 JOIN
필요한 데이터가 여러 테이블에 존재하는 경우
여러 테이블에서 데이터를 불러오는 방법
기본적으로 vlookup과 유사함!
기본구조
-- LEFT JOIN : 공통컬럼 (키값)을 기준으로, 하나의 테이블에 값이 없더라도 조회 SELECT 조회 할 컬럼 FROM 테이블1 a LEFT JOIN 테이블2 b ON a.공통컬럼명 = b.공통컬럼명; -- INNER JOIN : 두 테이블에 모두 있는 값만 조회 SELECT 조회 할 컬럼 FROM 테이블1 a INNER JOIN 테이블2 b -- 공통컬럼은 묶어주기 위한 값만 같으면 됨. --공통컬럼명은 달라도 괜찮다! ON a.공통컬럼명=b.공통컬럼명;
[실습] JOIN 을 이용하여 두 개의 테이블에서 데이터를 조회해보기
주문 테이블과 고객 테이블을 cusomerid 를 기준으로 left join 으로 묶어보기
조회 컬럼 : orderid, customer_id, restaurant_name, price, name, age, gender
SELECT
# 각 테이블에서 원하는 컬럼 선택.
fo.order_id
, fo.customer_id
, fo.restaurant_name
, fo.price
, c.name
, c.age
, c.gender
FROM
food_orders fo
LEFT JOIN customers c
ON fo.customer_id = c.customer_id;JOIN의 단계
먼저 각각의 테이블을 전체 조회하여 어떤 컬럼이 있는지 확인!
-> JOIN 할 수 있는 공통컬럼 확인 후 작성
-> 원하는 컬럼 선택
실습 문제
1) 한국 음식의 주문별 결제 수단과 수수료율을 조회하기
조회 컬럼 : 주문 번호, 식당 이름, 주문 가격, 결제 수단, 수수료율
결제 정보가 없는 경우도 포함하여 조회
SELECT
fo.order_id
, fo.restaurant_name
, fo.price
, p.pay_type
, p.vat
FROM food_orders fo
LEFT JOIN payments p
ON fo.order_id = p.order_id
# 한국 음식만 필터링
WHERE fo.cuisine_type = 'Korean';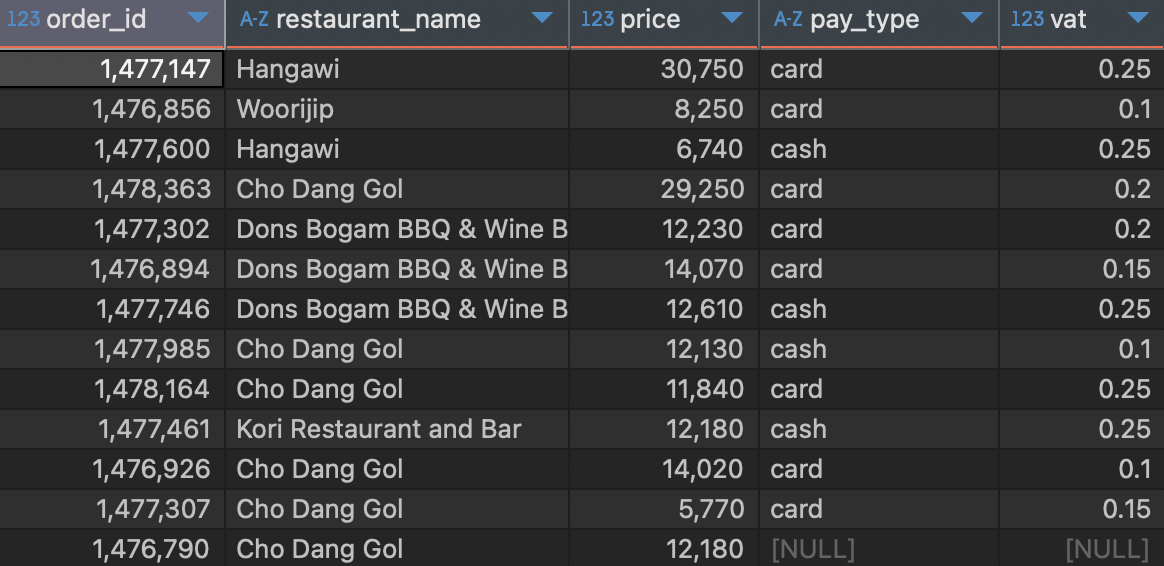
2) 고객의 주문 식당 조회하기
조회 컬럼 : 고객 이름, 연령, 성별, 주문 식당
고객명으로 정렬, 중복 없도록 조회
SELECT
# DISTINCT 는 SELECT 바로 뒤에서만 사용 가능!
DISTINCT
c.name
, c.age
, c.gender
, fo.restaurant_name
FROM customers c
LEFT JOIN food_orders fo
ON c.customer_id = fo.customer_id
# 고객명으로 정렬, 1로 표현도 가능
ORDER BY c.name ;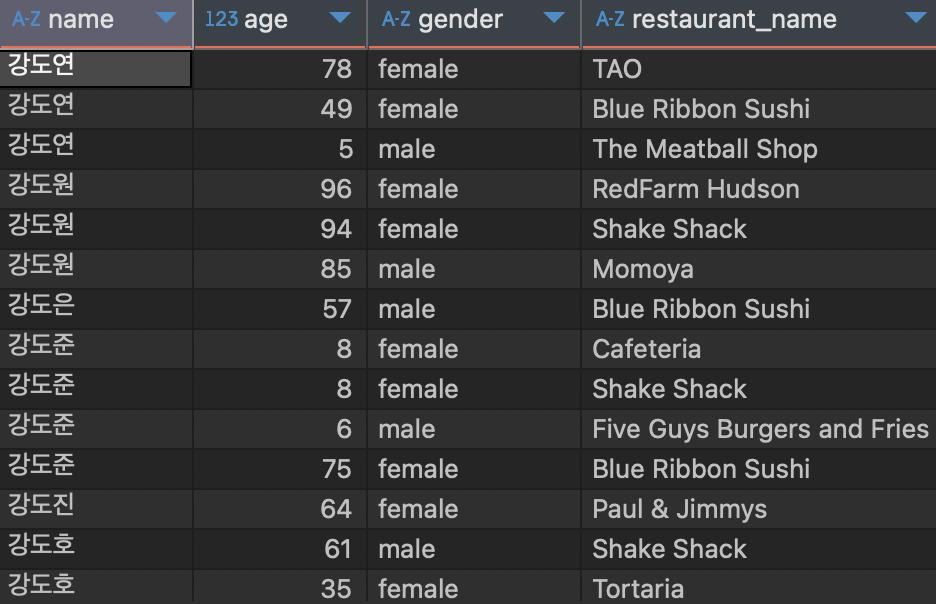
DISTINCT는 SELECT 뒤에만 사용할 수 있으며, 결과 집합 전체에 대해 중복을 제거한다.
특정 컬럼만 중복을 제거하려면 GROUP BY, 서브쿼리, 또는 윈도우 함수를 활용해야 한다.
나중에 쓸 일이 생기면 윈도우 함수에 대해 찾아봐야겠다.
3) 주문 가격과 수수료율을 곱하여 주문별 수수료 구하기
조회 컬럼 : 주문 번호, 식당 이름, 주문 가격, 수수료율, 수수료
수수료율이 있는 경우만 조회
SELECT
fo.order_id
, fo.restaurant_name
, fo.price
, p.vat
# 가격*수수료율 = 수수료 컬럼 생성
, fo.price * p.vat `수수료`
FROM food_orders fo
#수수료율이 있는 컬럼만 조회하기 위해 INNER JOIN 사용
INNER JOIN payments p
ON fo.order_id = p.order_id;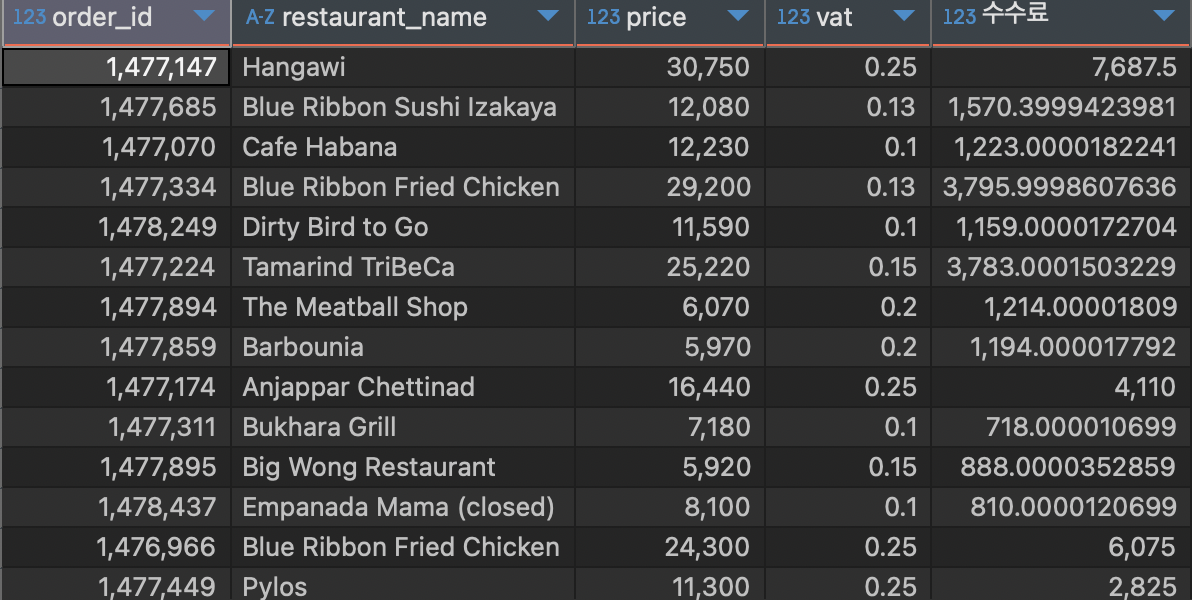
4) - 50세 이상 고객의 연령에 따라 경로 할인율을 적용하고, 음식 타입별로 원래 가격과 할인 적용 가격 합을 구하기
조회 컬럼 : 음식 타입, 원래 가격, 할인 적용 가격, 할인 가격
고객 정보가 없는 경우도 포함하여 조회, 할인 금액이 큰 순서대로 정렬
할인 : (나이-50)*0.005
솔직히 문제에서 제시한 말이 헷갈려서 시간 버린게 한두번이 아니라서 짜증난다...
답지엔 최종 컬럼이 세개인데 조회 컬럼에 컬럼이 왜 네개 들어있는걸까?
할인 적용 가격이랑 할인 가격은 왜 구분해놓은건지를 모르겠다.
그리고 처음엔 원래 가격 + 할인 적용 가격 하라는 줄 알았다.
문제를 명확히 이해되게 써주면 좋겠다.
앞으로 이해 안되면 그냥 강의 들어야겠다.
SELECT
cuisine_type
# 전체 금액의 총 합
, SUM(price) sum_price
# 할인된 금액의 총 합
, SUM(discount_price) sum_discount_price
FROM
( #서브쿼리에서 JOIN 사용해서 할인된 금액 구함
SELECT
fo.cuisine_type
, fo.price
, fo.price*(c.age-50)*0.005 discount_price
FROM
food_orders fo
LEFT JOIN customers c
ON fo.customer_id = c.customer_id
WHERE c.age > 50
) discount
# 음식 타입 별로 계산
GROUP BY 1
# 총 할인된 금액이 큰 순으로 정렬 (원래 가격 합 - 할인된 금액 합)
ORDER BY sum_discount_price DESC;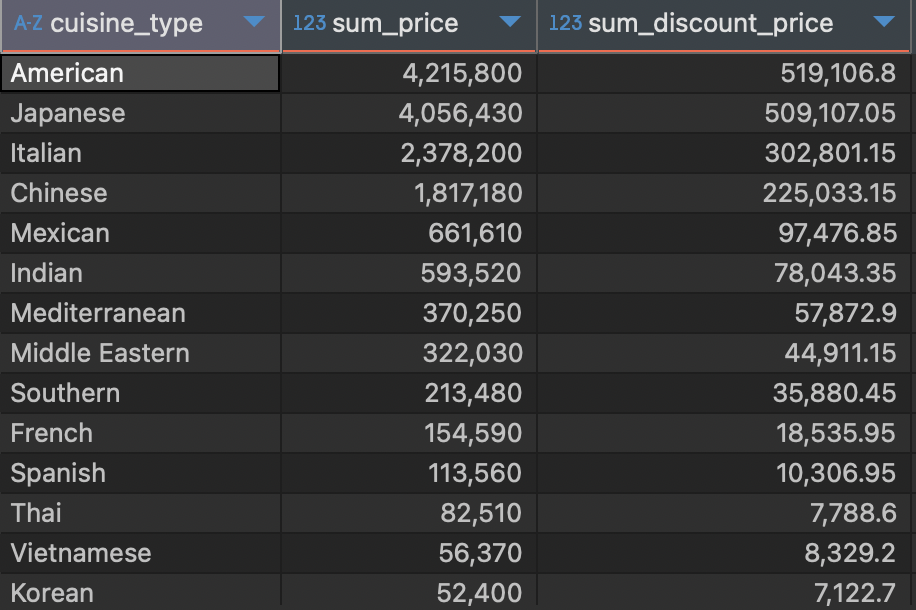
4주차 과제
평균 음식 주문 금액 기준 : 5,000 이하 / ~10,000 / ~30,000 / 30,000 초과
평균 연령 : ~ 20대 / 30대 / 40대 / 50대 이상
두 테이블 모두에 데이터가 있는 경우만 조회, 식당 이름 순으로 오름차순 정렬
SELECT
restaurant_name
# 기준 별 CASE 구분
, CASE
WHEN avg_price <= 5000 THEN 'price_group_1'
WHEN avg_price BETWEEN 5001 AND 10000 THEN 'price_group_2'
WHEN avg_price BETWEEN 10001 AND 30000 THEN 'price_group_3'
WHEN avg_price > 30000 THEN 'price_group_4'
END price_group
, CASE
WHEN avg_age < 30 THEN 'age_group_1'
WHEN avg_age BETWEEN 30 AND 39 THEN 'age_group_2'
WHEN avg_age BETWEEN 40 AND 49 THEN 'age_group_3'
WHEN avg_age >= 50 THEN 'age_group_4'
END age_group
FROM
(# 서브쿼리 : 평균 금액 및 평균 연령 계산
SELECT
fo.restaurant_name
, AVG(fo.price) avg_price
, AVG(c.age) avg_age
FROM food_orders fo
INNER JOIN customers c
ON fo.customer_id = c.customer_id
# 식당 이름 별로 계산
GROUP BY 1
) Average
# 식당 이름 순으로 오름차순 정렬
ORDER BY 1;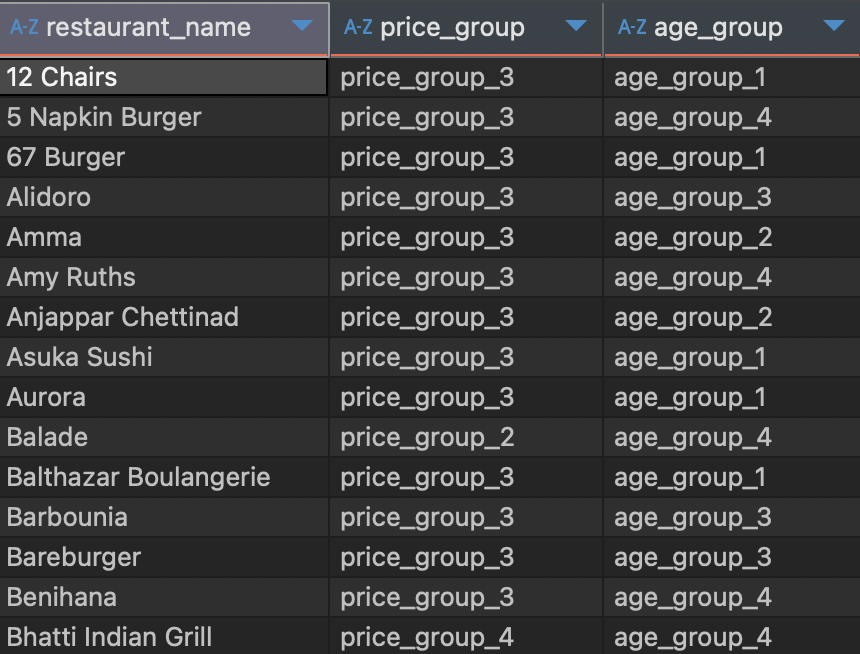
느낀점
5문제 푸니까 3시간이 지나갔다. 이번주까지 SQL 강의 다 끝내고 다음주에 파이썬 들어가면서 문제 풀이 위주로 공부해야지.서브컬럼에 이름 꼭 붙이기 까먹는 것 같은 기본적인 실수를 줄여야 한다. 하루하루가 정말 빠르다.
