아티클 스터디
데이터 분석으로 유저의 마음을 읽는 서비스가 되려면
[주제]
- '리디'에서 데이터를 활용하는 방법
[아티클 요약]
- 데이터와 직관을 동시에 활용하는 의사결정 원칙 존재
- 데이터는 가설을 검증하는 도구
- 직관은 가설을 세우기 위한 도구
- 데이터 리터러시 : 데이터를 직관적으로 해석하고 가설을 세우는 능력
- 산업 동향에 대한 이해
- 고객의 직접적인 피드백 (cs 학습)
- 데이터 활용을 위해서는 프로젝트 환경을 둘러싼 맥락 이해 필수
- 커뮤니케이션 : 데이터 기반 의사결정의 핵심
- 데이터를 근거로 타인을 설득하고 의사결정 이끌어내는 능력
- 데이터 시각화 : 커뮤니케이션 skill
- 직관적이고 단순명료하게 전달
- 파이썬(Python), 태블로(Tableau), 리대시(Redash) 등의 시각화 도구로 대시보드 생성
- 동료에 대한 신뢰 : 함께 성장하며 팀워크 쌓기
- 직관적 데이터 분석이 고객에게 되돌려주는 가치
- 고객은 데이터 분석에 대해 직접적으로 느끼지 못함
- 이면에 존재하는 데이터 기반의 고민과 치밀한 설계 존재
- 직관적 데이터 활용을 통해 유저가 신뢰하는 콘텐츠 플랫폼으로 성장
[인사이트]
직관을 활용한 데이터 분석이라는 말이 처음에는 약간 모순적으로 보였다. 그러나 아티클에서 프로젝트의 의도와 목적, 산업 동향에 대한 이해를 통해 직관을 발달시키고 가설을 수립한다는 내용을 보고 직관의 의미를 이해할 수 있었다. 결국 소비자들의 요구를 파악하고 프로젝트의 방향을 설정하는 것을 직관이라고 단순하게 표현한 것 같다. 결국 데이터 분석에 초점을 두는 것이 아닌, 데이터를 활용하는 방법을 고민하는 것이 고객이 원하는 서비스를 제공하는 비결이라는 점이 인상깊었다. 아티클을 읽고 난 후, 리디처럼 콘텐츠를 제공하는 플랫폼이 아닌 다른 도메인이나 산업에서 진행되는 데이터 분석엔 어떤 차이점이 있을지 궁금해졌다.
SQL
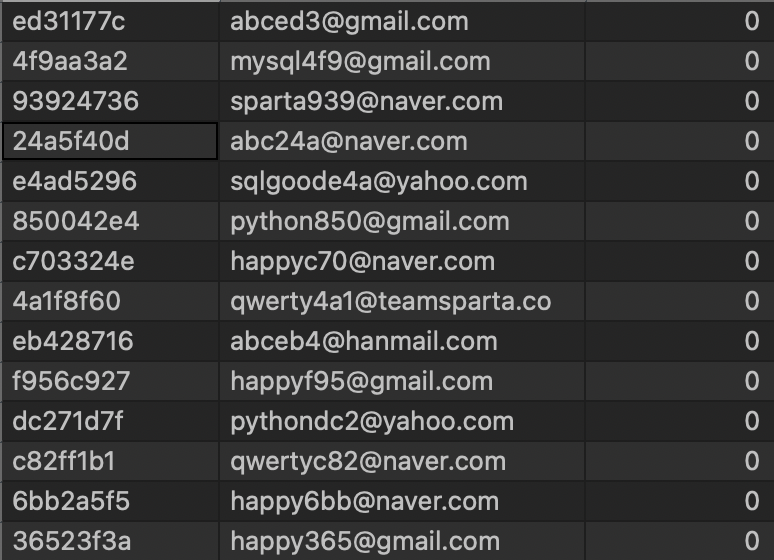
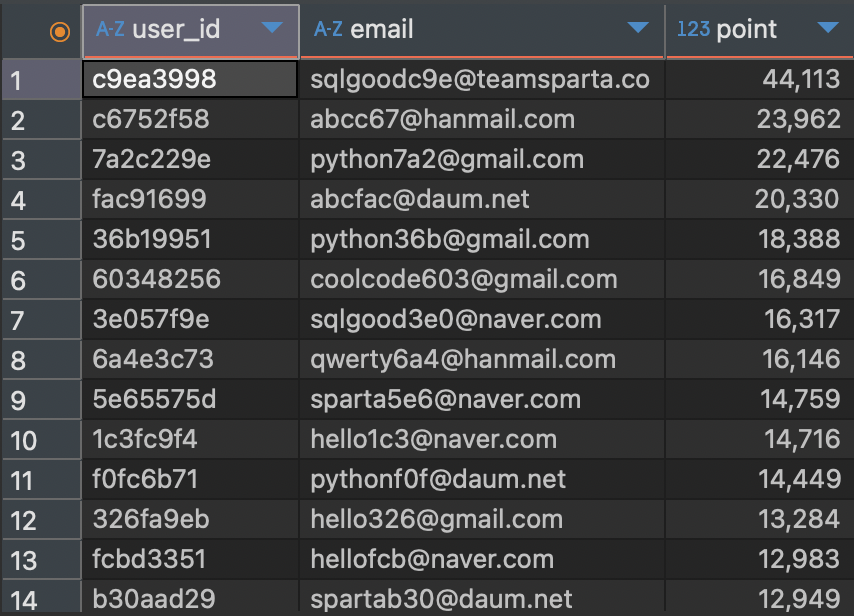
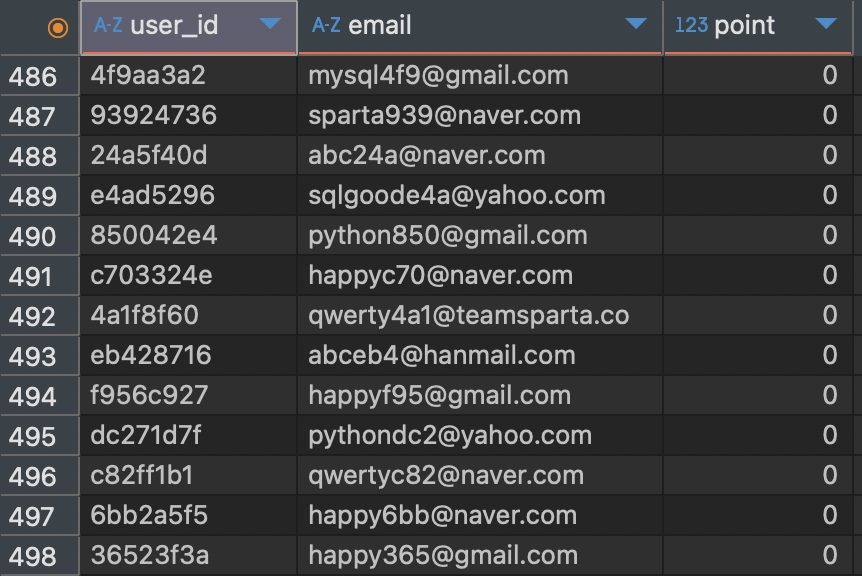
SQL 실전 Lv3. 이용자의 포인트 조회하기
- 다음과 같은 결과 테이블을 만들어봅시다.
- user_id: 익명화된 유저들의 아이디
- email: 유저들의 이메일
- point: 유저가 획득한 포인트
- users 테이블에는 있지만 point_users에는 없는 user는 포인트가 없으므로 0 으로 처리
- 포인트 기준으로 내림차순 정렬
SELECT
u.user_id
, u.email
-- COALESCE NULL값이 있을 경우 대체값 생성
, COALESCE(pu.point, 0) point
FROM users u
LEFT JOIN point_users pu
ON u.user_id = pu.user_id
ORDER BY pu.point DESC;
# COALESCE 를 IF문으로 대체
, IF(pu.point IS NULL, 0, pu.point) point윗부분
아래부분
SQL 실전 Lv4. 단골 고객님 찾기
문제:
Orders 테이블:
| OrderID | CustomerID | OrderDate | TotalAmount |
|---|---|---|---|
| 101 | 1 | 2024-01-01 | 150 |
| 102 | 2 | 2024-01-03 | 200 |
| 103 | 1 | 2024-01-04 | 300 |
| 104 | 3 | 2024-01-04 | 50 |
| 105 | 2 | 2024-01-05 | 80 |
| 106 | 4 | 2024-01-06 | 400 |
Customers 테이블:
| CustomerID | CustomerName | Country |
|---|---|---|
| 1 | Alice | USA |
| 2 | Bob | UK |
| 3 | Charlie | USA |
| 4 | David | Canada |
요구사항:
-
고객별로 주문 건수와 총 주문 금액을 조회하는 SQL 쿼리를 작성해주세요.
- 출력 결과에는 고객 이름, 주문 건수, 총 주문 금액이 포함되어야 합니다. 단, 주문을 한 적이 없는 고객도 결과에 포함되어야 합니다.
-
나라별로 총 주문 금액이 가장 높은 고객의 이름과 그 고객의 총 주문 금액을 조회하는 SQL 쿼리를 작성해주세요.
제약사항:
- 두 쿼리 모두 서브쿼리,
JOIN,GROUP BY,HAVING등을 사용해 풀 수 있어야 한다. - 주문을 한 적이 없는 고객도 첫 번째 쿼리 결과에 포함되어야 한다.
# 1. 고객 별로 주문 건수와 총 주문 금액 조회
SELECT
c.CustomerName
, COUNT(o.OrderID) count_order -- 주문 건수
, COALESCE(SUM(o.TotalAmount), 0) total_amount -- 총 주문 금액
FROM Customers c
LEFT JOIN `orders` o
ON c.CustomerID = o.CustomerID
GROUP BY 1;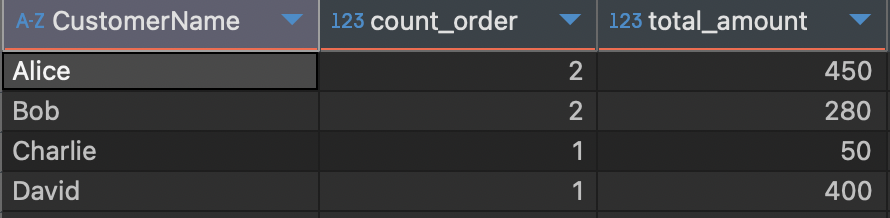
# 2. 나라별로 총 주문 금액이 가장 높은 고객의 이름과 그 고객의 총 주문 금액을 조회
~~~sql
SELECT
c.Country,
c.CustomerName,
SUM(o.TotalAmount) AS TotalSpent -- 국가별로 고객들을 그룹화하여 각 고객의 총 지출 금액을 계산
FROM
Customers c
JOIN
Orders o ON c.CustomerID = o.CustomerID
GROUP BY
c.Country, c.CustomerName
HAVING -- 각 국가별로 가장 많이 지출한 고객을 선택하는 역할
-- 각 고객의 총 지출 금액 값이
-- 서브쿼리에서 구한 해당 국가의 **MAX(SumSpent)와 일치하는 고객만 선택
SUM(o.TotalAmount) = (
SELECT
MAX(SumSpent) -- 그 중에서 가장 큰 금액을 계산
FROM
# 서브쿼리는 각 국가별로 고객들의 총 지출 금액을 구함
(SELECT
SUM(o2.TotalAmount) AS SumSpent
FROM
Customers c2
JOIN
Orders o2 ON c2.CustomerID = o2.CustomerID
WHERE
-- 조건은 주 쿼리에서 선택된 국가들 중에서만 서브쿼리가 최대 지출 금액을 구하도록 제한을 주는 역할
c2.Country = c.Country -- 여기서 c.Country가 주 쿼리의 컬럼!
GROUP BY
c2.CustomerID-- SELECT에 없어도 그룹화할 다른 컬럼을 GROUP BY에 포함할 수 있음!
) AS Sub_q
);처음엔 간단해 보였는데... 진짜 어렵고 이해가 잘 안된다.
그렇게 복잡하진 않은데 뭔가 개념이 꼬이는 기분.
개념 혼란스럽지 않게 잘 정리하자.
해설
1 주 쿼리 (기본 쿼리):
- JOIN을 사용하여 Customers 테이블과 Orders 테이블을 CustomerID 기준으로 결합합니다.
- GROUP BY c.Country, c.CustomerName:
- 이 부분은 국가별, 고객별로 데이터를 그룹화합니다. 즉, 각 국가 내에서 각 고객의 총 지출 금액을 계산합니다.
- 예를 들어, USA에서 Alice는 450을 지출하고, Charlie는 50을 지출했다고 하면, Alice와 Charlie가 각각 USA 내에서 고객별로 그룹화됩니다.
- SUM(o.TotalAmount)는 각 그룹 내에서 고객별 총 지출 금액을 계산합니다.
- 서브쿼리:
서브쿼리는 각 국가별로 고객들의 총 지출 금액 중 가장 큰 금액을 찾습니다.
- 서브쿼리 내에서 SUM(o2.TotalAmount)는 각 고객별 총 지출 금액을 계산하고, 그 중에서 최댓값 (MAX(SumSpent))을 구합니다.
- 예를 들어, USA에서 Alice는 450을 지출하고, Charlie는 50을 지출한다고 할 때, MAX(SumSpent)는 450 (Alice)이 됩니다.
- c2.Country = c.Country는 현재 주 쿼리에서 선택된 국가에 대해만 서브쿼리가 실행되도록 보장합니다. 이 조건 덕분에 서브쿼리는 각 국가에 해당하는 고객들의 최대 지출 금액을 구합니다.
- HAVING 절: HAVING 절은 그룹화된 데이터에 조건을 걸어주는 부분입니다.
- HAVING SUM(o.TotalAmount) = ...는 주 쿼리에서 각 국가별 고객들의 지출 금액이 서브쿼리에서 구한 해당 국가의 최대 지출 금액과 일치하는 고객만 선택하는 조건을 추가합니다.
- 즉, SUM(o.TotalAmount)가 서브쿼리에서 계산된 MAX(SumSpent)와 일치하는 고객만 결과로 반환됩니다. 이 조건 덕분에 각 국가에서 가장 많이 지출한 고객만 선택됩니다.
- 결과:
USA에서 Alice는 450을 지출하고, Charlie는 50을 지출합니다. MAX(SumSpent) = 450이므로, Alice만 결과에 포함됩니다.
UK에서 Bob은 280을 지출하므로, Bob만 결과에 포함됩니다.
Canada에서 David는 400을 지출하므로, David만 결과에 포함됩니다.
최종 결과:
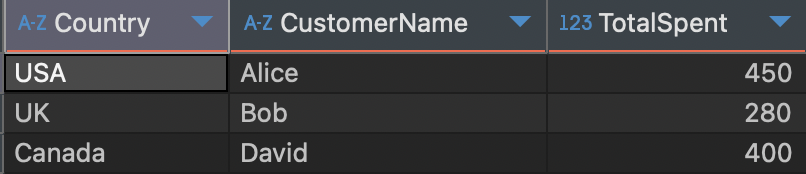
핵심 포인트:
GROUP BY: 데이터를 국가별, 고객별로 그룹화하여 각 고객의 총 지출 금액을 계산합니다.
서브쿼리: 각 국가에 대해 고객들의 총 지출 금액 중 가장 큰 값을 찾습니다.
HAVING: SUM(o.TotalAmount)가 서브쿼리에서 계산된 최대 금액과 일치하는 고객만 선택하여 각 국가별로 가장 많이 지출한 고객만을 반환합니다.
주쿼리에서 서브쿼리 참조가 가능한 이유
실제로 SQL 쿼리는 서브쿼리를 먼저 실행하고 그 결과를 주 쿼리에서 사용할 수 있습니다. 하지만 이때 중요한 점은 서브쿼리가 주 쿼리의 "문맥"을 이해할 수 있다는 점입니다.
서브쿼리는 주 쿼리의 컬럼을 참조할 수 있기 때문에, 주 쿼리에서 처리하는 데이터를 기반으로 서브쿼리가 계산을 진행할 수 있습니다. 즉, 주 쿼리가 실행될 때마다 서브쿼리가 "주 쿼리의 각 행"에 대해 계산을 합니다.
계산 순서와 참조
주 쿼리 실행:
주 쿼리에서 Customers c와 Orders o를 조인하여 데이터를 불러옵니다.
그리고 GROUP BY c.Country, c.CustomerName을 통해 국가별로 고객을 그룹화합니다.
각 고객별로 SUM(o.TotalAmount)를 계산한 후, HAVING 절을 통해 각 국가에서 가장 많이 지출한 고객을 찾아야 합니다.
서브쿼리 실행:
서브쿼리는 주 쿼리의 각 행에 대해 실행됩니다. 즉, 주 쿼리에서 c.Country를 처리하고 있는 각 국가에 대해, 서브쿼리는 그 국가에 해당하는 고객들의 지출 합을 구합니다.
서브쿼리 내의 c.Country = c.Country는, 주 쿼리에서 현재 처리 중인 국가에 대한 조건을 걸기 위해 사용됩니다.
왜 WHERE c2.Country = c.Country가 필요한가?
서브쿼리는 독립적으로 실행되는 것이 아니라, 주 쿼리에서 현재 처리 중인 행을 기준으로 실행됩니다.
c.Country는 주 쿼리에서 현재 처리 중인 국가에 해당하는 값을 가지고 있으므로, 서브쿼리 내에서 그 국가를 필터링해야 각 국가별로 최대 금액을 정확히 계산할 수 있습니다.
계산 흐름 (좀 더 구체적으로):
주 쿼리에서 첫 번째 c.Country 값을 처리합니다. 예를 들어, c.Country가 한국이라고 가정해봅시다.
서브쿼리는 그 국가 (한국)에 해당하는 고객들의 총 지출 금액을 계산합니다. 즉, 서브쿼리는 한국에 대한 계산을 합니다.
그 후, 서브쿼리는 한국에서 고객들이 지출한 최대 금액을 반환하고, 주 쿼리에서 한국에 대해 계산된 최대 금액과 비교합니다.
주 쿼리는 각 국가별로 이 계산을 반복하고, HAVING 절에서 각 국가별로 최대 지출 금액을 넘은 고객만 선택합니다.
HAVING
SQL에서 그룹화된 결과에 조건을 적용할 때 사용하는 절
SELECT column1, column2, aggregate_function(column3) FROM table_name GROUP BY column1, column2 HAVING aggregate_function(column3) condition;
- 주로 GROUP BY와 함께 사용되며, 집계 함수(COUNT(), SUM(), AVG() 등)로 계산된 결과에 조건을 추가할 때 사용
- WHERE은 행 필터링에 사용되고, HAVING은 그룹화된 결과 필터링에 사용
- WHERE 절은 집계 함수와 함께 사용될 수 없음!
느낀점
머리가 안돌아가는건지 내용이 어려운건지는 모르겠지만, 마지막 문제 쿼리 이해가 안되서 시간을 너무 많이 썼다. 언제나 시작하는 것 보다 잘 끝내는 것이 더 어렵다. 내일 달리기반 문제 다 풀고 남은 시간동안 북스터디하면서 사전캠프 잘 마무리했으면 좋겠다. 그리고 본캠프도 잘 시작해야지.
