북스터디

[주제] 데이터 활용 방식에 대한 이해
1. 앞으로 필요한 건 데이터 문해력: 분석보다 활용
- 기계가 할 일과 사람이 할 일
- 기계나 도구로 처리할 수 있는 일들
- 통계 처리
- 분석 이론 및 방법
- 데이터 가공 및 분석 작업
- 중요한 것은 나에게 필요한 기술이 무엇인지 아는 것
- 기계와 도구 조작법을 이해하는 것과는 별개
- 사람이 해야하는 일을 갈고 닦아야 함
- 기계나 도구로 처리할 수 있는 일들
- 통계를 배워도 왜 활용하지 못하나?
- 데이터 활용 과정
-> 분석 전에 문제 및 목적을 정의하고 가설을 구축
-> 분석을 위한 기술과 지식 활용
-> 분석 결과에 대한 해석 및 스토리 구축 - 2번은 기계와 도구가 더 잘하는 부분 (통계 지식이나 분석 방법)
- 1번과 3번을 발전시켜야 함!
- 데이터 활용 과정
- 데이터를 먼저 보지 마라 : 데이터 안에 답은 없다
- 목적 설정이 핵심
- 무엇을 알고 싶은지
- 알면 무엇을 하고 싶은지
- 이를 위해서는 어떤 데이터(지표)가 필요한지
- 자주 겪는 문제점
- 데이터를 적절하게 분석하면 문제와 목적, 결론이 나올 것이라는 착각
- 눈앞에 데이터를 적절히 가공하면 유용한 정보가 나올 것이라는 착각
- 아무것도 나오지 않으면 분석 방법이 문제일 것이라는 생각
- 데이터 분석 자체가 목적이 되어서는 안된다
- 내가 알고 싶은 것에 따라 데이터를 수집하고 분석해야 함
- 데이터 활용 프로세스
- a. 겉으로 드러난 현상
- b. 목적 및 문제 정의
- c. 지표 설정
- d. 현재 상태 파악
- e. 평가
- f. 요인 분석
- g. 해결 방안 모색
- 목적 설정이 핵심
- 올바른 데이터로 올바른 문제를 풀고 있는가?
목적 사고력: 목적에 맞게 문제와 데이터를 연결하기
- 데이터 활용에 실패하는 이유 두가지
1) 풀고자 하는 문제가 명확하지 않다- ‘목적과 문제에 대한 정의’ 선행 필수
- 나는 무엇을 알고 싶은가
- 나는 무엇을 해결하고자 하는가
- point 1 : 구체적이고 명확한 언어 사용
- point 2 : 문제, 원인, 해결방안 구분
- 원인, 문제, 해결방안이 섞여있는 경우 있음
- 편견이 들어가 가설을 원인으로 착각하지 않게 주의
- 결론 도출 프로세스
평가 지표 및 기준 설정 -> 적합한 데이터 및 그래프 선택 -> 결론 - 프레젠테이션 순서
결론 -> 평가 지표 및 기준 설정 -> 적합한 데이터 및 그래프 선택
- ‘목적과 문제에 대한 정의’ 선행 필수
- 비즈니스 현장 사례 분석
- 적절, 개선, 증가 등 모호한 단어 표현 풀어서 정의
[인사이트]
처음부터 내 얘기가 나온 것 같아서 굉장히 찔렸다. 내일 있을 보스턴 집값 데이터 분석을 어떻게 해야할지 고민하다가, 그냥 데이터를 이리저리 가공해보면 뭔가 보이지 않을까라는 생각을 가지고 있었다. 그러나 목적 설정이 선행되지 않으면 우연히 데이터에서 발견한 정보로는 절대로 실제 일어나는 현상을 온전히 설명할 수 없다는 글을 보고 반성을 하게 되었다. 기존 데이터를 통해 알 수 있는 것을 찾아내는 것이 아니라, 내가 알고 싶은 것에 따라 데이터를 수집하고 분석해 결과를 도출하는 것이 의미있는 데이터 분석이라는 것을 명확하게 알 수 있었다.
1장 마지막 부분에서 데이터 활용 프로세스를 제시하고, 그 프로세스대로 책 내용이 전개되는 구조 덕분에 이해하기 편했다. 2장은 b,c 목적/문제 정의에 대한 부분을 다루는데 특히 2.4에서 열가지 비즈니스 현장 사례 분석을 통해 올바른 목적 설정과 데이터 활용에 대해 확실하게 이해할 수 있었다. 오늘은 시간이 없어서 다 읽진 못했지만, 굉장히 도움이 되는 책인 것 같아 빠른 시일내에 따로 시간을 내서 책을 다 읽고 내용을 정리하고 싶다.
SQL
SQL 실전 Lv7. 예산이 가장 큰 프로젝트는?
1. 각 직원이 속한 부서에서 가장 높은 월급을 받는 직원들만 포함된 결과를 조회하는 SQL 쿼리를 작성해주세요.
출력 결과에는 직원의 이름, 부서, 그리고 월급이 포함되어야 합니다.
# 내 쿼리
SELECT
e.Name
, e.Department
, e.Salary
FROM employees e
WHERE e.Salary =
(
SELECT top_Salary
FROM
(
SELECT
MAX(e2.Salary) top_Salary
FROM employees e2
WHERE e2.Department = e.Department
GROUP BY e2.Department
)top
);
# 답안
SELECT
e.Name,
e.Department,
e.Salary
FROM
Employees e
WHERE
e.Salary = (
SELECT
MAX(Salary)
FROM
Employees e2
WHERE
e2.Department = e.Department
);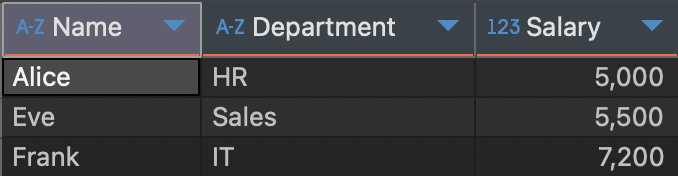
그동안 했던대로 풀었는데, 답을 보니까 이번엔 또 간소화가 가능했다.
간소화 가능한 이유 : MAX(Salary)는 그룹화 없이도 전체에서 최고 월급을 찾을 수 있는 함수이므로, GROUP BY를 사용할 필요가 없다.
한마디로, 계산 함수 없으니까 상관없다는 것. 그 동안의 문제에서는 AVG와 SUM이 있었다. 하던 대로만 하지 말고, 사소한 것까지 고민해보자..!
2. 직원이 참여한 프로젝트 중 예산이 10,000 이상인 프로젝트만을 조회하는 SQL 쿼리를 작성해주세요.
출력 결과에는 직원 이름, 프로젝트 이름, 그리고 프로젝트 예산이 포함되어야 합니다.
SELECT
e.Name
, p.ProjectName
, p.Budget
FROM employees e
JOIN EmployeeProjects ep
ON e.EmployeeID = ep.EmployeeID
JOIN projects p
ON ep.ProjectID = p.ProjectID
WHERE p.Budget >= 10000;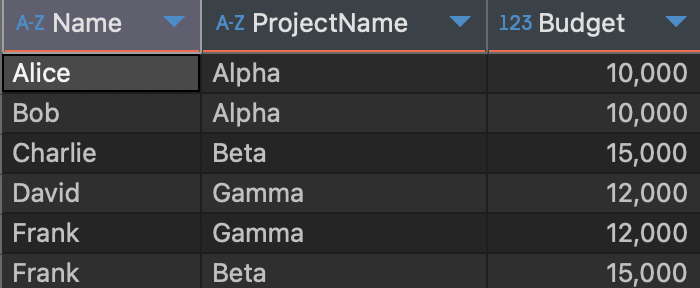
답안이랑 동일하다! 마지막 문제라 쉽게 내주신건지 바로 끝났다.
남은 시간 동안 책을 더 읽어야겠다.
느낀점
오늘로 사전캠프 모든 문제 끝! 목표했던 것들 다 마무리할 수 있어서 뿌듯하다. 사전캠프 첫날에 달리기반 문제 완전 외국어였는데 다 풀다니 감격스럽다 후후. 북스터디를 진행할 때 나를 포함한 팀원들 모두 느낀점이 많으셔서 많이 참고할 수 있어 좋았다. 그동안 진행한 아티클 스터디가 알게 모르게 도움이 많이 되었다. 남은 이틀 동안 데이터 분석 연습을 하면서 실전의 감을 익혀봐야겠다. 책은 최대한 빨리 벨로그에 기록하고 싶은데, hsk 시험 때문에 이번주는 안될 것 같다 ㅜㅜ
